Chunking Documents That Won't Sit Still
A chunk is the unit your system actually retrieves, and the Chunk Boundary Test decides whether it carries enough meaning to be useful alone.

Research spine: this chapter stays grounded in BM25 and Dense Passage Retrieval (DPR), then applies that evidence to the operating judgment in the book. Read this alongside the RAG That Survives book, the AI-Native thesis, and the full book library when you want the surrounding argument. Here is a design review I have run more than once. An engineer presents a chunking strategy: 512 tokens, 50-token overlap, split on character count. It is clean, it is uniform, it is in every tutorial. I ask one question. I pull up a policy document where a clause begins "Notwithstanding the foregoing, refunds are not available after 30 days unless..." and I show where the 512-token boundary falls: right after "Notwithstanding the foregoing, refunds are." The chunk now says refunds are available. The negation, the condition, and the exception all landed in the next chunk. Retrieve the first chunk and the system confidently tells a customer they can get a refund. The boundary inverted the meaning of the document.
Chunking is not a preprocessing detail. The chunk is the atomic unit your system retrieves, ranks, and packs into the prompt. It is the unit the model reasons over. If the chunk is wrong, everything downstream is wrong, and "wrong" here does not mean low quality. It means the chunk can assert the opposite of what the document says. The companion volume Embeddings, Honestly covers the mechanics of how chunk size interacts with embedding behavior; this chapter is about chunking a corpus that keeps changing, where documents get edited, restructured, and merged, and your boundaries have to survive that.
Key Takeaways
- A chunk is the unit your system actually retrieves, and the Chunk Boundary Test decides whether it carries enough meaning to be useful alone.
- Chunking Documents That Won't Sit Still should be evaluated through concrete evidence, ownership, and failure modes before production behavior changes.
- Read it with the adjacent Rag That Survives chapters to move from diagnosis to an implementation or release decision.
The chunk is a unit of meaning, not a unit of length
The fixed-size habit comes from a reasonable place: embedding models have token limits, and uniform chunks are easy to reason about for cost and storage. But fixed-size chunking optimizes for the wrong thing. It treats a document as a stream of tokens to be cut at regular intervals, when a document is actually a structure of meaning: sections, clauses, steps, rows, definitions. Cutting at a fixed length ignores that structure and routinely slices through the middle of a thought.
The principle to internalize is that a chunk should be a coherent unit of meaning that can stand on its own when retrieved in isolation. When the retriever returns chunk number three of a document, the model sees only chunk three. It does not see chunk two for context unless chunk two was also retrieved, and it usually was not. So chunk three has to make sense alone. A chunk that only makes sense in sequence with its neighbors is a chunk that will mislead the moment it is retrieved alone, which is the normal case.
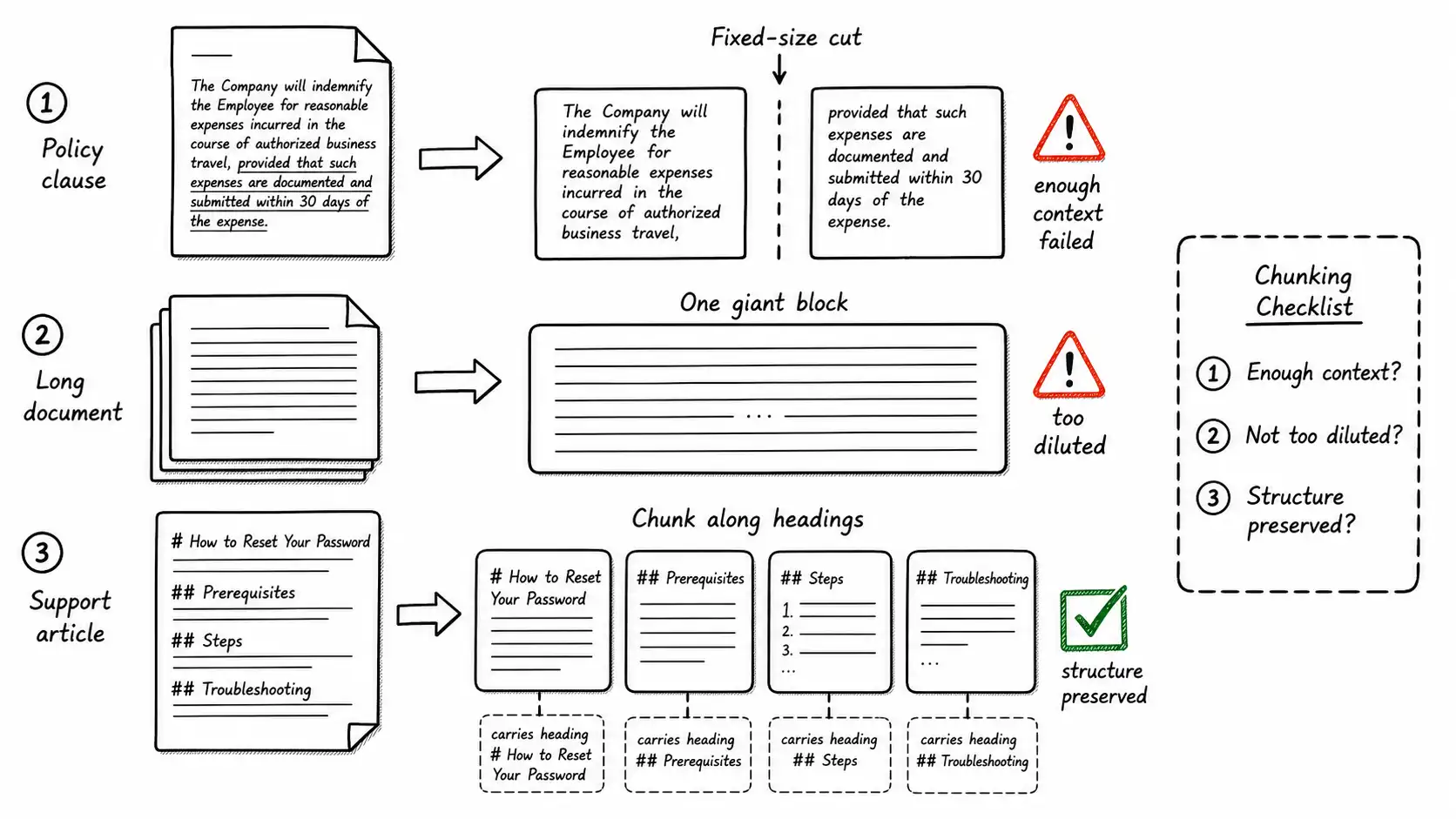
The Chunk Boundary Test
I evaluate every chunking strategy against three questions. This is the Chunk Boundary Test, and it is deliberately simple so you can apply it to an actual chunk in front of you, not in the abstract.
- Enough context. Can this chunk be understood on its own? Does it carry the heading, the subject, the conditions, and the qualifiers needed to interpret it correctly? The refund clause fails this test when the negation is split off.
- Not too much dilution. Is the chunk focused enough that its embedding represents one thing? A chunk that crams an entire ten-page document into one vector represents nothing in particular; it is equally mediocre for every query, so it never ranks first for the query it should own. Dilution is the opposite failure from fragmentation, and both are real.
- Source structure preserved. Does the chunk respect the document's own boundaries: the section, the table, the code function, the step in a procedure? Structure is meaning, as the parsing chapter argued, and a chunk that crosses a structural boundary inherits two half-meanings instead of one whole one.
A good chunk passes all three. Most failures are a violation of one: fragmented (fails enough-context), bloated (fails dilution), or boundary-crossing (fails structure). When you debug a retrieval miss and the correct document was indexed but no chunk of it ranked, the Chunk Boundary Test usually tells you why.
A chunking decision tree by document type
There is no single correct chunk size, and any number a tutorial gives you is a default, not an answer. The right strategy depends on the document's structure. Here is the decision tree I use, anchored on the structured representation from the parsing chapter.
| Document type | Primary strategy | Boundary | Notes |
|---|---|---|---|
| Structured docs (markdown, clean HTML) | Structural | Headings (sections, subsections) | Split on heading hierarchy; one chunk per leaf section; carry the heading into the chunk text |
| Long prose with weak headings | Semantic | Topic shifts / paragraph groups | Group adjacent paragraphs until topic changes; cap size to avoid dilution |
| Policy / legal | Structural + clause-aware | Clause and sub-clause | Never split a clause from its conditions and exceptions; this is the negation trap |
| Procedures / runbooks | Step-aware | Logical step or grouped steps | Keep a step with its prerequisites and warnings; a half-procedure is dangerous |
| Tables | Table-aware (row or row-group) | Row, with headers attached | Serialize header:value per row as in the parsing chapter |
| Code | Syntax-aware | Function / class / logical block | Keep signature, docstring, and body together; include imports as context |
| Spreadsheets | Cell-in-context | Meaningful cell with labels | Each fact carries coordinates and headers |
The unifying idea is that you chunk along the document's own structural seams, not against them. Structural chunking on headings is the workhorse for the largest share of corpora, because most documentation is written with headings that already mark units of meaning. Use them.
Overlap is a patch, not a strategy
Overlap (repeating the last N tokens of one chunk at the start of the next) is the standard remedy for the boundary problem, and it is a weak one. Overlap helps when a meaningful unit straddles a boundary by a little, because the straddling content appears in both chunks. But overlap is a blunt patch applied uniformly, and it does not know where the real boundaries are. It cannot tell that a clause's exception is 200 tokens away rather than 50. It also costs you: overlapping chunks store and embed duplicate content, inflate your index, and produce near-duplicate retrieval results that crowd the candidate set with copies of the same passage.
Use overlap sparingly, as insurance on top of structural chunking, not as a substitute for it. A small overlap (enough to keep a sentence whole across a boundary) is reasonable. Large overlap is a sign that your boundaries are in the wrong place and you are papering over it with duplication. Fix the boundaries instead.
Hierarchical chunking for documents that get reorganized
Here is the problem that "documents that won't sit still" creates. A document is not just edited at the sentence level; it gets reorganized. Sections move. A long article gets split into three. Three short articles get merged into one. If your chunks are flat, every reorganization invalidates a swath of chunk IDs, breaks citations, and forces a full re-chunk and re-embed of the affected documents. And the model, retrieving a leaf chunk, has no idea where in the document it came from after a reorg.
Hierarchical chunking addresses both. You keep the heading hierarchy as a tree and attach each chunk's path, exactly the path field from the parsing chapter. A chunk knows it lives at "Billing > Refunds > Annual plans." This buys you two things. First, the model retrieving that chunk gets the breadcrumb for free, so an isolated paragraph is no longer context-free; it carries its location. Second, when a document is reorganized, you can often re-attach chunks to their new path rather than re-chunking blindly, and citations can point at a stable section path rather than a fragile character offset.
Some teams take this further with a parent-child or small-to-big approach: retrieve on small, precise chunks for matching accuracy, but pack the larger parent section into the context for the model to read. The small chunk is what ranks; the parent is what the model gets. This directly serves the Chunk Boundary Test: small chunks satisfy "not too diluted" for matching, while the parent satisfies "enough context" for generation. It is more machinery, and worth it when precise matching and rich context are both required, such as in dense technical or legal corpora.
Markdown chunking that respects headings
Because structural chunking on headings is the workhorse, here is a concrete implementation that operates on the structured blocks from the parsing chapter and produces chunks that carry their heading path.
def chunk_by_heading(blocks, doc_id, max_chars=1200):
"""Group blocks under their nearest heading into self-contained chunks.
Each chunk carries its heading path so it is interpretable alone.
Splits a section only if it exceeds max_chars, and splits on paragraph
boundaries, never mid-paragraph."""
chunks, current, path = [], [], []
def flush():
if not current:
return
prefix = " > ".join(path)
body = "\n".join(b["text"] for b in current)
chunks.append({
"chunk_id": f"{doc_id}#c{len(chunks)}",
"text": f"[{prefix}]\n{body}" if prefix else body,
"heading_path": list(path),
})
current.clear()
for b in blocks:
if b["type"] == "heading":
flush() # close the previous section
path = path[: b["level"] - 1] + [b["text"]]
continue
current.append(b)
# Cap dilution: if the section grows too large, split on this boundary.
if sum(len(x["text"]) for x in current) > max_chars:
flush()
flush()
return chunksTwo design choices encode the Chunk Boundary Test directly. The heading_path prefix gives every chunk enough context to be read alone (test one). The max_chars cap prevents a giant section from becoming one diluted vector and forces a split on a paragraph boundary rather than mid-sentence (tests two and three). The negation trap from the opening cannot occur, because we never split inside a paragraph, only between them, and we never split a clause from the section that frames it.
Re-chunking is an operation, not a one-time job
The reason this chapter is titled the way it is: chunking is not done once. When a document changes, its chunks must change, and getting this wrong is a common source of staleness. There are three sane policies, and you choose per source based on how it changes.
- Re-chunk the whole document on any edit. Simplest and correct, wasteful for large documents with tiny edits. Fine for short, frequently-edited documents.
- Re-chunk only affected sections. Use the heading path to detect which sections changed and re-chunk just those, leaving stable chunk IDs for the rest. This preserves citations and saves embedding cost. Worth the complexity for large, slowly-edited documents.
- Version chunks alongside documents. Keep the old chunks until the new ones are validated and served, then retire the old. This avoids a window where a document has no current chunks. We will build the full mechanics in the freshness and deletion chapter; note here that chunk lifecycle is downstream of document lifecycle.
The mistake is treating chunking as a build step that runs once at launch. A corpus that won't sit still needs a chunking process that runs continuously, triggered by document change, with a policy chosen to match each source's change frequency from your inventory.
Practical exercise
Take your worst-performing query category, the one where users complain the answer is incomplete or contradicts the document. Find the document that should answer it and look at how it was chunked. Apply the Chunk Boundary Test to the relevant chunks by hand: does the chunk carry its heading and conditions, is it focused on one thing, does it respect the section and clause structure? Pay special attention to negations, exceptions, and conditions ("not," "unless," "except," "only if") sitting near a boundary. If you find a split that inverts or amputates meaning, re-chunk that document structurally and re-test. One fixed boundary often fixes a whole class of complaints.
Summary
A chunk is the unit your system retrieves, ranks, and reasons over, so a bad chunk is not low quality, it can assert the opposite of the source. Chunk along the document's own structural seams, not at fixed character intervals, and apply the Chunk Boundary Test to every strategy: enough context to stand alone, not so much that the vector is diluted, and source structure preserved. Use structural chunking on headings as the workhorse, table-aware and code-aware chunking for those types, overlap only as light insurance, and hierarchical paths so chunks carry their location and survive reorganization. Chunking is not a one-time build step; it runs continuously as documents change, with a re-chunk policy matched to each source's cadence.
Key Takeaways
- The chunk is the atomic unit retrieved and reasoned over; a boundary in the wrong place can invert the document's meaning.
- Chunk along structural seams (headings, clauses, steps, rows, functions), not fixed character counts.
- Apply the Chunk Boundary Test: enough context, not too diluted, source structure preserved.
- Watch negations, exceptions, and conditions near boundaries; splitting them is the classic meaning-inverting bug.
- Overlap is a weak uniform patch that inflates the index with duplicates; fix boundaries instead of leaning on overlap.
- Carry a heading path with each chunk so it is interpretable alone and survives document reorganization.
- Re-chunking is a continuous operation triggered by document change, with a policy matched to each source's cadence.