Reranking and Context Assembly
Getting the right chunk into the candidate set is recall; getting it into the few slots the model actually reads is a separate, equally hard job.

Read this alongside the RAG That Survives book, the AI-Native thesis, and the full book library when you want the surrounding argument. The candidate set looked great. For a query about data residency, the hybrid retriever pulled the correct policy chunk into position eleven out of a hundred candidates. Recall was a success: the right chunk was found. And the answer was still wrong, because we packed the top five candidates into the context and the right chunk was at position eleven. It never reached the model. We had solved recall and lost on precision, and the user experienced a complete failure either way.
This is the gap between two jobs that teams routinely conflate. Candidate retrieval, the subject of the last two chapters, optimizes recall: get the correct chunk somewhere into the candidate set. Reranking and context assembly optimize precision and presentation: take that candidate set and decide which few chunks, in what order, actually enter the prompt. The context window is small and the candidate set is large, so most of what retrieval found never reaches the model. What survives that cut, and how it is arranged, determines the answer. This is links four and five of the Retrieval Failure Chain, reranking and context packing, and they are where a strong retriever quietly throws away its own good work.
Key Takeaways
- Getting the right chunk into the candidate set is recall; getting it into the few slots the model actually reads is a separate, equally hard job.
- Reranking and Context Assembly should be evaluated through concrete evidence, ownership, and failure modes before production behavior changes.
- Read it with the adjacent Rag That Survives chapters to move from diagnosis to an implementation or release decision.
Why retrieval scores are not good enough to rank with
The natural question is: if hybrid retrieval already scored and ranked the candidates, why rerank? Because the retrieval score is cheap and approximate by design. Dense retrieval compares a single query vector to a single chunk vector; it never looks at the query and chunk together. BM25 counts term overlap; it does not understand the relationship between query and passage. These methods are built to be fast over millions of chunks, and that speed is bought with a coarse relevance estimate. They are good at recall (is this chunk in the right neighborhood) and mediocre at fine-grained precision (is this specific chunk the best answer to this specific query).
A reranker is the opposite trade: expensive and precise. A cross-encoder reranker takes the query and a candidate chunk together as a single input and runs them through a model that can attend across both, producing a relevance score that reflects the actual query-chunk relationship. This is far more accurate than comparing pre-computed vectors, and far too slow to run over the whole corpus, which is exactly why it runs second, over a small candidate set, not first. The two-stage pattern (cheap recall-oriented retrieval, then expensive precision-oriented reranking) is the standard architecture, and it exists because no single method is both fast enough for the corpus and precise enough for the answer.
The data-residency failure was a missing second stage. The right chunk was in the candidate set at position eleven on retrieval score. A cross-encoder reranker, scoring each candidate against the query directly, would very likely have lifted it well into the top five, because it would have recognized that the chunk actually addressed data residency while several higher-ranked candidates merely mentioned the words.
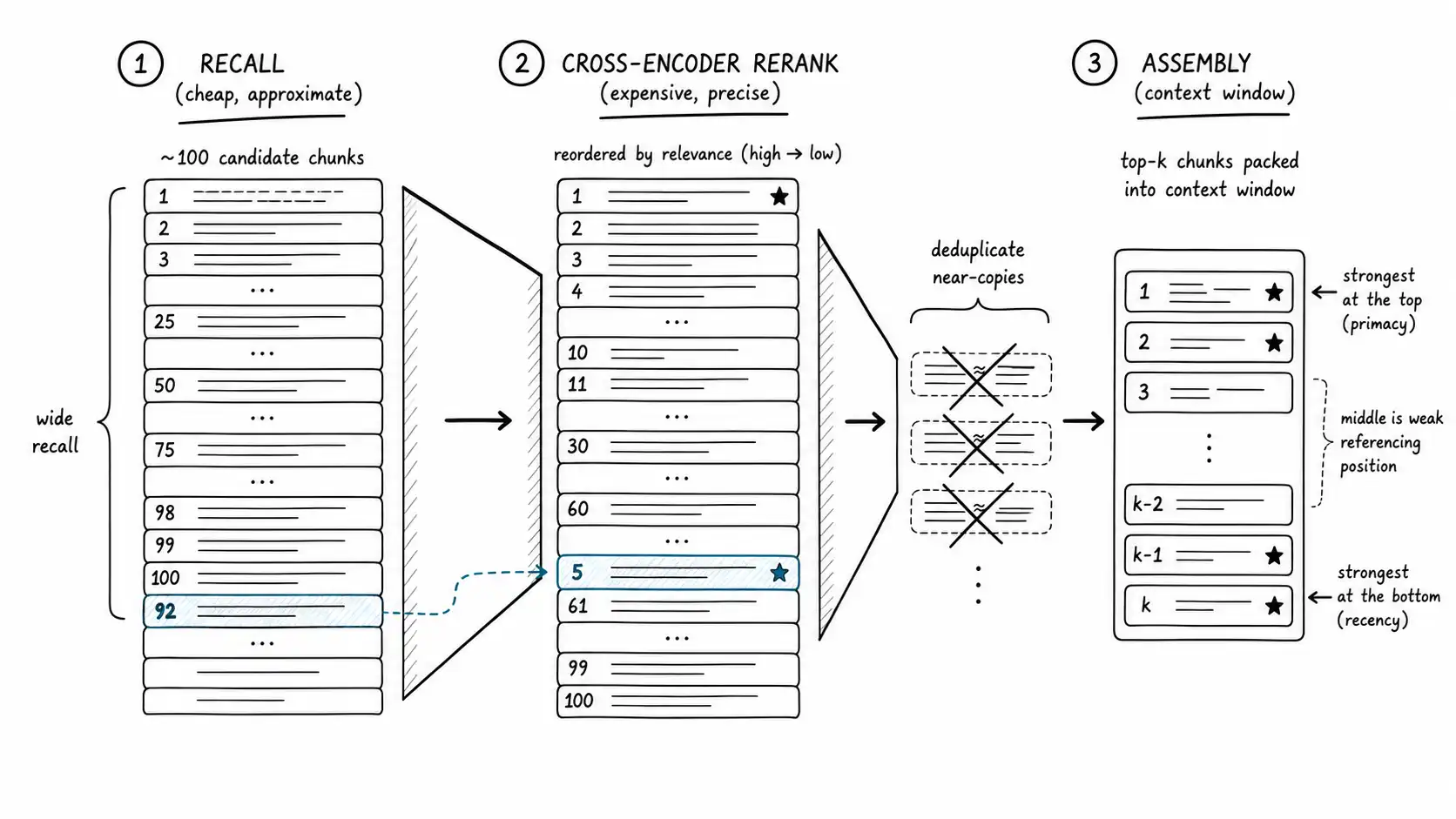
Where to put the reranker in the stack
The reranker sits between candidate retrieval and context assembly. The flow, pulling together the pieces from prior chapters:
def retrieve_and_assemble(query, query_ctx, budget_tokens):
rewritten = rewrite_query(query, query_ctx) # chapter on rewriting
permission = build_permission_filter(query_ctx) # next chapter
candidates = hybrid_retrieve(rewritten, permission, k=100) # recall stage
candidates = apply_metadata_signals(candidates, query_ctx) # metadata chapter
reranked = cross_encoder_rerank(rewritten, candidates) # precision stage
context = assemble_context(reranked, budget_tokens) # packing stage
return contextNote the ordering. Permission filtering happens at retrieval, so the reranker never sees a chunk the user cannot view (you do not want an expensive reranker spending budget on forbidden documents, and you certainly do not want a ranking bug to surface one). Metadata signals adjust scores before reranking so that current beats stale going in. The reranker then does fine-grained relevance ordering. Only after all that does assembly decide what fits.
Context assembly is not "concatenate the top K"
Once the candidates are reranked, the naive move is to take the top K and concatenate them. That throws away three decisions that matter: how much to include, what to remove, and where to place things.
How much: the budget is smaller than you think. It is tempting to fill the context window, especially now that windows are large. Resist it. Liu et al.'s "Lost in the Middle" is the governing result here: models attend best to information at the start and end of the context and degrade in the middle, and adding more context past a point hurts rather than helps because the signal gets buried. The right budget is "enough chunks to answer, and no more." More chunks means more distractors, and distractors are not neutral; they actively pull the model toward irrelevant content. A focused three-chunk context routinely beats a fifteen-chunk one.
What to remove: deduplicate before packing. A drifting corpus is full of near-duplicates: the same policy stated in three articles, an FAQ that paraphrases a help doc, overlapping chunks from your own overlap setting. If the reranker's top five are five paraphrases of the same paragraph, you have wasted four slots and given the model a false sense that this point is overwhelmingly supported while crowding out the second fact it needed. Deduplicate the reranked list by content similarity before assembling, keeping the best representative of each near-duplicate cluster. This single step often improves answers more than tuning the reranker, because it converts redundant slots into informative ones.
Where: place by position, not by score order. Given the lost-in-the-middle effect, the best-ranked chunks should go where the model reads best: at the beginning and the end of the assembled context, not all clustered at the top. A practical pattern is to place the single strongest chunk first, the second strongest last, and the remainder in the middle. It is a small change with measurable effect on whether the model uses the right chunk.
Here is an assembly step that encodes all three decisions:
def assemble_context(reranked, budget_tokens):
selected, used = [], 0
for c in reranked:
if is_near_duplicate(c, selected): # remove redundancy
continue
if used + c["tokens"] > budget_tokens: # respect a tight budget
break
selected.append(c)
used += c["tokens"]
# Place strongest at edges to dodge "lost in the middle".
if len(selected) >= 3:
ordered = [selected[0]] + selected[2:] + [selected[1]]
else:
ordered = selected
return orderedCitations are part of assembly, not an afterthought
The last link of the failure chain is citation, and it is decided at assembly time. Every chunk that enters the context should carry its source identity (the source_id, version, and heading_path from the metadata chapter) so the generated answer can attribute each claim to a verifiable source. This is not cosmetic. Citation is the mechanism by which a human can catch the failure that retrieval and the model cannot catch themselves: a stale or wrong source that was retrieved and used. The refund incident from chapter two was eventually caught only because the answer cited the 2019 post, and a human recognized the date. Without citation, that failure is invisible until a customer is harmed.
The discipline is to assemble context as a list of attributed chunks, prompt the model to cite the chunk it draws each claim from, and surface those citations to the user. A claim that the model cannot attribute to a retrieved chunk is a claim the system should treat with suspicion, because it likely came from the model's parametric memory rather than your corpus, which defeats the entire purpose of grounding. Grounding only helps if you can tell whether the answer was actually grounded, and citation is how you tell.
When to skip the reranker, and when not to
Reranking adds latency and cost, so it is fair to ask when it is worth it. A cross-encoder reranker over 100 candidates adds real milliseconds and a model call. The honest decision table:
| Situation | Rerank? | Why |
|---|---|---|
| High-stakes answers (legal, medical, financial) | Yes | Precision matters more than latency |
| Large or noisy corpus, many near-relevant chunks | Yes | Retrieval score alone cannot separate near-relevant from relevant |
| Measured candidate recall high but answer quality low | Yes | Classic precision gap; the right chunk is ranked too low |
| Tiny, clean corpus, queries match documents closely | Maybe not | Retrieval ranking may already suffice |
| Hard latency budget, low stakes | Lighter reranker or skip | Trade precision for speed deliberately, with eyes open |
The mistake is skipping the reranker by default to save latency and then spending weeks blaming the model for answers that were sitting at candidate position eleven the whole time. If you skip it, skip it as a measured decision, and verify with your evaluation set (next chapter) that retrieval ranking alone gets the right chunk into the packed context. The data-residency team had made the skip decision implicitly, by never adding a reranker, and paid for it in production.
Practical exercise
Take ten queries where the answer was wrong or incomplete. For each, pull the full candidate set (the top 100, before any cut) and find the position of the correct chunk by hand. Bucket the results. If the correct chunk is consistently in the candidate set but ranked below your packing cutoff, you have a precision problem and a reranker is your fix; do not touch the retriever. If it is genuinely absent from the candidate set, you have a recall problem and the fix is upstream in chunking or hybrid retrieval. This one measurement, position of the correct chunk in the full candidate set, cleanly separates the two jobs and tells you which lever to pull.
Summary
Recall and precision are separate jobs that teams conflate. Candidate retrieval gets the right chunk into a large candidate set; reranking and assembly get it into the few slots the model actually reads. Retrieval scores are cheap and coarse by design, so a cross-encoder reranker, which scores query and chunk together, is needed to lift the genuinely-best chunk above the merely-near-relevant ones; it runs second over a small candidate set because it is too slow for the whole corpus. Context assembly is not concatenation: budget tightly because models are lost in the middle and distractors hurt, deduplicate near-copies before packing, place the strongest chunks at the edges, and carry source identity so every claim is citable. Skip the reranker only as a measured decision verified against your eval set, and use the position of the correct chunk in the full candidate set to tell a precision problem from a recall problem.
Key Takeaways
- Recall (get the chunk into the candidate set) and precision (get it into the packed context) are separate jobs; do not conflate them.
- Retrieval scores are fast and coarse; a cross-encoder reranker scores query and chunk together for true precision, running second over a small set.
- Filter permissions before reranking so the reranker never spends budget on, or risks surfacing, forbidden chunks.
- Budget context tightly: models are lost in the middle and distractors actively mislead. Fewer, better chunks win.
- Deduplicate near-duplicates before packing; redundant slots crowd out the second fact the answer needed.
- Place the strongest chunks at the start and end of the context to dodge the lost-in-the-middle effect.
- Carry source identity into every chunk so claims are citable; citation is how humans catch stale or wrong sources the system cannot.