Introduction: The Corpus Moved
Retrieval is not a one-time index, it is an operating system for a corpus that keeps moving.

Read this alongside the RAG That Survives book, the AI-Native thesis, and the full book library when you want the surrounding argument. The demo worked. That is the part everyone remembers, and it is the part that does the most damage.
We had built a support assistant over about forty thousand help-center articles, internal runbooks, and a slice of the product documentation. Launch week, the answers were sharp. A customer asked how to rotate an API key and the system pulled the exact procedure, cited the right article, and got out of the way. The VP of Support forwarded the recording to the executive team. Somebody used the word "magical," which is always a warning sign.
Three weeks later it was quietly wrong. Not catastrophically, not in a way that triggered an alert, just wrong in the way that erodes trust one ticket at a time. A customer asked about the key-rotation flow and the assistant confidently described a screen that no longer existed, because the product team had shipped a new settings UI and renamed the feature from "API Keys" to "Access Tokens." The old article was still in the corpus. It was still well-written. It still embedded beautifully. And it was now a lie.
Nothing in the model changed. The prompt template did not change. The temperature did not change. What changed was the world, and our retrieval system had no idea the world had moved. It was still confidently bringing the wrong world into the prompt.
Key Takeaways
- Retrieval is not a one-time index, it is an operating system for a corpus that keeps moving.
- Introduction: The Corpus Moved should be evaluated through concrete evidence, ownership, and failure modes before production behavior changes.
- Read it with the adjacent Rag That Survives chapters to move from diagnosis to an implementation or release decision.
The enemy is the static folder
Most RAG tutorials teach you to point an embedding model at a folder, build an index, and wire it to a chat completion. That is a fine way to learn the mechanics and a terrible way to run a system. The tutorial corpus never changes. It has no permissions. Nothing is renamed, deprecated, merged, split, or legally retracted. No two documents contradict each other. No document is owned by a team that will reorganize next quarter and stop maintaining it.
Real corpora are nothing like that. A real corpus is a living thing with metabolism. Documents are born, edited, superseded, and abandoned. Terms drift: the feature called "Workspaces" in 2023 is called "Projects" in 2025, and half the corpus still says "Workspaces." Permissions shift: a policy that was company-wide becomes restricted to legal, and your retriever does not know it just leaked a confidential clause into a contractor's chat window. Products get renamed. Companies get acquired. A regulation changes and forty documents become dangerous to surface verbatim.
The central claim of this book is simple and it took me too long to learn it:
Retrieval is not a one-time index. It is an operating system for a corpus that keeps moving.
You do not "set up RAG." You operate a retrieval system the way you operate a database or a payment pipeline: with inventory, ownership, monitoring, refresh schedules, deletion semantics, access control, and a way to find out it is broken before your users do.
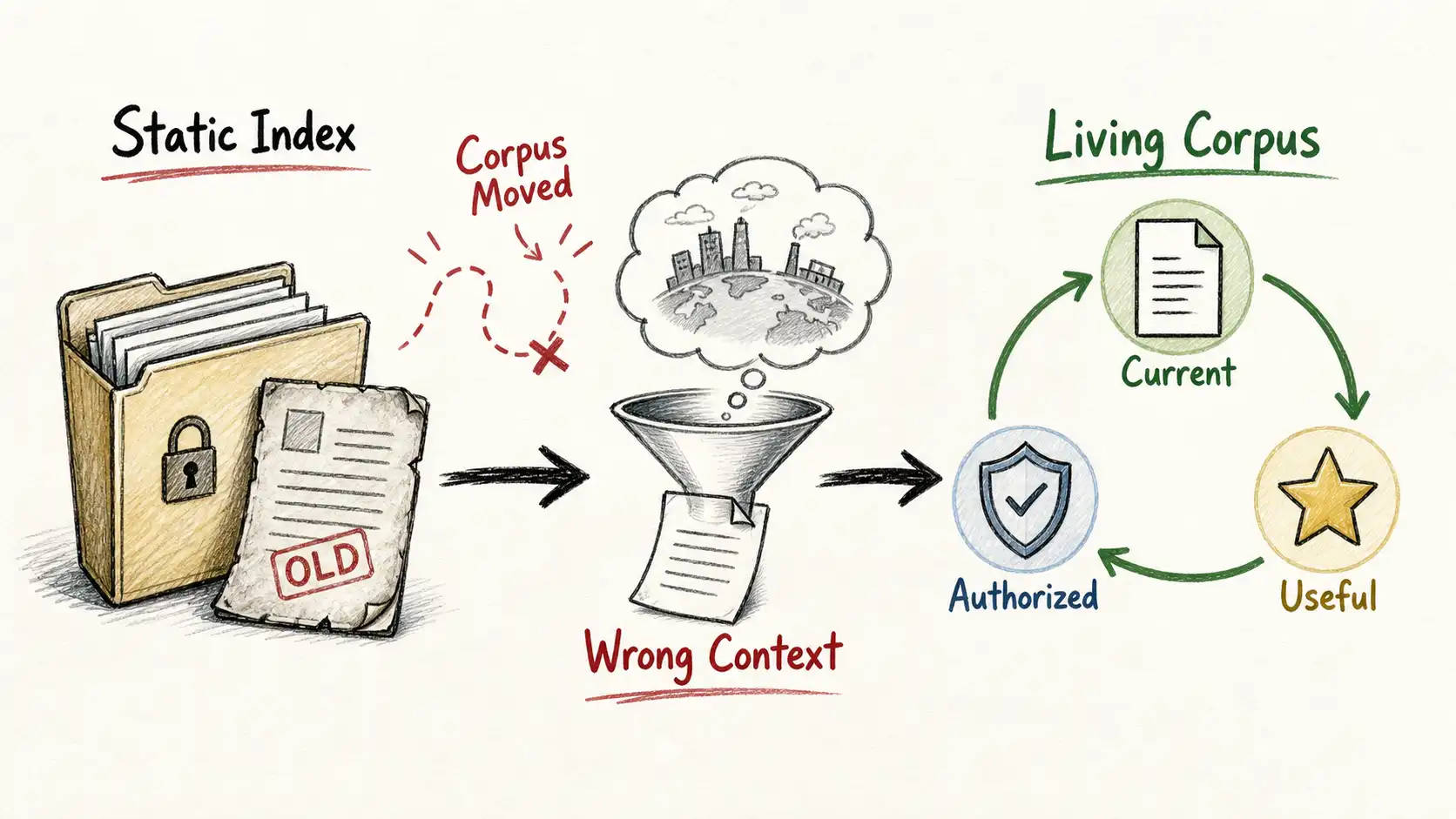
A failure that happens before generation
Here is the mental model I want you to carry through every chapter. When a RAG system gives a bad answer, the instinct is to blame the model. The model hallucinated. The model is too small. We need a better prompt. Sometimes that is true. More often, by the time tokens reach the generator, the damage is already done, because retrieval brought the wrong material into the context window and the model faithfully summarized garbage.
That is the recurring motif of this book:
A RAG system fails before generation when retrieval brings the wrong world into the prompt.
The generator is downstream of the failure. If you retrieve a stale document, a document the user is not allowed to see, a chunk that lost its heading and therefore its meaning, or seven near-duplicates that crowd out the one correct paragraph, then no amount of prompt engineering saves you. The model is doing exactly what you asked: answering from the context you gave it. The context was the problem.
This reframing matters because it changes where you spend your engineering effort. The team that believes it has a model problem buys a bigger model. The team that understands it has a retrieval problem fixes its chunking, its freshness, its permissions, and its reranking, and the same model suddenly looks much smarter. Retrieval-augmented generation was introduced by Lewis et al. in 2020 precisely to ground a generator in retrieved evidence. The grounding is only as good as the retrieval, and the retrieval is only as good as the corpus you are willing to maintain.
What this book is, and is not
Let me be direct about scope so you do not feel misled in chapter four.
This book is a field manual for engineers who have to keep a retrieval system working over months and years as the underlying corpus, users, permissions, terms, and products change. It is about ingestion and parsing, chunking documents that refuse to sit still, metadata as a control plane, hybrid retrieval and reranking, query rewriting, permission-aware retrieval that runs before generation, the lifecycle of a living index, and evaluating retrieval separately from answers so you can tell which half is broken.
This book is not a vector database tutorial. I will reference pgvector, Elasticsearch, OpenSearch, Qdrant, Vespa, and others as examples, but I will not teach you to install one. It is not a LangChain projects book. It is not a generic embeddings book, and there is a companion technical deep dive, Embeddings, Honestly, that covers vector spaces, similarity, and the mechanics of chunking and reranking in detail. I will not re-derive that material here. And this book absolutely does not claim that RAG eliminates hallucination. RAG changes where hallucination comes from. A grounded model can still be confidently wrong if you ground it in the wrong document.
Four frameworks you will see repeatedly
I dislike acronyms that exist to look tidy. The four frameworks in this book earned their place because I use them in real reviews, and you will see each one applied in several different chapters rather than defined once and abandoned.
The CORPUS Readiness Model asks, before you embed anything, whether the corpus is even fit to retrieve from: Coverage, Ownership, Rights, Parsing, Updates, Searchability. Skipping this is how you end up indexing forty thousand documents and discovering that eight thousand are duplicates, three thousand are stale, and four hundred should never have been readable in the first place.
The Retrieval Failure Chain is the diagnostic spine: query interpretation, permissions, candidate retrieval, reranking, context packing, generation, citation. When an answer is wrong, you walk the chain and find the link that broke. It keeps teams from blaming the model reflexively.
The Chunk Boundary Test is three questions you apply to any chunking strategy: does each chunk carry enough context to be understood alone, is it small enough not to dilute the signal, and does it preserve the source structure (the heading, the table, the code block) that gives it meaning?
The Living Index Lifecycle is the operating loop: discover, parse, chunk, enrich, embed/index, validate, serve, observe, refresh, retire. A static folder has none of these stages past "index." A retrieval system that survives contact runs all ten, continuously.
How to read this book
Read the introduction and the next chapter in order, because they set the diagnostic frame. After that, the chapters are deliberately modular. If you are firefighting a freshness incident this week, jump to the chapter on freshness, versioning, deletion, and reindexing. If your legal team just asked who can see what, go straight to permissions before retrieval. If your eval numbers look fine but users complain, the chapter on evaluating retrieval apart from answers is where you want to be.
Every chapter carries real artifacts: schemas you can copy, decision tables, runbooks, pseudocode, and worksheets. They are not decoration. I have used versions of all of them in production reviews. Where a number could have changed since I wrote this, I have linked the primary source so you can re-verify rather than trust my memory.
A word on voice. I write as someone who has shipped these systems, sat in the incident calls, and explained to a customer why the assistant told them to click a button that no longer exists. The tone is operational and occasionally blunt because the failure modes are operational. Retrieval that survives contact is not a clever trick. It is the discipline of treating a corpus as infrastructure.
The promise
By the end of this book you will be able to build and run a retrieval system that keeps working as documents change, users change, permissions change, terms change, and products change. You will know how to inventory a corpus before you trust it, parse the documents you actually have rather than the clean markdown you wish you had, chunk in a way that preserves meaning, retrieve with a hybrid stack that does not collapse on rare terms, filter by permission before a single vector is compared, rewrite vague queries into answerable ones, rerank and assemble context that the model can actually use, evaluate retrieval as its own discipline, and operate the whole thing through a lifecycle with refresh and retirement built in.
The standard I will hold us to is one line, and it is the line the book ends on: current, authorized, useful corpus, or no trustworthy answer. If the system cannot meet all three, it should say it does not know rather than confidently describe a button that no longer exists.
The demo will always work. The job is the three weeks after.