Parsing Is Part of Retrieval
The quality ceiling of your retrieval system is set the moment a document becomes text, and most teams lose meaning there without noticing.

Research spine: this chapter stays grounded in BM25 and Dense Passage Retrieval (DPR), then applies that evidence to the operating judgment in the book. Read this alongside the RAG That Survives book, the AI-Native thesis, and the full book library when you want the surrounding argument. Open a PDF of a product datasheet in a text extractor and watch what happens to the table. The neat grid that a human reads in two seconds, three columns of specifications across eight rows, comes out as a flat stream: "Model Weight Power A1 2.3kg 40W A2 3.1kg 65W A3 4.0kg 90W." A human can still decode that with effort. An embedding model encodes it as a soup of numbers and units with no idea which weight belongs to which model. Retrieve that chunk for the query "how much power does the A2 draw" and the model has a coin flip's chance of saying 65W, because the structure that bound 65W to A2 was destroyed at parse time.
This is the chapter everyone wants to skip and nobody can afford to. Parsing feels like plumbing, beneath the interesting work of retrieval. But parsing sets the ceiling on everything downstream. A chunk that lost its meaning at extraction cannot be rescued by a better embedding model, a smarter reranker, or a longer context window. The information is simply gone. Parsing is not preprocessing for retrieval. It is part of retrieval.
Key Takeaways
- The quality ceiling of your retrieval system is set the moment a document becomes text, and most teams lose meaning there without noticing.
- Parsing Is Part of Retrieval should be evaluated through concrete evidence, ownership, and failure modes before production behavior changes.
- Read it with the adjacent Rag That Survives chapters to move from diagnosis to an implementation or release decision.
The lossy step you cannot see
The danger of parsing is that it fails silently. Embedding succeeds on garbage. Indexing succeeds on garbage. Retrieval returns garbage with a confidence score. Generation summarizes garbage fluently. There is no error, no exception, no alert. The pipeline is green end to end, and the answers are subtly wrong in ways that trace back to a step nobody is watching.
I learned to audit parsing the hard way. On one project, the assistant kept getting numbers slightly wrong: a 30-day window reported as 90 days, a $50 fee reported as $5. We chased the model for a week. The cause was a PDF extractor that occasionally merged adjacent table cells and dropped decimal points and currency symbols depending on the font embedding. The text was eighty percent intact, which is exactly the failure that hides best. Fully broken parsing gets caught because the chunk is obviously gibberish. Eighty-percent-intact parsing ships to production and lies on a long tail of queries.
The rule that follows is simple: read your parsed output before you trust it. Not the source documents. The text that actually comes out of your parser and goes into your chunks. Sample widely across formats, and read the worst cases, not the cleanest ones.
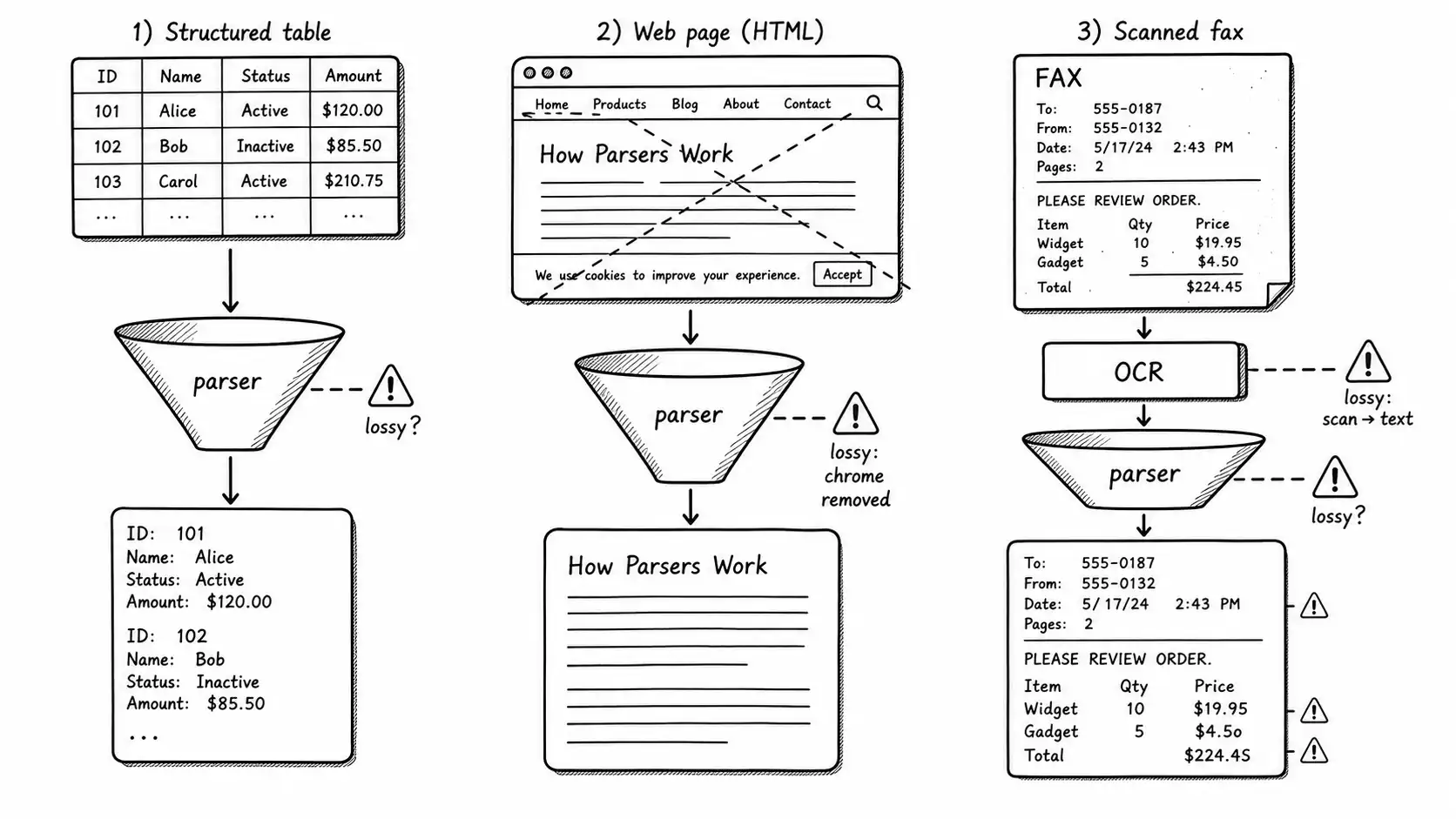
Format by format, what breaks
Documents are not one thing, and a single parser applied to everything is a guarantee of loss. Treat each format as its own problem.
Markdown and clean HTML are the easy case, and even here there is a trap: HTML pulled from a live site carries navigation menus, cookie banners, footers, "related articles" sidebars, and breadcrumb trails. If you embed that chrome, every chunk from the help center looks a little bit like every other chunk, because they all share the same boilerplate. The cosine similarity between two unrelated articles rises just because they both contain "Subscribe to our newsletter" three times. Strip the chrome. Keep the article body and its heading structure. This is also where you preserve the heading hierarchy, which becomes the backbone of structural chunking in the next chapter.
PDFs are two completely different problems wearing the same extension. A born-digital PDF (exported from a word processor) has a real text layer and extracts reasonably, modulo the table problem. A scanned PDF is an image of text and has no text layer at all; extracting it requires OCR. Mixing them under one pipeline means your scanned documents either silently produce empty chunks or get OCR'd with errors you never reviewed. At inventory time you flagged the scanned percentage; here is where it costs you.
Tables are the single most common silent-loss case, and they appear everywhere: pricing, specifications, SLAs, compatibility matrices, comparison charts. A table's meaning lives in the relationship between cells, rows, and headers. Flatten it to a line of text and that meaning evaporates. The fix is table-aware extraction that preserves structure, and then a representation that re-attaches headers to values. Tools and research in this space, including layout-aware document parsers, exist precisely because naive text extraction destroys tabular meaning. The practical move is to detect tables, extract them as structured rows, and serialize each row with its column headers inline so the chunk reads "Model: A2, Weight: 3.1kg, Power: 65W" rather than a bare grid.
Spreadsheets are tables without even the pretense of prose. A cell containing "65" is meaningless without its row label and column header, and possibly a sheet name and a unit defined three rows up. Naively flattening a spreadsheet to CSV-as-text produces chunks of disconnected numbers. If spreadsheets carry real answers in your domain, you parse them cell-in-context: each meaningful cell becomes a fact with its coordinates and labels attached.
Slide decks hide meaning in spatial layout and in speaker notes. The on-slide text is often fragmentary ("Q3: up 40%") and the real content is in the notes or in the arrangement. Decks are low-yield, high-effort sources; flag them honestly and consider whether the underlying information exists in a better-structured source.
Code is structure all the way down. A function signature, its docstring, and its body belong together; a class belongs together; an import block provides context the body depends on. Splitting code by character count cuts functions in half and separates a symbol from its definition. Code needs syntax-aware chunking, which we will handle in the chunking chapter, but it starts here with a parser that understands the language's structure rather than treating a source file as a wall of text.
OCR is a decision, not a default
When you have scanned documents, OCR is unavoidable, but it is a deliberate decision with consequences, not a free toggle. OCR introduces errors: a "1" becomes an "l", an "O" becomes a "0", multi-column layouts get interleaved, and tables fare even worse than they do in born-digital PDFs. Those errors propagate into chunks, embeddings, and answers, and they are invisible unless you check.
The discipline is to treat OCR output as untrusted until measured. Sample OCR'd documents, compare against the source by hand, and estimate an error rate. If the error rate is high, you have three honest options: improve the OCR (better engine, layout analysis, language model post-correction), exclude the source until it can be re-scanned or re-sourced cleanly, or flag the source as low-confidence in metadata so downstream ranking and citation can treat it with caution. What you do not do is silently blend high-error OCR text into the same index as clean text and let the retriever pick it as if it were equally trustworthy.
Preserve structure, do not flatten it
The deepest principle of good parsing is that structure is meaning. A heading tells you what a paragraph is about. A list item belongs to its list. A table cell belongs to its row and column. A code block is not prose. When you flatten a document to a single string of text, you discard exactly the signals that make retrieval and chunking work.
The better target is a structured intermediate representation. Rather than parsing straight to a flat string, parse to a tree or a sequence of typed blocks: headings with levels, paragraphs, list items, tables as rows-and-headers, code blocks with language, figures with captions. This intermediate representation carries the structure forward so that chunking can respect it and metadata can be attached to it. Many modern document parsers target exactly this kind of structured output rather than raw text, and the reason is that the structure is what survives into useful chunks.
Here is the shape of a structured block I aim for, before chunking touches it:
{
"doc_id": "datasheet-a-series-v3",
"blocks": [
{ "type": "heading", "level": 2, "text": "Power consumption", "path": ["Specifications", "Power consumption"] },
{ "type": "paragraph", "text": "Power draw is measured at peak load, 25C ambient." },
{ "type": "table",
"headers": ["Model", "Weight", "Power"],
"rows": [
["A1", "2.3kg", "40W"],
["A2", "3.1kg", "65W"],
["A3", "4.0kg", "90W"]
],
"path": ["Specifications", "Power consumption"] }
],
"parse_confidence": 0.98,
"source_format": "pdf-born-digital"
}Notice three things this carries that a flat string cannot. The path records where each block sits in the heading hierarchy, so a chunk can later be labeled "this is from Specifications > Power consumption" even if it is just a table. The table keeps its headers, so each row can be serialized with labels attached. And parse_confidence and source_format are honest signals that downstream stages can use, exactly the way we used parse_confidence to decide what to do with OCR.
A small, real chunk-prep step for tables
Because tables cause the most silent damage, here is the concrete transformation that makes them survive. Take the structured table block above and serialize each row as a self-describing fact:
def table_to_chunks(table_block, doc_id):
headers = table_block["headers"]
path_prefix = " > ".join(table_block["path"])
chunks = []
for i, row in enumerate(table_block["rows"]):
# Attach each header to its value so meaning survives flattening.
labeled = ", ".join(f"{h}: {v}" for h, v in zip(headers, row))
text = f"[{path_prefix}] {labeled}"
chunks.append({
"chunk_id": f"{doc_id}#tbl_r{i}",
"text": text, # e.g. "[Specifications > Power consumption] Model: A2, Weight: 3.1kg, Power: 65W"
"block_type": "table_row",
})
return chunksNow the query "how much power does the A2 draw" matches a chunk whose text literally says "Model: A2 ... Power: 65W," with its section path attached for context. The binding between A2 and 65W that the naive extractor destroyed is preserved. This one transformation has fixed more numeric-accuracy bugs in my experience than any model change.
Parsing failures show up as model failures, again
You will notice the theme from the last two chapters repeating: parsing failures masquerade as model failures. The model says the A2 draws an ambiguous amount of power, and the team concludes the model is bad at numbers. The model says the fee is $5 instead of $50, and the team adds a "double-check arithmetic" instruction to the prompt. None of it helps, because the loss happened at parse time and the prompt is downstream of the loss. When you walk the Retrieval Failure Chain and the correct chunk is in the candidates but the chunk itself is corrupted, the broken link is not retrieval ranking and not generation. It is parsing, upstream of the whole chain.
This is why I treat a parsing audit as part of retrieval evaluation, not a separate concern. Before measuring recall, I measure parse fidelity: for a sample of documents, does the parsed text faithfully represent the source, with tables and structure intact? A retrieval system built on lossy parsing has a recall ceiling it can never break through, no matter how good the rest of the stack is.
Practical exercise
Pick the three most numerically important documents in your corpus, the ones where a wrong number causes real harm: a pricing table, an SLA, a specification sheet. Run them through your current parser and read the raw output. Find every table and check whether each value is still bound to its row and column. Find every number and check decimals, units, and currency symbols. If anything is lost, you have located a silent failure that is currently shipping wrong answers, and you have your first parsing fix. Then sample your scanned-document sources, if any, and estimate an OCR error rate against the originals. Decide, per source, whether to improve, exclude, or flag.
Summary
Parsing sets the ceiling for everything downstream and fails silently, because embedding and retrieval succeed on garbage. Each format breaks differently: HTML carries chrome that pollutes similarity, PDFs split into born-digital and scanned (OCR territory), tables and spreadsheets lose the cell-to-header binding that holds their meaning, decks hide meaning in layout, and code is structure all the way down. The fix is to parse to a structured intermediate representation that preserves headings, tables-with-headers, and code structure rather than flattening to a string, to treat OCR as untrusted until measured, and to serialize tables as self-describing rows. Audit parsed output by reading it, and treat parse fidelity as the first thing you measure, before recall.
Key Takeaways
- Parsing sets the quality ceiling for retrieval; a chunk that lost meaning at extraction cannot be rescued downstream.
- Parsing fails silently. Embedding, indexing, retrieval, and generation all succeed on garbage. Read your parsed output.
- Strip HTML chrome; shared boilerplate inflates similarity between unrelated documents.
- Tables and spreadsheets lose meaning when flattened; preserve the cell-to-header binding and serialize rows as self-describing facts.
- OCR is a measured decision: improve, exclude, or flag low-confidence sources rather than blending errors into the index.
- Parse to a structured intermediate representation (headings, tables, code, paths) so chunking and metadata can use the structure.
- Audit parse fidelity before measuring recall; lossy parsing imposes a recall ceiling no model can break.