Dense, Sparse, Hybrid, and Late Interaction
Every retrieval method has a blind spot, and a corpus that won't sit still will find it; the fix is a stack, not a single method.

Read this alongside the RAG That Survives book, the AI-Native thesis, and the full book library when you want the surrounding argument. A benchmark slide nearly cost a team their launch. The slide compared dense retrieval against BM25 on a standard QA dataset, dense won by a comfortable margin, and the conclusion was "use dense, skip the keyword stuff, it's legacy." Three months into production, the support team escalated a pattern of misses: queries containing exact error codes, internal SKU numbers, version strings like "v2.14.3," and rare product names were failing. The dense retriever, which had won the benchmark, could not reliably find a document by an exact alphanumeric token, because tokens like "ERR_4011" carry almost no semantic signal to embed. BM25 would have nailed every one of them. The benchmark was real and the conclusion was still wrong, because the benchmark's queries did not look like the production queries.
This chapter is about choosing retrieval methods for a corpus that keeps changing and a query distribution you do not fully control. The short version: every method has a blind spot, the blind spots are different, and the durable answer is a hybrid stack that covers them. The companion volume Embeddings, Honestly covers the internals of how dense vectors and rerankers work; here I care about which method catches which failure on a real, drifting corpus, and how to combine them.
Key Takeaways
- Every retrieval method has a blind spot, and a corpus that won't sit still will find it; the fix is a stack, not a single method.
- Dense, Sparse, Hybrid, and Late Interaction should be evaluated through concrete evidence, ownership, and failure modes before production behavior changes.
- Read it with the adjacent Rag That Survives chapters to move from diagnosis to an implementation or release decision.
Sparse retrieval: exact terms, no understanding
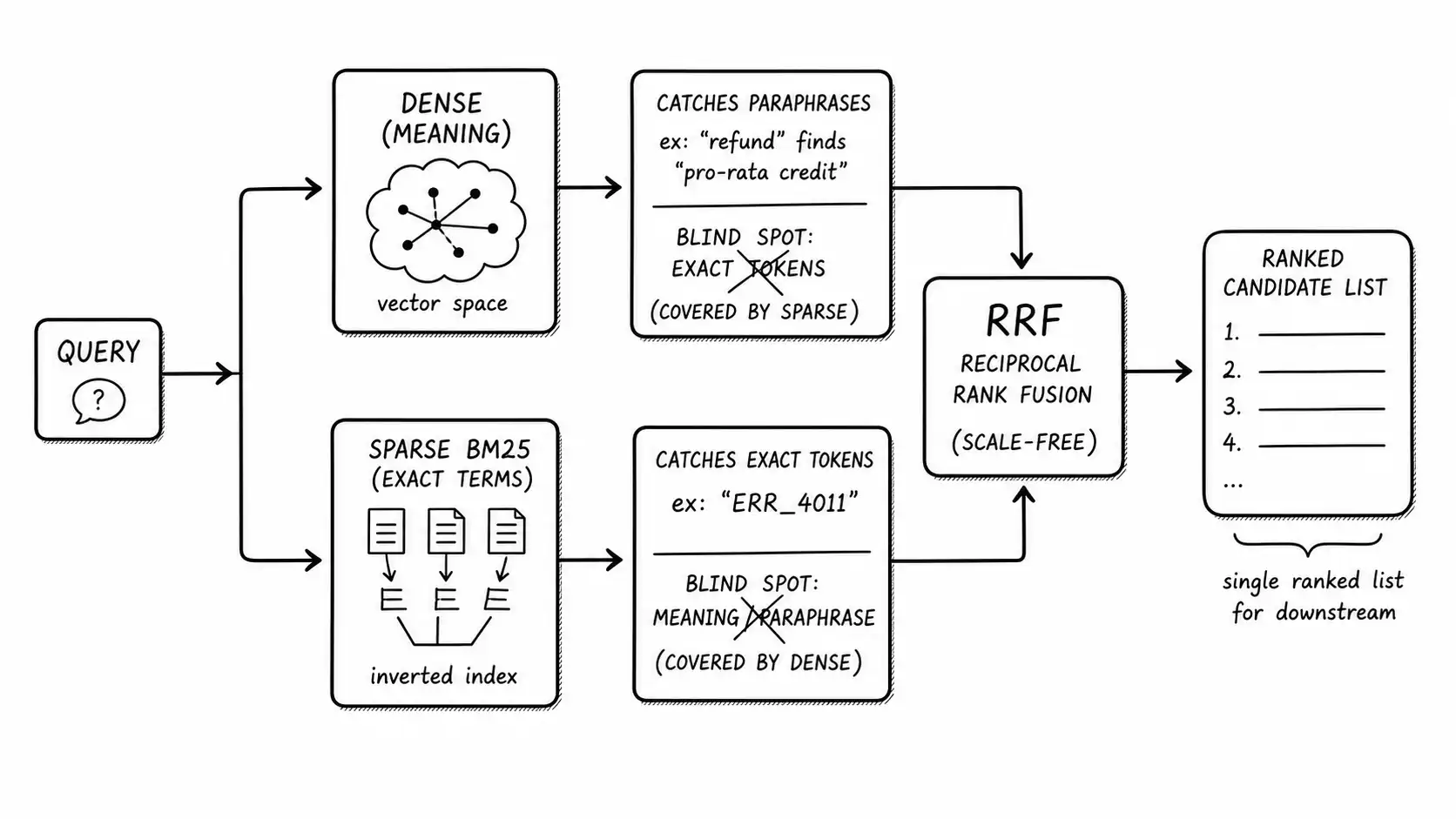
Sparse retrieval, of which BM25 is the durable standard, scores documents by term overlap, weighted so that rare terms matter more and long documents do not dominate. It has been the backbone of search for decades because it is fast, interpretable, requires no training, and is unbeatable at one thing: finding documents that contain the exact tokens in the query.
That strength is precisely what the benchmark team threw away. Error codes, SKUs, version strings, person names, function names, legal citation numbers: these are high-signal exact tokens that mean almost nothing semantically. "ERR_4011" does not live in a meaningful neighborhood of embedding space; it is a near-random point. But BM25 finds it instantly because the token either appears in a document or it does not.
Sparse retrieval's blind spot is the mirror image: vocabulary mismatch. If the user types "refund" and the document says "pro-rata credit upon termination," BM25 scores them near zero, because they share no tokens. It does not understand that they mean the same thing. On a corpus where users and authors use different vocabulary (which is most corpora, as the Searchability dimension in the inventory chapter warned), pure BM25 misses a large class of paraphrased queries.
Dense retrieval: meaning, no exactness
Dense retrieval, exemplified by Dense Passage Retrieval (DPR), encodes queries and documents into vectors so that semantically related text lands nearby, and retrieves by nearest-neighbor search. Its strength is exactly BM25's blind spot: it matches on meaning, so "refund" finds "pro-rata credit" even with zero shared tokens. DPR's own paper reported large top-20 accuracy gains over a Lucene-BM25 baseline on open-domain QA, which is why dense retrieval became the default.
But dense has its own blind spots, and the benchmark team walked into all of them. First, exact tokens, as discussed: rare alphanumeric strings embed poorly. Second, out-of-distribution content: an embedding model trained on general text may place your domain's jargon poorly, and a corpus that drifts (new product names, new terminology) drifts away from where the embedding model expects it. Third, the embedding model is frozen at a point in time and knows nothing about terms coined after its training. When your product launches a feature called "Flux" and the embedding model has never seen the word in your sense, dense retrieval cannot place it well. A drifting corpus continuously generates exactly this kind of out-of-vocabulary content, which is a core reason this book exists.
There is also a learned variant of sparse retrieval worth knowing: SPLADE and similar methods use a language model to produce sparse term weights with term expansion, getting some of dense's vocabulary-bridging while keeping the exact-match and interpretability benefits of an inverted index. It is a reasonable middle path when you want sparse-style behavior with learned expansion.
Hybrid: cover both blind spots
Since dense and sparse have complementary blind spots, the obvious move is to run both and combine the results. This is hybrid retrieval, and on a real corpus it is not a nice-to-have; it is the baseline that survives contact. Dense catches the paraphrases, sparse catches the exact tokens, and together they cover the failure that sinks either one alone.
The combination problem is real, though: dense produces cosine similarities (roughly 0 to 1), BM25 produces unbounded relevance scores on a different scale. You cannot just add them. There are two practical approaches.
The first is score normalization, where you rescale both score distributions to a common range and combine with weights. This works but is fiddly, because the score distributions shift with the corpus and the query, so your normalization and weights drift out of calibration as the corpus changes. On a moving corpus, score-based fusion is a maintenance burden.
The second, and the one I default to, is rank-based fusion, specifically Reciprocal Rank Fusion (RRF). RRF ignores the raw scores entirely and combines based on rank position. A document's fused score is the sum, across each retrieval method, of 1/(k + rank) where rank is its position in that method's results and k is a small constant (commonly 60). Cormack et al. showed RRF outperforming both Condorcet fusion and individual learned rankers, and its great virtue here is that it is scale-free: it does not care that dense and BM25 score on different scales, so it does not drift out of calibration when the corpus moves. For a system whose whole premise is a changing corpus, that robustness is exactly what you want.
def reciprocal_rank_fusion(result_lists, k=60):
"""result_lists: list of ranked lists of chunk_ids, one per retriever.
Returns chunk_ids sorted by fused RRF score. Scale-free: only ranks matter."""
scores = {}
for results in result_lists:
for rank, chunk_id in enumerate(results):
scores[chunk_id] = scores.get(chunk_id, 0.0) + 1.0 / (k + rank + 1)
return sorted(scores, key=scores.get, reverse=True)
def hybrid_retrieve(query, query_ctx, k_each=50, k_final=100):
permission = build_permission_filter(query_ctx) # from the permissions chapter
dense_hits = dense_search(query, filter=permission, top_k=k_each)
sparse_hits = bm25_search(query, filter=permission, top_k=k_each)
fused = reciprocal_rank_fusion([dense_hits, sparse_hits])
return fused[:k_final]Notice that both retrievers receive the same permission filter, and they receive it before searching, not after fusion. That ordering is not optional, and the permissions chapter explains why at length. Notice also that this produces a candidate set, not a final answer; the candidates still go to a reranker, which the next chapter covers. Hybrid retrieval's job is recall: get the right chunk into the candidate set. Ranking it to the top is reranking's job.
Late interaction: when fused ranking is not precise enough
There is a third architecture worth understanding for high-precision needs: late interaction, introduced by ColBERT (Khattab and Zaharia). Standard dense retrieval compresses an entire passage into one vector, which loses fine-grained detail; a long passage's single vector is an average that can blur the specific sentence that answers the query. Late interaction instead keeps a vector per token and computes relevance by matching each query token to its best-matching document token (a "MaxSim" operation), summed across query tokens. This preserves token-level detail and is notably strong at matching specific terms within a passage, recovering some of the exact-match precision that single-vector dense loses, while still being learned and semantic.
The trade is cost and complexity: storing per-token vectors is far more storage than one vector per chunk, and the matching is more expensive. ColBERTv2 reduced this with residual compression, making it more practical, but it is still heavier than single-vector dense plus BM25. My guidance: do not reach for late interaction first. Hybrid dense-plus-sparse with a reranker covers most needs. Consider late interaction when you have a precision-critical, term-sensitive corpus (legal, technical specs, code) and you have measured that single-vector dense plus BM25 leaves precision on the table. It is a tool for a specific deficit, not a default.
A decision table for the retrieval stack
Here is how I choose, anchored on the corpus and query characteristics you actually have rather than on a leaderboard.
| If your corpus / queries have... | Then prioritize | Because |
|---|---|---|
| Many exact tokens (codes, SKUs, versions, names) | Sparse (BM25) in the stack, always | Dense cannot reliably match rare alphanumeric tokens |
| Heavy vocabulary mismatch (user vs author language) | Dense in the stack, always | Sparse misses paraphrases with zero shared tokens |
| Both (the normal case) | Hybrid with RRF | Complementary blind spots; RRF is scale-free under drift |
| Frequent new terms / drifting vocabulary | Hybrid + sparse weight; plan re-embedding | Frozen embeddings lag new terms; sparse catches literals |
| Precision-critical, term-sensitive, measured dense gaps | Add late interaction (ColBERT) | Token-level matching recovers precision single-vector loses |
| Multilingual | Dense with multilingual model + sparse per-locale | Cross-language meaning matching plus exact-term fallback |
The row I want to underline is "frequent new terms." A corpus that won't sit still constantly introduces vocabulary the embedding model has never seen, which steadily degrades pure-dense recall over time even if nothing else changes. Sparse retrieval is partially immune (a new token is just a new token in the index), which is another reason hybrid is the survivable default. It also flags a maintenance task we will return to: when the embedding model falls too far behind your corpus's vocabulary, you re-embed, and that is a lifecycle operation, not a one-time job.
Recall first, then precision, in that order
The most common stack-design mistake after "dense only" is optimizing the wrong stage. The retrieval stack has two jobs in sequence. Candidate retrieval (dense plus sparse, fused) optimizes recall: get the correct chunk into the candidate set of, say, the top 100. Reranking (next chapter) optimizes precision: order those candidates so the best ones land in the limited context budget. These need different tuning, and conflating them wastes effort.
If the correct chunk is not in the top 100 candidates, no reranker can save you, because reranking only reorders what retrieval found. So the first thing to measure and protect is candidate recall: across a labeled query set, how often is the correct chunk somewhere in the candidate set? You tune the retrieval stack (add sparse, widen k, fix chunking and vocabulary) until candidate recall is high. Only then does reranking precision become the lever that matters. We will build the measurement (recall@k) in the evaluation chapter; the design principle here is that the stack exists to get recall high enough that reranking has something to work with.
Practical exercise
Pull fifty real production queries and bucket them: which contain exact tokens (codes, versions, names, SKUs), and which are natural-language paraphrases of corpus content? Run each through your current retriever and check whether the correct chunk appears in the top 50 candidates. You will almost certainly find that one bucket fails badly: if you are dense-only, the exact-token bucket fails; if you are sparse-only, the paraphrase bucket fails. That failing bucket is the method you are missing. Add it, fuse with RRF, and re-measure the same fifty. The lift on the previously-failing bucket is usually dramatic and immediate.
Summary
Every retrieval method has a blind spot, and a drifting corpus with an uncontrolled query distribution will find it. Sparse (BM25) is unbeatable at exact tokens and blind to paraphrase; dense (DPR-style) matches meaning and is blind to rare exact tokens and to terms coined after the embedding model was trained. Because the blind spots are complementary, hybrid retrieval is the survivable baseline, and Reciprocal Rank Fusion is the right combiner because it is scale-free and does not drift out of calibration as the corpus moves. Late interaction (ColBERT) recovers token-level precision for term-sensitive corpora but costs more, so reach for it only against a measured deficit. Design the stack as recall first (get the right chunk into the candidate set) then precision (reranking), and apply the same permission filter to every retriever before it searches.
Key Takeaways
- Benchmarks that win on someone else's query distribution can lose on yours; choose methods for your actual corpus and queries.
- Sparse (BM25) owns exact tokens (codes, SKUs, versions, names); dense owns meaning and paraphrase. Their blind spots are mirror images.
- Hybrid retrieval is the baseline that survives contact; do not ship dense-only or sparse-only on a real corpus.
- Use Reciprocal Rank Fusion to combine retrievers; it is scale-free and stays calibrated as the corpus drifts.
- A drifting corpus constantly introduces terms the frozen embedding model has not seen, steadily degrading pure-dense recall; sparse is partially immune.
- Late interaction (ColBERT) recovers token-level precision for term-sensitive corpora at higher cost; use it against a measured gap, not by default.
- Design the stack recall-first then precision; reranking can only reorder what retrieval found.