Conclusion: Current, Authorized, Useful
The standard for a retrieval system that survives contact is one line: a current, authorized, useful corpus, or no trustworthy answer.

Research spine: this chapter stays grounded in BM25 and Dense Passage Retrieval (DPR), then applies that evidence to the operating judgment in the book.
Read this alongside the RAG That Survives book, the AI-Native thesis, and the full book library when you want the surrounding argument.
Go back to the assistant that worked on launch day and was quietly wrong three weeks later. By now you can name exactly what happened to it, link by link. The product rename was a metadata status failure: the old article was never deprecated, so retrieval treated it as current. The permission drift was a freshness failure: the index froze access rules at ingestion. The vocabulary gap between "API Keys" and "Access Tokens" was a retrieval-stack failure that a sparse leg and a reranker would have softened. And the reason nobody noticed for three weeks was an observability and evaluation failure: there was no retrieval trace, no gold eval set, and no signal watching for deprecated chunks. The system did not break. It was never built to survive the corpus moving, and the corpus always moves.
That is the whole argument of this book in one paragraph. Retrieval is not a one-time index. It is an operating system for a corpus that keeps moving, and the systems that survive are the ones that treat it that way: with inventory, ownership, parsing fidelity, structural chunking, metadata as a control plane, a hybrid stack, query rewriting, permission-before-retrieval, a living lifecycle, and separate evaluation of retrieval and answers.
Key Takeaways
- The standard for a retrieval system that survives contact is one line: a current, authorized, useful corpus, or no trustworthy answer.
- Conclusion: Current, Authorized, Useful should be evaluated through concrete evidence, ownership, and failure modes before production behavior changes.
- Read it with the adjacent Rag That Survives chapters to move from diagnosis to an implementation or release decision.
The frameworks, used not defined
Four frameworks ran through every chapter, and I hope you noticed they were tools, not vocabulary. The CORPUS Readiness Model decided what was even worthy of being indexed before any embedding ran. The Retrieval Failure Chain routed every incident to the link that actually broke, which kept teams from buying a bigger model to fix a chunking bug. The Chunk Boundary Test caught the boundaries that inverted a document's meaning. The Living Index Lifecycle turned "the corpus moved" from a silent drift into a loop with discovery, validation, refresh, and retirement built in.
They reinforce each other. A field you capture in the CORPUS inventory becomes a metadata control that becomes a filter in the failure chain that becomes a lifecycle trigger that becomes an eval assertion. That is not redundancy; it is the same discipline applied at every stage so that the corpus's movement is handled coherently rather than patched in seven disconnected places.
What retrieval cannot do, stated plainly
I promised in the introduction that this book would not claim RAG eliminates hallucination, and I will close on the honest version of that. Good retrieval changes where hallucination comes from. With weak retrieval, the model hallucinates because you gave it the wrong world or nothing useful. With strong retrieval, the remaining hallucination risk is the model adding claims beyond the grounded context, which is why faithfulness and citation matter. Retrieval moves the failure surface from "the model made something up" to "the model used the wrong source" to, eventually, "we knew we did not have a good source and said so." That progression is the goal. You do not reach zero failures. You reach failures that are visible, attributable, and correctable, instead of fluent and invisible.
And retrieval cannot fix a corpus that is wrong. The third row of the diagnostic table, right retrieval and right generation but still-wrong answer because the source itself is stale or incorrect, is not an engineering problem you solve in the retrieval stack. It is a corpus governance problem you solve upstream with ownership, status, and refresh. The most sophisticated retrieval pipeline in the world, pointed at an unmaintained corpus, will faithfully retrieve and cite the wrong answer. The corpus is the system. The retrieval stack just decides which part of it reaches the prompt.
The standard: a single gate
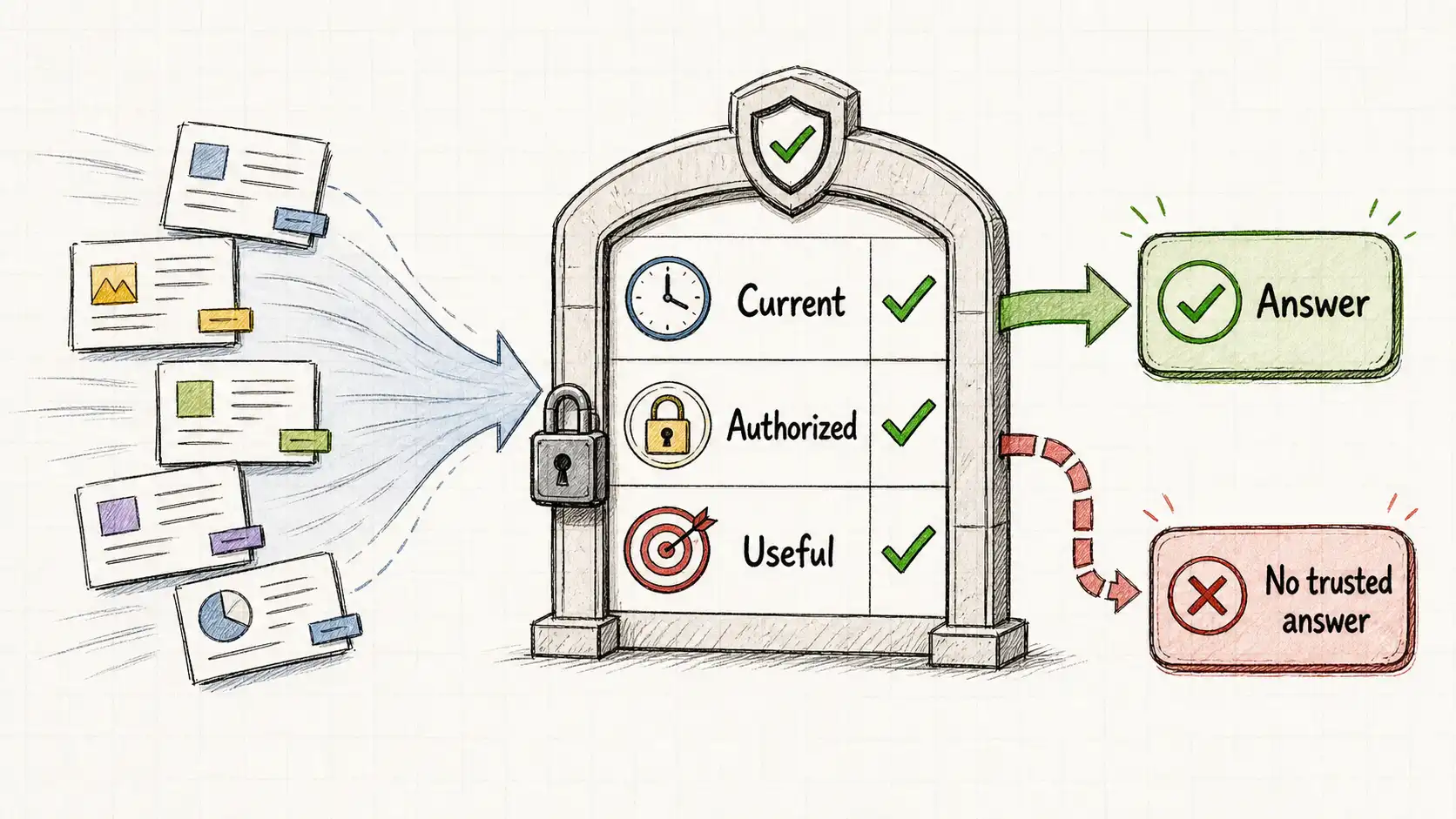
Everything in this book reduces to one gate that every answer should have to pass before it reaches a user. I stated it in the introduction and I will state it as the close, because it is the line I actually use in reviews:
A current, authorized, useful corpus, or no trustworthy answer.
Three conditions, and the answer must clear all three.
Current. The retrieved material is the live version, not a deprecated, superseded, or expired one. If you cannot establish currency through status and freshness, you do not have a trustworthy answer; you have an old one wearing today's confidence.
Authorized. This user is allowed to see this material, enforced before retrieval, not after. If you cannot establish authorization, you do not return a weaker answer; you return nothing, because an unauthorized answer is a breach, not a quality dip.
Useful. The retrieved material actually addresses the question, established by retrieval confidence and relevance, not by the model's fluency. If the best the corpus offers is a weak match, the honest output is "I do not have a confident source for that," not a polished paragraph built on sand.
The discipline of the gate is that failing any condition means no answer, not a degraded one. A retrieval system that survives contact would rather say "I do not know" than describe a button that no longer exists. That willingness to abstain is not a weakness; it is the only thing that makes the answers it does give worth trusting.
The Retrieval That Survives Contact Checklist
Here is the artifact to keep. Walk it before launch, and walk it again whenever the corpus, the users, the permissions, the terms, or the products change, which is to say, continuously.
Corpus (before you index)
- Every source has a named owner and a maintenance expectation.
- Coverage checked against real questions; contamination removed;
excludesources kept out. - Rights cleared; source permission model captured as metadata, not invented.
- Parsing audited by reading output; tables keep header-to-value binding; OCR sources measured.
- Each source tagged with a change frequency.
Retrieval (the stack)
- Chunks pass the Chunk Boundary Test; negations and conditions are not split.
- Hybrid dense plus sparse, fused with RRF; not dense-only on a real corpus.
- Metadata drives both filtering and ranking; current beats stale on ties.
- Query rewriting routes by intent; conversational follow-ups are resolved; exact tokens preserved.
- A reranker lifts the genuinely-best chunk into the packed context, verified against eval.
- Context assembled tightly: deduplicated, budgeted, strongest chunks at the edges, every chunk citable.
Authorization (before retrieval)
- Permission filter applied inside every retriever, before search, never after.
- Tenant isolation tested with adversarial cross-tenant queries on every release.
- Permission metadata refreshed promptly; revocation latency measured.
- Retrieved content treated as untrusted; permissions enforced in the filter, not the model.
Lifecycle (over time)
- Discovery matched to source cadence (event, poll, or reconcile), not one global schedule.
- New content validated in staging before serving.
- Versioning leaves no gap; deprecated content filtered, prior versions addressable.
- Deletion propagates to every store and is verified; hard deletion for privacy/legal erasure.
- Re-embed on vocabulary drift or model upgrade, into a new validated index with atomic cutover.
Evaluation and operations (always)
- Retrieval and answer quality measured separately; recall@k, MRR, nDCG on a gold set.
- Gold eval set built from real production queries, with must-not-retrieve negatives, maintained as labels decay.
- Retrieval trace logged for every query; low-confidence retrieval triggers honest abstention.
- Every incident gets a failure-chain postmortem, a regression test in the gold set, and a hardened lifecycle stage.
Where to go from here
If you read this book to fix a specific fire, you already know which chapter to reread. If you read it to build something new, build it in the order the corpus demands: inventory first, parsing and chunking next, then metadata and the hybrid stack, then permissions before you let a single real user near it, then the lifecycle and the evaluation that keep it honest. Resist the order the tutorials teach, which starts with the vector database and treats everything else as optional. The vector database is the easiest part. The corpus is the system.
The companion volume, Embeddings, Honestly, goes deeper on the mechanics of vectors, similarity, and reranking models if you want the layer beneath this one. This book stayed at the layer above: not how an embedding works, but how a retrieval system keeps working as the world underneath it changes.
The demo will always work. It is supposed to; that is what demos are for. The job, the actual job, is the three weeks after, and the three months after that, when the product gets renamed and the policy changes and someone restricts a document and a customer asks the question that finds the seam. A retrieval system that survives contact meets that question with a current, authorized, useful answer, or with the honesty to say it does not have one. Build for the seam, not the demo.
Key Takeaways
- Retrieval is an operating system for a moving corpus, not a one-time index; build for the three weeks after the demo.
- The four frameworks reinforce each other: inventory feeds metadata feeds the failure chain feeds the lifecycle feeds evaluation.
- Good retrieval moves hallucination from invisible-and-fluent to visible-attributable-correctable; it does not reach zero.
- Retrieval cannot fix a wrong corpus; that is a governance problem solved upstream with ownership, status, and refresh.
- The single gate: current, authorized, useful, or no trustworthy answer; failing any condition means abstain, not degrade.
- Willingness to say "I do not know" is what makes the answers the system does give worth trusting.
- Build in the order the corpus demands (inventory first, vector database last); the corpus is the system.