Rewriting the Question Before You Answer It
The query the user types is rarely the query the corpus can answer, and the gap between them is where most recall is lost.

Read this alongside the RAG That Survives book, the AI-Native thesis, and the full book library when you want the surrounding argument. A product manager dropped a single line into a Slack channel that turned into a two-day investigation: "the assistant can't answer follow-up questions." The example was simple. A user asked "how do I export my data?" and got a perfect answer. Then they asked "can I do it on the free plan?" and the assistant retrieved documentation about free-plan limits in general, none of it about export, and produced a vague non-answer. The user knew what "it" meant. The retriever did not. The string "can I do it on the free plan?" embeds and tokenizes to nothing about export, because the word "export" is not in it. The corpus had the answer. The query, as typed, could not find it.
This is the gap this chapter is about. The query the user types is almost never the query the corpus can best answer. Users are terse, ambiguous, conversational, and they use their own vocabulary. The corpus is verbose, specific, and written in author vocabulary. Query rewriting is the layer that bridges the two, and on a real system it recovers a surprising amount of recall that no amount of retriever tuning can. It is the first link in the Retrieval Failure Chain, query interpretation, and a weak link here cannot be repaired downstream.
Key Takeaways
- The query the user types is rarely the query the corpus can answer, and the gap between them is where most recall is lost.
- Rewriting the Question Before You Answer It should be evaluated through concrete evidence, ownership, and failure modes before production behavior changes.
- Read it with the adjacent Rag That Survives chapters to move from diagnosis to an implementation or release decision.
The user's query is an input, not the query
The instinct in tutorials is to take the user's raw string and feed it straight to the retriever. That treats the user's words as the query. They are not. They are an input from which you construct the query the retriever should actually run. Sometimes the raw string is fine. Often it needs work, and the work falls into a few distinct operations, each fixing a different failure.
The discipline is to name which operation a query needs rather than applying one blunt transformation to everything. Over-rewriting is as harmful as under-rewriting: rewrite a precise query into something fuzzier and you lose the exact tokens that BM25 needed. The goal is the right rewrite for the right query, which means routing first.
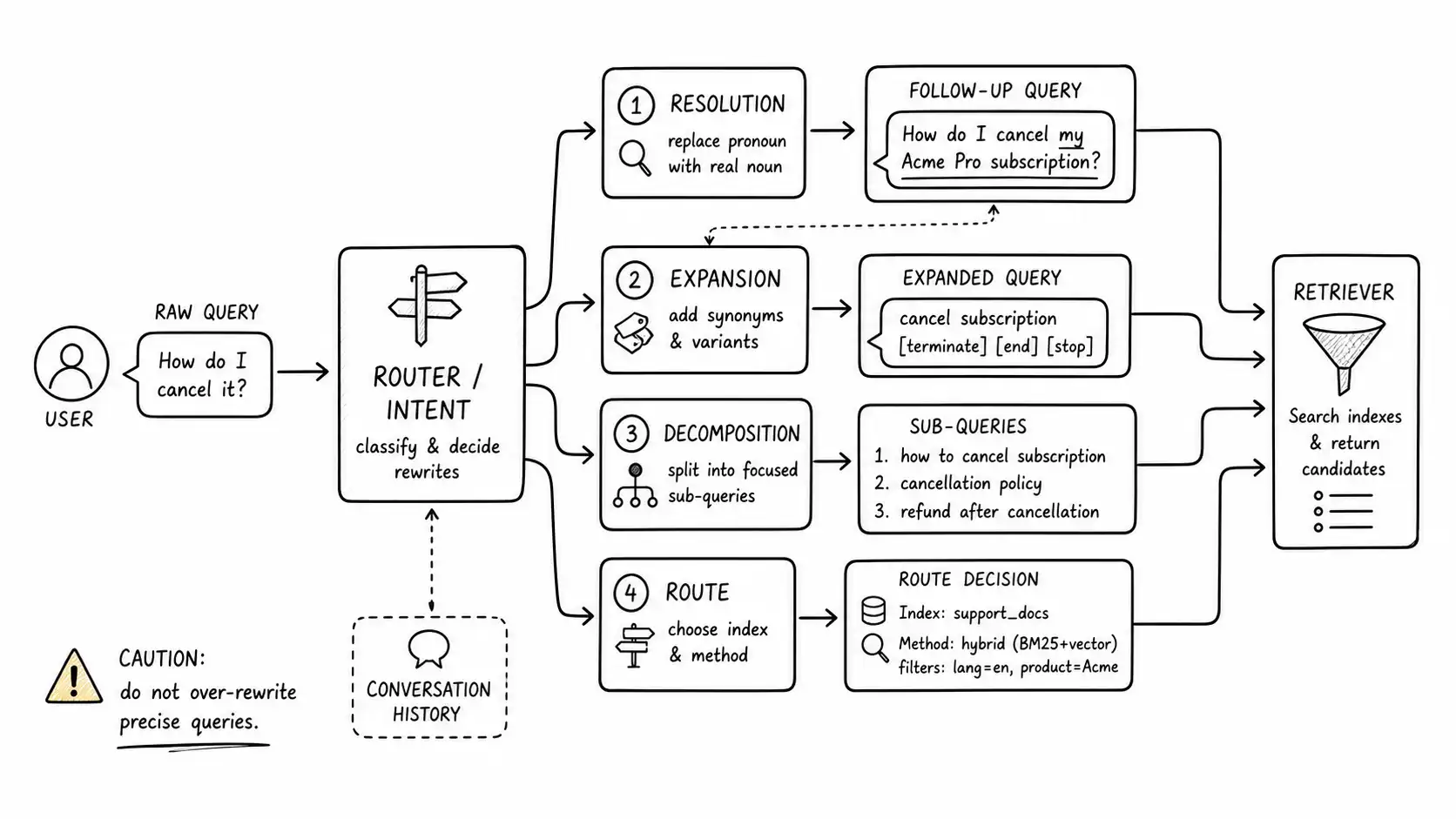
Four operations, four different failures
Resolution (coreference and context). This is the free-plan failure. In a conversation, queries carry implicit context: "it," "that," "the same thing," "what about on mobile." The retriever has no conversation; it sees one string. Resolution rewrites the query to be self-contained by pulling context from the conversation history. "Can I do it on the free plan?" becomes "Can I export my data on the free plan?" Now "export" is in the query and retrieval works. For any conversational interface, this is the highest-value rewrite, because every multi-turn session generates underspecified follow-ups, and without resolution they all fail the same way.
Expansion (vocabulary bridging). This is the refund-versus-pro-rata-credit problem from earlier chapters. The user's vocabulary and the corpus vocabulary differ, so expansion adds terms that bridge them: synonyms, the corpus's preferred terminology, related entities. "Refund" expands to include "credit, termination, cancellation, pro-rata." Expansion directly helps sparse retrieval (more chances for exact-token match) and can help dense retrieval too. The risk is over-expansion diluting the query into a generic blur, so expansion should be targeted, using known synonym mappings and entity dictionaries from your domain rather than scattershot term-stuffing.
Decomposition (multi-part questions). Users ask compound questions: "What's the difference between the Pro and Enterprise plans for SSO and audit logs?" That is really four retrievals: Pro SSO, Enterprise SSO, Pro audit logs, Enterprise audit logs. A single retrieval on the whole string returns a muddle that covers none of the four well. Decomposition splits the query into sub-questions, retrieves for each, and assembles the union. This is also the entry point to multi-hop retrieval, which we will get to: some questions require retrieving one fact to know what to retrieve next.
Routing (intent classification). Not every query should hit the same index or the same retrieval policy. "What's your refund policy" is a policy lookup. "Why is my export failing with ERR_4011" is a troubleshooting query that wants exact-token sparse retrieval and the error-code knowledge base. "How has pricing changed since last year" is a temporal query that wants the changelog with recency ranking. Routing classifies intent and selects the index, the retrieval method weighting, the metadata filters, and the rewrite operations to apply. Routing is what prevents you from running one generic policy against wildly different query types.
A query rewriting policy
Because over-rewriting and under-rewriting are both real failures, I write down an explicit policy rather than letting an LLM rewrite everything by reflex. Here is the policy shape, which routes first and applies only the operations a query needs.
| Query signal | Route / intent | Rewrite operations applied | Retrieval adjustment |
|---|---|---|---|
| Follow-up in a conversation (pronouns, "what about") | Conversational | Resolution (coreference from history) | Standard hybrid |
| Contains an exact code / version / SKU | Troubleshooting / lookup | None, or minimal; preserve exact tokens | Weight sparse higher |
| Natural-language paraphrase, single topic | Knowledge lookup | Expansion (targeted synonyms/entities) | Weight dense higher |
| Compound / multi-part | Complex | Decomposition into sub-queries | Retrieve per sub-query, union |
| Temporal ("changed," "since," "latest") | Temporal | Light expansion | Recency boost, changelog source |
| Vague / very short ("error", "billing") | Ambiguous | Clarify with user OR expand cautiously | Widen candidate set |
Two rows deserve emphasis. The exact-code row says do minimal rewriting: if the user typed "ERR_4011," expanding or paraphrasing it can destroy the literal token that sparse retrieval needs, so you preserve it and lean on BM25. The vague-query row says the right move is sometimes to ask the user a clarifying question rather than to guess; a system that asks "do you mean billing setup, billing errors, or billing history?" beats one that confidently retrieves the wrong billing topic. Knowing when not to answer yet is part of surviving contact.
HyDE: generate a hypothetical answer to retrieve the real one
There is a clever rewriting technique worth understanding because it works well for a specific case. HyDE (Hypothetical Document Embeddings) flips the retrieval direction. Instead of embedding the short query and searching for documents, you first ask a language model to generate a hypothetical answer to the query, then embed that hypothetical answer and search with it. The intuition is that a query and a document live in different shapes: a query is a short question, a document is a passage of prose, and they do not always sit near each other in embedding space. A hypothetical answer is shaped like a document, so it lands closer to the real documents that answer the query. Gao et al. showed this improving zero-shot dense retrieval without any relevance labels.
HyDE is powerful and it has a sharp edge, which is exactly the theme of this book: the hypothetical answer can be wrong, and if it is wrong in a confident, specific way, it can steer retrieval toward documents that match the hallucination rather than the truth. On a corpus that drifts, the model may hypothesize an answer based on outdated knowledge and retrieve the stale document that confirms it. So HyDE is a recall tool for cases where the query-document shape gap is the problem (terse queries against verbose corpora, zero-shot domains), not a default to apply everywhere, and it pairs best with strong reranking and freshness filtering to catch when the hypothetical pulled the wrong world.
Multi-hop: when one retrieval is not enough
Some questions cannot be answered by a single retrieval no matter how well you rewrite, because answering them requires a fact you have to retrieve first. "What is the refund policy for the plan that the customer on invoice 8841 is on?" You cannot retrieve the refund policy until you know the plan, and you cannot know the plan until you retrieve the invoice. This is multi-hop retrieval: retrieve, read, use the result to form the next query, retrieve again.
Multi-hop is decomposition with a dependency: the sub-queries are sequential, not parallel. It is powerful and it is expensive and risky, because errors compound across hops. A wrong first hop guarantees a wrong second hop, and the model will narrate the chain confidently. Use multi-hop deliberately, with a bounded number of hops, and log every hop's retrieval so you can see where a multi-hop chain went off the rails. The same Retrieval Failure Chain applies to each hop; you are just walking it more than once.
Rewriting and the failure chain
Query rewriting sits at the very first link of the Retrieval Failure Chain, and that position is why it matters disproportionately. If query interpretation is wrong, every downstream stage is operating on the wrong query. The best embedding model, the best hybrid stack, the best reranker, all faithfully retrieve and rank documents for a question the user did not ask. The free-plan failure that opened this chapter never reached reranking; it failed at link one, and reranking the wrong candidates better would not have helped.
This is also why query rewriting is one of the highest-use and most under-instrumented parts of a real system. Log the raw query and the rewritten query together (as the trace schema from chapter two already does, with raw_query and rewritten_query fields). When you investigate a miss, the first thing to check is whether the rewrite was correct, because a bad rewrite is invisible if you only look at retrieval results: the retriever did its job perfectly on a query that was already wrong.
Practical exercise
Collect twenty real misses where users complained the answer was off-topic or incomplete. For each, look at the raw query and ask which of the four operations it needed: did it carry unresolved conversational context (resolution), use different vocabulary than the corpus (expansion), pack multiple questions into one (decomposition), or belong to a different intent than your default policy assumed (routing)? Tally which operation is missing most often. That tally is your priority order. In most conversational systems, resolution wins by a wide margin, because every follow-up question fails the same way and there are a lot of follow-up questions.
Summary
The query a user types is an input, not the query to run; the gap between user vocabulary and corpus vocabulary, plus unresolved conversational context, loses recall that no retriever tuning can recover. Four distinct operations fix four distinct failures: resolution makes conversational follow-ups self-contained, expansion bridges vocabulary, decomposition splits compound questions, and routing classifies intent to select the right index, method, and filters. Route first and apply only the operations a query needs, because over-rewriting destroys exact tokens and dilutes precise queries. HyDE helps when the query-document shape gap is the problem but can steer toward a hallucinated or stale world, and multi-hop handles dependent questions at the cost of compounding errors. Rewriting is the first link in the failure chain, so a bad rewrite is invisible downstream; log raw and rewritten queries together and check the rewrite first.
Key Takeaways
- The user's words are an input from which you construct the query; do not feed the raw string to the retriever by reflex.
- Resolution (coreference from conversation history) is the highest-value rewrite for any multi-turn interface.
- Expansion bridges user-vs-corpus vocabulary but must be targeted; over-expansion dilutes the query.
- Route by intent first, then apply only the operations a query needs; preserve exact tokens for code/version lookups.
- For vague queries, asking a clarifying question can beat guessing; knowing when not to answer is part of surviving contact.
- HyDE closes the query-document shape gap but can retrieve a hallucinated or stale world; pair it with reranking and freshness.
- Rewriting is the first link in the failure chain; log raw and rewritten queries and check the rewrite before blaming retrieval.