Where the Answer Begins
Most RAG failures are retrieval failures wearing a model's clothes, and the Retrieval Failure Chain tells you which link broke.

Read this alongside the RAG That Survives book, the AI-Native thesis, and the full book library when you want the surrounding argument. A senior engineer on a customer's team opened the incident review with a slide that said, in forty-point font, "The model hallucinated." Under it was a screenshot of the assistant inventing a refund policy that did not exist. The room nodded. Someone suggested a more capable model. Someone else suggested a stricter system prompt. The proposed fix was to spend money and tighten instructions.
I asked one question: what did we actually put in the context window for that query? Nobody knew. We did not log retrieved chunks. We logged the prompt template and the final answer, but the part in the middle, the part that determined everything, was invisible. We turned on chunk logging, reproduced the query, and found the answer in thirty seconds. The retriever had pulled a 2019 blog post about a promotional refund campaign that ran for one quarter. The model did not hallucinate. It faithfully summarized a real document that should not have been in the corpus and definitely should not have ranked first. The model was the only honest component in the pipeline.
This chapter is about drawing the line between retrieval and generation correctly, because almost every team draws it in the wrong place, and the wrong place costs you weeks.
Key Takeaways
- Most RAG failures are retrieval failures wearing a model's clothes, and the Retrieval Failure Chain tells you which link broke.
- Where the Answer Begins should be evaluated through concrete evidence, ownership, and failure modes before production behavior changes.
- Read it with the adjacent Rag That Survives chapters to move from diagnosis to an implementation or release decision.
The two questions are not the same question
A RAG system answers by chaining two distinct capabilities. First, retrieval: given a user's question, find the right material from the corpus. Second, generation: given that material, produce a grounded answer. These are different problems with different failure modes, different metrics, and different fixes. When you collapse them into one black box labeled "the AI," you lose the ability to debug.
The original RAG formulation in Lewis et al. makes this separation explicit: a retriever selects passages, and a generator conditions on them. Everything downstream depends on the retriever bringing back the right world. If retrieval succeeds and generation fails, you have a prompting or model problem. If retrieval fails, the most capable model in the world will only help you produce more fluent wrongness.
Here is the diagnostic discipline I want to install. Before you touch a prompt, before you consider a bigger model, you answer one question: did the correct answer exist in the retrieved context at all? There are only three possibilities, and each points to a different team and a different fix.
| Did the answer reach the context? | Did the answer reach the user? | Diagnosis | Owner |
|---|---|---|---|
| No, correct material not retrieved | No | Retrieval failure | Retrieval / data engineering |
| Yes, correct material retrieved | No, model ignored or contradicted it | Generation failure | Prompt / model |
| Yes | Yes, but answer still wrong | Corpus failure (the source itself is wrong or stale) | Content / corpus owner |
That third row is the one teams forget. Sometimes retrieval works perfectly and the model answers perfectly and the answer is still wrong, because the document it cited is itself out of date or incorrect. That is not a model problem or a retrieval problem. It is a corpus governance problem, and you fix it upstream by retiring or correcting the source. We will return to this in the chapters on metadata and freshness, but notice now that you cannot even see it unless you have separated the layers.
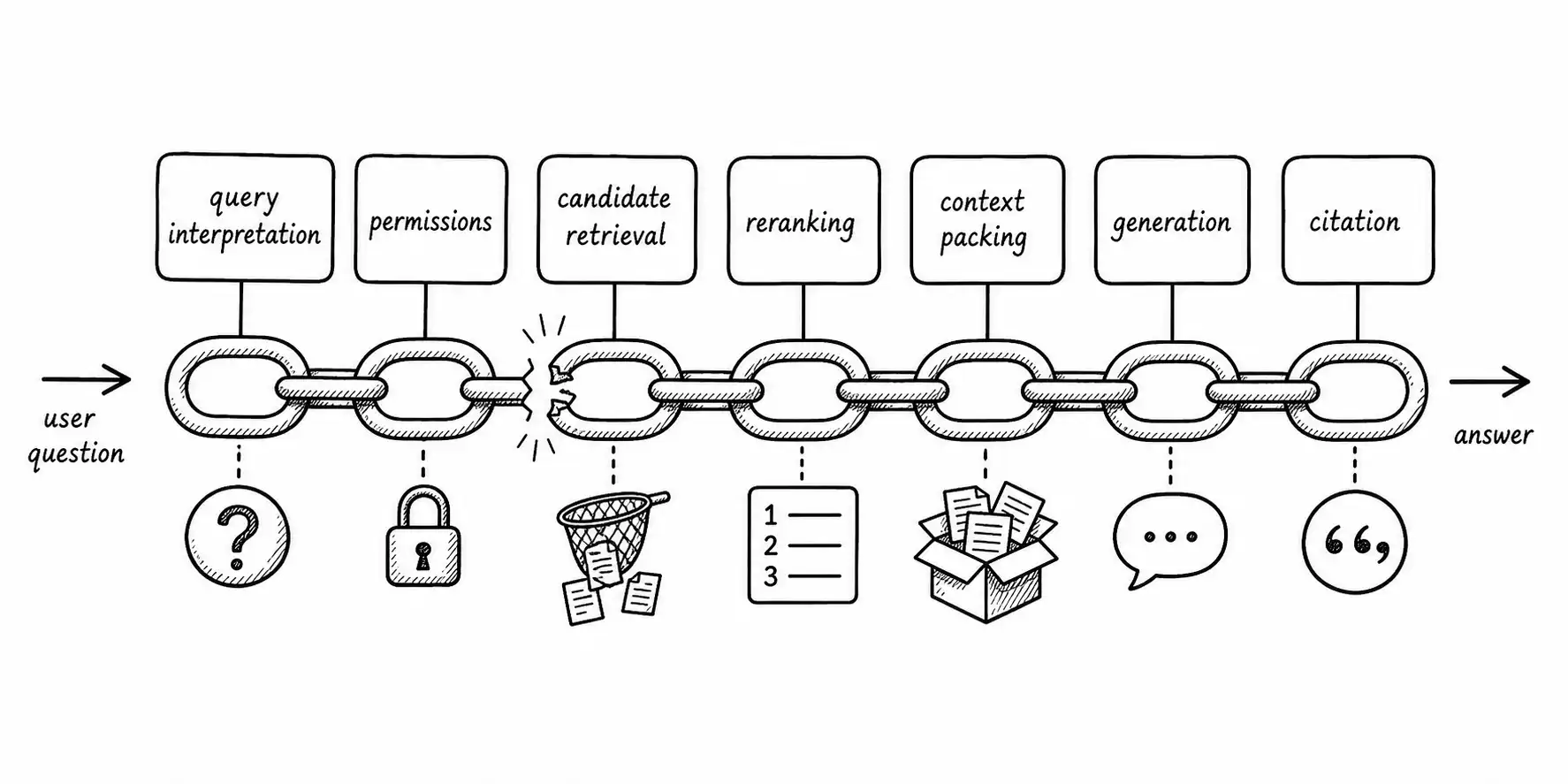
The Retrieval Failure Chain
Retrieval is not a single step that either works or does not. It is a chain of stages, and a failure at any link produces a bad answer that looks identical at the output. The Retrieval Failure Chain is the map I walk during every incident:
- Query interpretation. Did we understand what the user was asking? A user types "reset," meaning password reset, and the retriever treats it as a generic term that matches factory resets, cache resets, and a release note titled "Reset of Q3 goals."
- Permissions. Did we restrict the candidate set to what this user is allowed to see, before retrieval, not after? A permission failure here is a security incident, not a quality bug.
- Candidate retrieval. Did the index surface the right documents in the top candidates at all? If the correct chunk is not in the top 100 candidates, nothing downstream can rescue it.
- Reranking. Among the candidates, did we order them so the most relevant rose to the top of the budget we send to the model?
- Context packing. Did we fit the right material into the context window without diluting it, truncating it, or burying it where the model ignores it?
- Generation. Given good context, did the model produce a faithful answer?
- Citation. Did we attribute the claim to the source it actually came from, so a human can verify it?
The discipline is to walk the chain in order and stop at the first broken link. You do not jump to "the model is bad" until you have ruled out links one through five. In my experience the break is in link three or four far more often than in link six.
A worked walk through the chain
Let me make this concrete with the refund-policy incident. A user asked: "What is your refund policy for annual plans?"
Query interpretation. The query is reasonable but underspecified. "Refund policy" matches a lot. We did no rewriting, so the raw string went to retrieval. Link one was weak but not broken.
Permissions. No filter applied. The user was an external customer; the corpus included internal pricing experiments. Link two was broken in a way we had not noticed, because the wrong document happened to be public-flagged by accident. We will spend a whole chapter on why permission belongs before retrieval.
Candidate retrieval. Pure dense retrieval. The 2019 promotional post was semantically very close to "refund policy annual plans" because it used those exact phrases repeatedly. The current refund policy, written in dry legal language, said "termination and pro-rata credit" and never used the word "refund." So the correct document barely made the candidate set, and the stale one dominated. This is a classic vocabulary-mismatch failure that pure dense retrieval is prone to and that sparse methods like BM25 would have at least partially caught, because the legal doc did contain the literal token "annual." Link three was broken.
Reranking. We had no reranker. The top dense hit went straight into the prompt. Link four did not exist, so it could not save us.
Context packing. We packed the top three chunks. The stale promo was chunk one. Link five faithfully delivered the wrong material.
Generation. The model summarized chunk one accurately. Link six did its job.
Citation. We cited the 2019 post, which at least meant a human could eventually catch it. Link seven was our only piece of luck.
Notice that the slide blaming the model was wrong about six of the seven links. The actual breaks were in interpretation, permissions, candidate retrieval, and reranking. A bigger model fixes none of those. This is why the chain matters: it routes the fix to the right place.
Retrieval failures hide as model failures because of fluency
There is a structural reason teams misdiagnose this. A modern generator is fluent regardless of whether its context is correct. Give it the wrong document and it produces a confident, well-formatted, plausible answer. Give it the right document and it produces a confident, well-formatted, plausible answer. The output looks the same. The fluency is constant; the truth is not. Humans read fluency as competence, so a confidently-wrong answer reads as "the model is smart but mistaken" rather than "we fed it the wrong page."
This is also why long context windows do not rescue you the way people hope. The intuition is: if retrieval is unreliable, just stuff more documents in and let the model sort it out. But Liu et al.'s "Lost in the Middle" showed that models use information at the beginning and end of long contexts far better than information buried in the middle, and performance degrades as context grows. Dumping fifty chunks does not give the model fifty chances to find the answer. It gives the model a haystack and hides your needle in the middle of it. Good retrieval is not optional even with a million-token window. You still have to put the right thing in the right place.
Instrument the middle or stay blind
You cannot debug what you do not log. The single highest-use change most teams can make on day one is to record, for every query, the retrieval trace: what was retrieved, with what scores, in what order, and which chunks actually made it into the final prompt. Here is a minimal trace schema that has paid for itself many times over.
{
"trace_id": "rtq-8f21c0",
"timestamp": "2026-06-13T09:41:22Z",
"user_id_hash": "u_3b9a",
"tenant_id": "acme",
"raw_query": "what is your refund policy for annual plans",
"rewritten_query": "annual subscription refund and termination credit policy",
"permission_filter": { "tenant": "acme", "visibility": ["public", "acme_internal"] },
"candidates": [
{ "chunk_id": "doc_4821#c3", "source": "blog/2019-promo", "retriever": "dense", "score": 0.83, "status": "stale", "rank": 1 },
{ "chunk_id": "doc_9930#c1", "source": "legal/refund-policy-v4", "retriever": "bm25", "score": 11.2, "status": "current", "rank": 7 }
],
"reranked_top_k": ["doc_9930#c1", "doc_4821#c3"],
"packed_into_prompt": ["doc_9930#c1"],
"answer_cited": ["legal/refund-policy-v4"]
}With a trace like this, the refund incident is solved before the meeting starts. You can see that the stale doc outranked the current one, that no reranker reordered them, and that the status field already flagged the promo as stale. Every field here does work in a later chapter: status and source come from metadata, permission_filter comes from permission-aware retrieval, rewritten_query comes from query rewriting, reranked_top_k comes from reranking, and the whole record is what makes retrieval evaluation possible. The trace is the spine that connects the rest of the book.
A decision table for "the AI gave a bad answer"
When a stakeholder reports a bad answer, resist the urge to theorize. Run this table against the trace.
| Symptom in the trace | Broken link | First fix to try |
|---|---|---|
| Correct chunk not in candidates at all | Candidate retrieval | Add sparse/hybrid retrieval; check chunking and vocabulary mismatch |
| Correct chunk in candidates but ranked low | Reranking | Add or tune a cross-encoder reranker |
| Correct chunk retrieved but not packed | Context packing | Increase budget, deduplicate, reorder by position |
| Correct chunk packed but ignored by model | Generation | Tighten prompt, reduce distractors, check "lost in the middle" position |
| Wrong chunk is a document user should not see | Permissions | Move permission filter before retrieval |
| Right chunk packed and used, answer still wrong | Corpus | Source is stale or incorrect; retire or correct it |
| Query matched the wrong sense of an ambiguous term | Query interpretation | Add query rewriting / intent routing |
This is not theoretical. It is the literal triage I run, and it turns a two-hour blame session into a fifteen-minute root cause. Print it.
Practical exercise
Take one real bad answer from your own system this week. Before reading the next chapter, do exactly three things. First, retrieve the chunks that the system used for that query and read them yourself. Second, find the correct answer in your corpus by hand and check whether it was in the candidate set at all. Third, label the broken link using the chain above. If you cannot do step one because you are not logging retrieved chunks, that is your finding: you are flying blind, and instrumenting the middle is the first thing to fix.
Summary
The line between retrieval and generation is the most important line in your system, and almost everyone draws it wrong. Bad answers are usually retrieval failures wearing the model's clothes, because fluency stays constant while truth does not. The Retrieval Failure Chain gives you a stage-by-stage map to find the real break, and a trace log of what was retrieved turns guesswork into diagnosis. Bigger models and longer contexts do not fix retrieval problems; they make wrong answers more fluent and bury needles in larger haystacks.
Key Takeaways
- Separate retrieval from generation before debugging; they have different failure modes, metrics, and owners.
- Ask first whether the correct material reached the context at all. Three outcomes, three different fixes.
- Walk the Retrieval Failure Chain in order and stop at the first broken link: interpretation, permissions, candidates, reranking, packing, generation, citation.
- Fluency hides retrieval failure. A confident, well-formatted answer is not evidence the context was correct.
- Long context does not rescue weak retrieval; models are "lost in the middle" and degrade as you add distractors.
- Log the retrieval trace for every query. Without the middle instrumented, you are guessing.