Conclusion: Fast at Converting Noise into Testable Claims
A mature organization is not the one that ignores hype or the one that chases it, it is the one that converts noise into testable claims faster than anyone else.

Read this alongside the First Principles AI book, the AI-Native thesis, and the full book library when you want the surrounding argument. I want to end by retiring a false dichotomy that runs through every conversation about AI hype, because most of the bad decisions I have watched came from people trapped inside it. The dichotomy is: are you a believer or a skeptic. The believers chase. The skeptics dismiss. Each side thinks the other is the problem, and each side is partly right about the other, which is why the argument never ends.
The mature position is neither, and it is not a moderate blend of the two either. It is a third thing entirely: speed at conversion. A mature organization is fast at converting noise into testable claims. It does not chase the noise and it does not dismiss the noise; it processes the noise, quickly, into questions it can answer with cheap tests, and then it answers them. The believer reacts to volume by moving. The skeptic reacts to volume by refusing to move. The mature organization ignores volume entirely and reacts to evidence, which it manufactures itself, on a clock it controls, faster than its competitors can.
That is the whole book in one reframing. Everything in it, the SANE Filter, the decomposition sheet, the demo and benchmark chapters, the churn accounting, the hype budget, the reversibility ladder, the release runbook, the timing calculation, is machinery for one purpose: to make your organization fast at turning a viral claim into a tested answer. Speed at conversion is the durable capability. The specific models, categories, and benchmarks are weather. The conversion machine is climate.
Why speed at conversion is the real moat
It is worth saying plainly why this, and not any particular technology bet, is the thing worth building, because it is counterintuitive in a field obsessed with which model is best.
The models are converging and commoditizing. Open-weight models closed most of the gap to closed models in a single year, and the cost of a given capability fell by orders of magnitude in two (Stanford HAI, 2025 AI Index Report). In a world where capability is abundant and cheap and getting cheaper, having access to the best model is not a durable advantage, because everyone will have access to a nearly-as-good model next quarter for a tenth the price. The advantage moves to whoever can figure out, fastest and most cheaply, which of the abundant capabilities actually creates value in their specific operation. That is a conversion-speed advantage, not a technology advantage, and unlike a technology advantage it compounds, because each conversion teaches the organization to convert the next one faster.
The DORA research pointed at the same truth from the engineering side: the gains from AI accrued to organizations whose systems could absorb change, with review, validation, and observability already in place, and evaporated for organizations that bolted AI onto an unprepared system (DORA, 2024 Accelerate State of DevOps Report). The capability was available to everyone. The ability to absorb it was not, and that ability, not the capability, was what separated the performers. Build the absorber. The capabilities will keep arriving on their own.
The First Principles Hype Cycle Checklist
Here is the checklist I promised, the thing to pin where the team can see it, run against any incoming AI claim. It is deliberately short, because a checklist you do not run is decoration. Each item maps to a chapter, so you know where to go deeper.
FIRST PRINCIPLES HYPE CYCLE CHECKLIST
When a new AI claim arrives, before changing anything:
[ ] 1. RESTATE it in your own words, no vendor adjectives, no category nouns.
(Translate the claim. Replace the noun with the underlying job.)
[ ] 2. SPLIT short-run vs long-run (Amara). Which version governs THIS decision?
(Overhyped now AND underhyped later can both be true.)
[ ] 3. RUN the SANE Filter (30 min). Scope, Assumptions, Numbers, Exposure.
Verdict: DROP / PARK (with trigger) / PURSUE. Most should not be PURSUE.
[ ] 4. If PURSUE, DECOMPOSE: capability, cost, latency, integration,
reliability, governance, adoption, switching cost. Find the binding constraint.
[ ] 5. DEMAND your own number. Offline replay on YOUR data beats any benchmark.
For multi-step claims: measure per-step rate, multiply, check end-to-end.
[ ] 6. CHECK the hype budget. Is there a slot? What comes OUT to make room?
No "and also." The exchange rule is non-negotiable.
[ ] 7. PLACE it on the reversibility ladder. Match commitment size to reversibility.
Never let a demo justify a core or irreversible rung.
[ ] 8. SET the trigger and the kill condition IN WRITING, before you start.
(When does WATCH become EXPERIMENT? When does a pilot get killed?)
[ ] 9. WEIGH the timing asymmetry. Cost of too early vs too late, for US.
Engineer the early cost down before deciding you must wait.
[ ] 10. UPDATE beliefs by evidence STRENGTH, not vividness. Then act, or wait,
and do not re-litigate until the trigger fires or the schedule says so.If you run only items 1, 3, and 6 on every claim, you will already be ahead of most organizations, because those three, restate, SANE, and the exchange rule, are the ones that stop the reflexive reprioritization before it starts. The rest is depth for the claims that survive the first three.
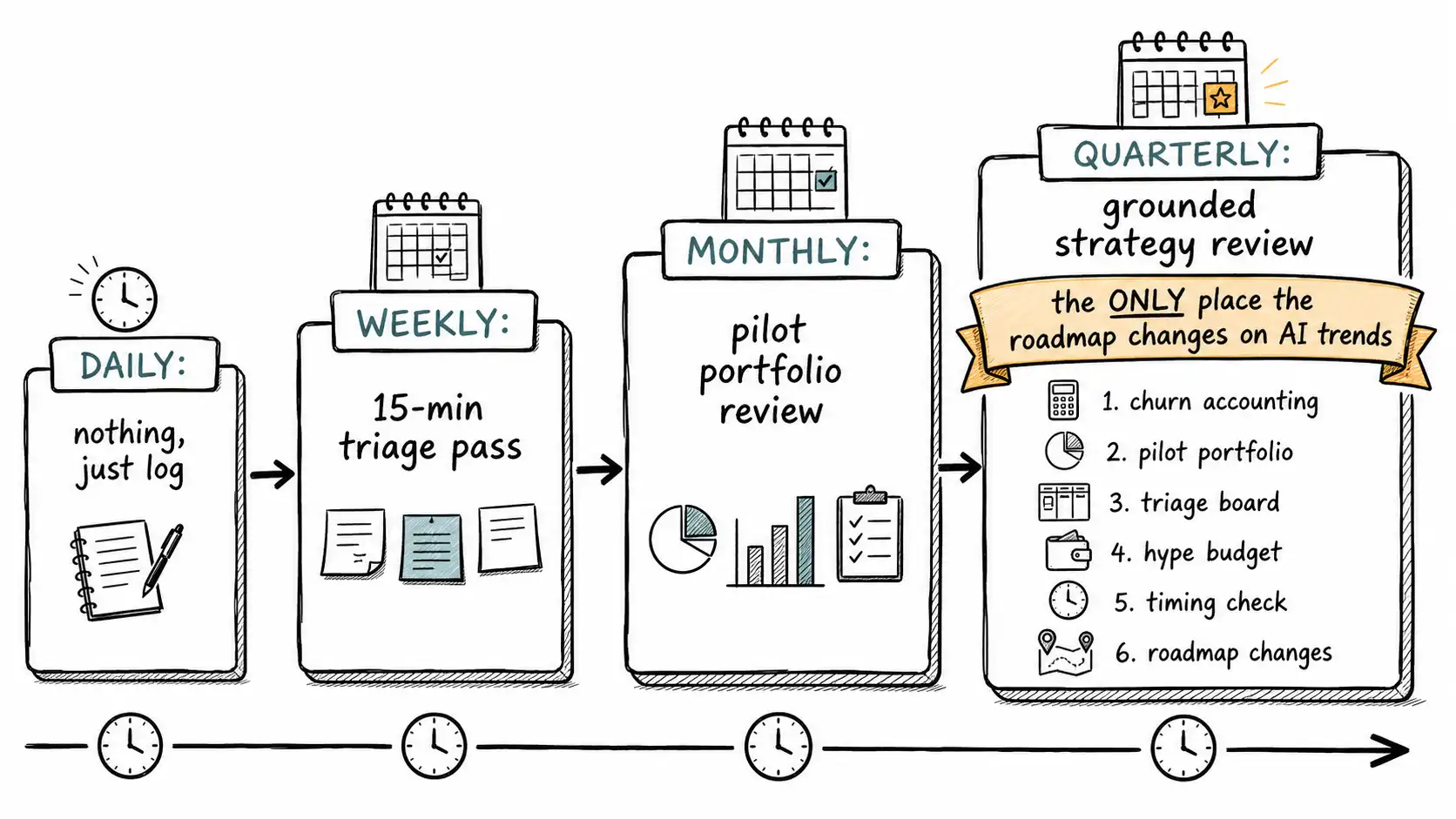
The grounded AI operating cadence
A checklist handles individual claims. An operating cadence handles the steady stream of them, so that staying grounded is a routine rather than a heroic act of resistance each time something goes viral. Here is the cadence I run, and the key design principle is that it absorbs claims on a clock you set, not the clock the feed sets.
Daily, nothing. This is deliberate and it is the hardest part. There is no daily AI ritual, no morning scan of releases that the team is expected to react to. Claims arrive daily; they are logged, not processed. Processing happens on the cadence below. A team that processes claims daily is a team the feed controls.
Weekly, a fifteen-minute triage pass. Someone owns the Trend Triage Board and spends fifteen minutes a week sorting the week's logged claims into adopt, experiment, watch, ignore, avoid, checking whether any watch triggers fired, and updating pilot tracker statuses. Fifteen minutes, because triage is sorting, not deciding. Most weeks nothing moves, and that is success.
Monthly, a pilot portfolio review. Look at the active pilots: which hit their evidence target and should be promoted up the ladder, which hit their kill condition and should be stopped, blamelessly, as the process working. Confirm the hype budget slots are being used, not just occupied. This is where options get exercised or expired.
Quarterly, a grounded AI strategy review. This is the real decision meeting, and it has a fixed agenda, below. It is the only meeting where the roadmap is allowed to change in response to the quarter's accumulated evidence, which means trends cannot reprioritize the roadmap between these meetings, which is the entire point. The roadmap changes quarterly, on evidence, not weekly, on hype.
QUARTERLY GROUNDED AI STRATEGY REVIEW ---- agenda (90 min)
1. CHURN ACCOUNTING (10 min)
Sum capacity, dead-integration maintenance, idle contracts spent on
chases that shipped nothing. Make the tax visible before authorizing more.
2. PILOT PORTFOLIO (20 min)
Promotions up the ladder, kills (celebrate them), option value review.
Are we buying enough cheap options? Killing enough cleanly?
3. TRIAGE BOARD REVIEW (15 min)
Re-sort dispositions. Which triggers fired or got closer? What moved
from WATCH toward EXPERIMENT? What should now be IGNORED or AVOIDED?
4. HYPE BUDGET REALLOCATION (15 min)
Reset slots across core / adjacent / frontier for next quarter.
Apply the exchange rule to any new bets: what comes out.
5. TIMING ASYMMETRY CHECK (15 min)
For the bets in flight: are we still right on early-vs-late?
Has anything become more reversible or more urgent?
6. ROADMAP CHANGES (15 min)
The ONLY place the roadmap changes on AI trends. Evidence-driven only.
Every change must name the test that triggered it.The cadence is what makes the rest of the book sustainable. Without it, every framework becomes a thing you have to remember to apply under pressure, and under pressure people revert to the flinch. With it, the frameworks are baked into a calendar, the calendar absorbs the claims, and staying grounded stops requiring willpower. The discipline lives in the cadence, not in the person, which is the only way discipline survives a busy quarter and a charismatic founder forwarding a video.
A last word on the motif
The motif this book returned to in every chapter was: new claims are allowed into the room, they are not allowed to run the meeting. I have tried to give you the machinery that makes that sentence true in practice rather than aspirational. The SANE Filter is the door the claim enters through. The decomposition sheet and the replay are how you question it once it is in the room. The hype budget and the reversibility ladder are how you decide whether to give it any of your scarce attention and how much you are willing to commit. The cadence is what keeps it from grabbing the gavel between meetings.
The organizations that thrive in this period will not be the ones with the best AI access, because that is converging toward everyone. They will be the ones that built the conversion machine: fast, cheap, disciplined translation of noise into testable claims, and testable claims into evidence, and evidence into reversible-where-possible decisions, on a clock they control. That is not a technology. It is an operating discipline, and unlike any model, it does not depreciate when the next release ships. It compounds.
Let the next quarter bring its new AI claim. You know what to do with it now. Restate it, split it, filter it, decompose it, demand your own number, check the budget, place it on the ladder, set the trigger, weigh the asymmetry, update on strength not vividness. Then go back to the work you already decided mattered, and let the cadence pick the claim up at the right time, if it ever earns one. The claim is welcome in the room. The meeting is still yours.
Key Takeaways
- Retire the believer-versus-skeptic dichotomy. The mature position is a third thing: speed at converting noise into testable claims. React to evidence you manufacture, not to volume.
- Speed at conversion is the durable moat. Models are converging and commoditizing; the ability to absorb capability into your operation is not, and it compounds with each conversion.
- The First Principles Hype Cycle Checklist runs any claim through ten steps. Items 1, 3, and 6, restate, SANE, and the exchange rule, alone put you ahead of most organizations.
- The grounded operating cadence is daily nothing, weekly triage, monthly portfolio review, quarterly strategy review. The roadmap changes only quarterly, on evidence, never weekly on hype.
- Make churn visible at every quarterly review by summing its hidden cost before authorizing the next chase. Celebrate clean pilot kills as the process working.
- The discipline must live in the cadence and the artifacts, not in a person's willpower, because willpower reverts to the flinch under pressure and a charismatic founder.
- New claims are allowed into the room. They are not allowed to run the meeting. The machinery in this book is what makes that true in practice rather than in aspiration.