How to Slow a Claim Down
Slowing a claim is not delay, it is the work of converting a feeling of urgency into a question you can answer.

Research spine: this chapter stays grounded in Stanford HAI, 2025 AI Index Report and DORA, 2024 Accelerate State of DevOps Report, then applies that evidence to the operating judgment in the book. Read this alongside the First Principles AI book, the AI-Native thesis, and the full book library when you want the surrounding argument. A claim arrives at the speed of a notification. A decision, done well, moves at the speed of evidence. The entire discipline of this book lives in the distance between those two speeds, and this chapter is the machinery for crossing it.
I want to be careful about the word "slow," because it is easily misread as "wait" or "be cautious" or "study it to death." That is not what I mean. Slowing a claim down is an active, time-boxed process with an output. The output is a testable question and a cheap test for it. You can do the first pass in thirty minutes. You are not slowing the work. You are slowing the claim, so that it stops generating diffuse urgency and starts generating a specific, answerable inquiry. A claim that has been slowed down has been converted from a feeling into a task.
Let me give you two instruments for this, in increasing depth. The first is for the first half hour after a claim arrives. The second is for the claims that survive the first.
The SANE Filter
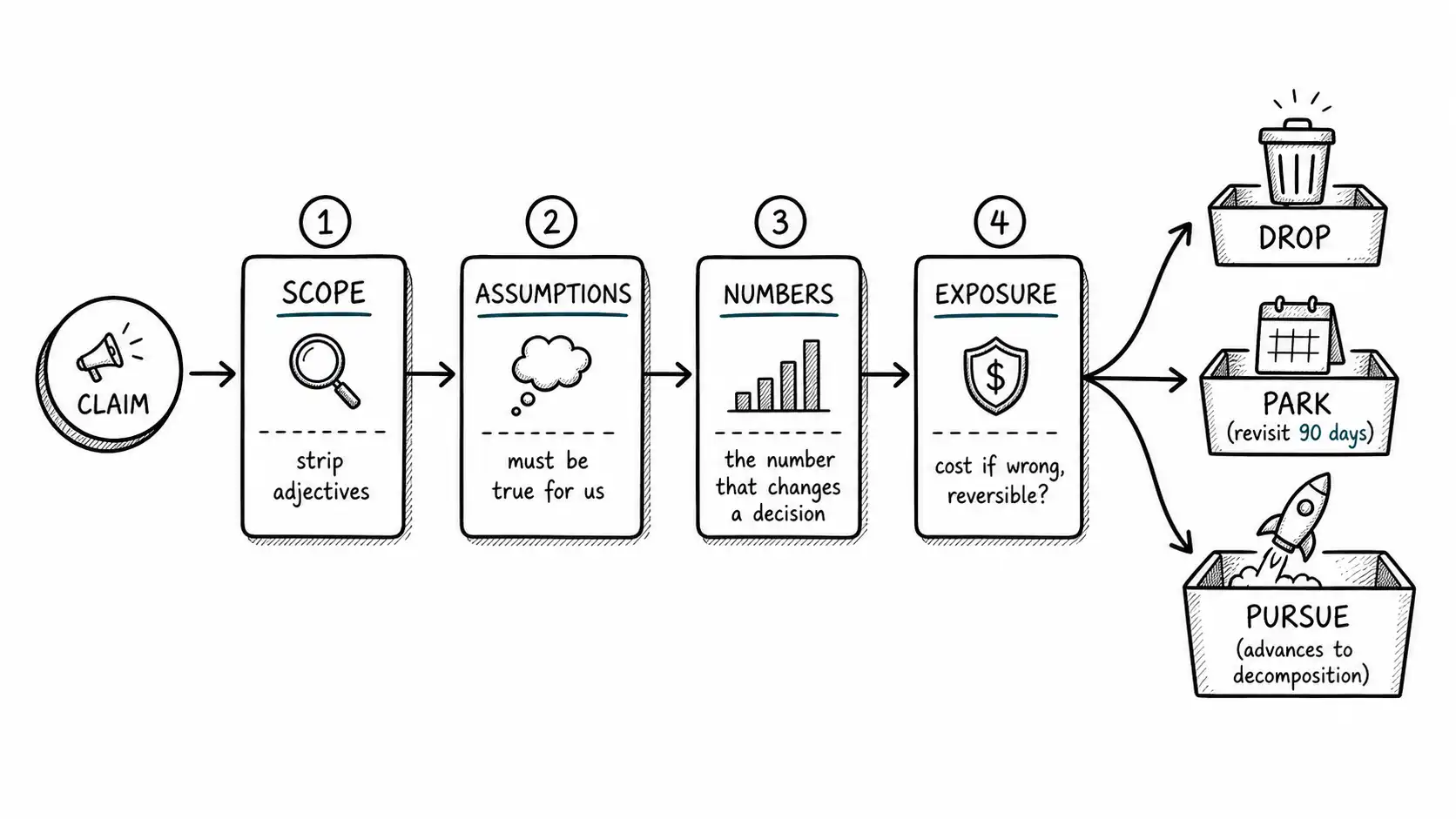
The SANE Filter is a thirty-minute gate. Its job is not to evaluate the claim. Its job is to decide whether the claim deserves evaluation at all, and to capture just enough structure that if it does, the next stage starts warm. SANE stands for Scope, Assumptions, Numbers, Exposure.
Scope. What, exactly, is being claimed, and for whom? Strip the adjectives and write one sentence in your own words. The discipline here is to name the boundary the claim is implicitly drawing. "This model writes production code" has a scope. Is it any code, or boilerplate? In any language, or the three the benchmark used? For a senior engineer who can review it, or for someone who cannot tell when it is wrong? Most inflated claims survive only because their scope is left undefined, so that the listener fills it in with the most generous possible reading. Naming the scope is the single highest-use thirty seconds in the whole process.
Assumptions. What must be true for the claim to matter to us specifically? Not to the world, to us. The agent demo assumes you have the tool integrations it calls, that your data is in a shape it can read, that your workflows tolerate the failure rate, that your customers will accept an automated step. Write the assumptions down as a list. You are not yet deciding whether they hold. You are surfacing them so they stop hiding.
Numbers. What numbers would the claim have to hit to change a decision, and do we have any of them yet? If the answer is "we have none and could not get any cheaply," that itself is a finding: the claim is currently a vibe, not a candidate. If we could get the numbers with a small test, name the number and the test. The point of this step is to refuse to argue about a claim in the absence of any quantity. "It's amazing" is not a number. "It resolves 40 percent of tier-one tickets at under two dollars each" is a number, and it is the kind of thing you can go measure.
Exposure. If we are wrong about this claim, what does it cost us, and is that cost reversible? A claim that costs a two-week sandbox to be wrong about is cheap to explore. A claim that costs a re-platforming, a public commitment, or a regulated decision to be wrong about is expensive, and the bar for evidence rises with the exposure. This step quietly does most of the work, because it decouples the size of your response from the size of the hype. Loud claim, low exposure: just try it. Loud claim, high exposure: that is where the rest of the book earns its keep.
The output of SANE is one of three verdicts. Drop: the scope is narrow, the assumptions do not hold for us, there are no numbers worth chasing, move on. Park: it might matter later but not now, log it on the watch list with a date to revisit. Pursue: it touches a real decision, so it advances to decomposition. Most claims should drop or park. If everything you run through SANE comes out "pursue," your filter is broken, you are using it to rationalize the panic you already felt.
Here is the worksheet I keep as a snippet and fill in live during the meeting where someone forwards the clip.
SANE FILTER ---- claim: ____________________ date: ______
S SCOPE
Restated in one sentence, no adjectives:
Boundary the claim is drawing (what it does NOT cover):
A ASSUMPTIONS (must be true for this to matter to US)
1.
2.
3.
N NUMBERS
Metric that would change a decision:
Do we have it? ( ) yes ( ) no, but cheap to get ( ) no, expensive
Cheapest test that produces it:
E EXPOSURE (cost of being wrong)
If wrong, we lose:
Reversible? ( ) easily ( ) with effort ( ) no
VERDICT: ( ) DROP ( ) PARK (revisit: ____) ( ) PURSUEThe reason this works in a real meeting is that it is fast and it is visible. When the founder says "we are behind," you do not argue. You put the worksheet on the screen and start filling it in together. The act of filling it in is the act of slowing the claim down, and it does not feel like resistance because the team is doing it collaboratively. By the time you reach the Exposure line, the temperature in the room has dropped on its own, because everyone can see that the cost of being wrong is a two-week test, not the quarter.
The Claim Decomposition Sheet
A claim that earns "pursue" gets decomposed. The SANE Filter treats the claim as a single object to be triaged. The Claim Decomposition Sheet treats it as a stack of separate sub-claims, each of which can be true or false independently, because the whole reason grand claims are misleading is that they bundle together a capability that is real with a set of operational properties that are not. The demo shows the capability. It hides the properties. Decomposition pulls them apart so each can be tested or rejected on its own.
There are eight dimensions, and I keep them in this order because it roughly tracks how often the claim dies at each one. The earlier dimensions are cheaper to check and kill more claims.
Capability. Can it actually do the core thing, on inputs that look like ours rather than like the demo's? This is the dimension everyone fixates on and it is genuinely necessary, but in my experience it is the least likely to be the killer, because the labs really have built impressive capability. The capability is usually the true part of the claim.
Cost. What does it cost per unit of work at our volume, fully loaded, including retries and the human review the failure rate forces? A 70 percent success rate sounds fine until you price in that the other 30 percent each need a human, and the human costs more than the model saved. Cost is where many genuinely capable systems die for a given use case.
Latency. How long does it take per call, and does that fit the workflow it is supposed to live in? An agent that takes ninety seconds to complete a task is magical in a demo and unusable in a chat interface where the customer expects a reply in three. Latency is invisible in videos because videos are edited.
Integration. What would it take to connect this to our actual systems, our data, our auth, our tools? The demo's agent had its integrations pre-wired. Yours do not. This dimension is where the timeline lives, and it is almost always longer than anyone in the meeting guesses, because integration work does not photograph well and so does not appear in anyone's mental model of the technology.
Reliability. What is the end-to-end success rate on a multi-step task, not the per-step rate? This is the dimension I described in the last chapter, the compounding one. Multiply the per-step success rate across the steps of your real workflow and look at the product. If five steps at 90 percent gives you 59 percent end to end, you do not have a product, you have a thing that needs a human babysitter, which is a different and much smaller claim.
Governance. Can we explain, audit, and stand behind its decisions to whoever holds us accountable, customers, regulators, a court? For an internal tool the bar is low. For a decision that affects a customer's money or rights, the bar is high, and a system that cannot meet it is disqualified regardless of how capable, cheap, fast, integrated, and reliable it is.
Adoption. Will the people who are supposed to use this actually use it, and what does it take to get them there? The most common silent failure mode is a capable system that the team routes around because it does not fit how they work. Adoption is a property of the claim too, even though no vendor lists it.
Switching cost. If we commit and we are wrong, or if something better arrives, what does it cost to leave? This dimension connects forward to the Reversibility Ladder. A claim with high switching cost demands more evidence before commitment, because the exposure compounds over time.
The sheet looks like this when filled out. I use a simple status per dimension rather than false precision, because the point is to find the weakest link, not to compute a score.
| Dimension | Question | Status | Evidence we have | Cheapest next test |
|---|---|---|---|---|
| Capability | Does it do the core thing on our inputs? | strong / weak / unknown | ||
| Cost | Fully loaded cost per unit at our volume? | |||
| Latency | Per-call time vs the workflow's tolerance? | |||
| Integration | Effort to connect to our systems? | |||
| Reliability | End-to-end success across real steps? | |||
| Governance | Can we audit and stand behind it? | |||
| Adoption | Will the intended users actually use it? | |||
| Switching cost | Cost to leave if we are wrong? |
The discipline of the sheet is to find the binding constraint. You do not need all eight to be strong. You need to find the one that is going to kill the use case and check whether it is fatal, before you spend on the others. If reliability is going to be fatal, there is no point measuring integration effort. Decomposition turns a vague "should we do agents" into a sharp "what is the end-to-end success rate of this specific workflow, because that is the only number that can kill it cheaply," and that sharpening is the whole win.
Why decomposition beats debate
I have watched leadership teams argue about a claim for an hour and reach no decision, and I have watched the same team decompose the same claim in twenty minutes and reach a clear one. The difference is that debate operates on the whole claim, where everyone is partly right, so nobody can win, while decomposition operates on the parts, where one part is usually clearly fatal, so the argument resolves itself.
The other thing decomposition does is convert disagreement into experiments. Two smart people looking at the same agent demo will genuinely disagree about whether it is ready. That disagreement is not resolvable by more arguing, because they are forecasting different things. But it is almost always resolvable by naming the dimension they disagree on, usually reliability or integration effort, and running the cheap test. "We disagree about whether it will hit 80 percent end to end, so let us spend two days finding out" is a sentence that ends meetings productively. Decomposition gives you the language to find the exact disagreement and price it as a test rather than relitigate it as an opinion.
A worked example, labeled hypothetical
Let me run one through both instruments, using a composite hypothetical built from situations I have actually been in, so you can see the gears mesh.
The claim, forwarded Tuesday morning: "New model can fully automate customer support." SANE in thirty minutes. Scope, restated: a model that, given a ticket and access to our knowledge base and account systems, drafts and sometimes sends a resolution. Boundary: it is not handling escalations or anything requiring judgment about a refund. Assumptions: that our knowledge base is current, that it can read our account system safely, that customers accept an automated reply, that the failure rate is tolerable. Numbers: the metric that matters is full-resolution rate at acceptable quality and cost per resolved ticket. We have neither. Both are cheaply gettable by replaying last month's tickets offline. Exposure: if we are wrong in a sandbox, we lose two engineer-weeks. Reversible easily. Verdict: pursue.
Decomposition finds the binding constraint fast. Capability: strong, it drafts plausible replies. Cost: unknown, measure it. Latency: fine for email-style support, untested for chat. Integration: moderate, the account system read is the work. Reliability: this is the one. We replay 500 historical tickets offline and measure how often the draft fully and correctly resolves the issue without a human edit. That single test, two days of work, tells us whether this is a product or a babysitting exercise. We run it. It resolves 41 percent cleanly. That is not "automate support." That is "draft first replies for a reviewed tier of tickets," a smaller, real, shippable thing. We ship the smaller thing, on a reversible footing, and we decline the larger claim. Total elapsed time from notification to grounded decision: under a week, most of it waiting for a script to run.
That is what slowing a claim down looks like. Not delay. Conversion.
Key Takeaways
- Slowing a claim is active and time-boxed, with an output: a testable question and a cheap test for it. It is the opposite of "wait and see."
- The SANE Filter is a thirty-minute triage gate. Scope strips adjectives, Assumptions surfaces what must be true for you specifically, Numbers refuses argument without a quantity, Exposure decouples your response size from the hype size.
- Most claims should come out of SANE as drop or park. If everything reads "pursue," you are rationalizing panic, not filtering it.
- The Claim Decomposition Sheet breaks a bundled claim into eight independently testable dimensions: capability, cost, latency, integration, reliability, governance, adoption, switching cost.
- Find the binding constraint and test it first. You do not need all eight to be strong, you need to find the one that kills the use case cheaply.
- Reliability usually means end-to-end success across real steps, not the per-step rate. Multiply the per-step rate across your actual workflow and look at the product.
- Decomposition beats debate because it converts unresolvable opinion about the whole claim into a cheap experiment on the one part you disagree about.