Reading a Frontier Release Without Flinching
A model release is an input to your process, not an interrupt to your roadmap, and vendor categories are claims to be decomposed, not facts to be adopted.

Research spine: this chapter stays grounded in Stanford HAI, 2025 AI Index Report and DORA, 2024 Accelerate State of DevOps Report, then applies that evidence to the operating judgment in the book. Read this alongside the First Principles AI book, the AI-Native thesis, and the full book library when you want the surrounding argument. The launch livestream is a genre now, and like all genres it has conventions. There is the founder in a plain shirt. There is the benchmark chart with your company's logo conspicuously not on it. There is the live demo that works. There is the new word, the category that did not exist last week and that you are now apparently behind on. And there is the carefully managed sense that the ground has shifted and everyone watching needs to respond. I have been in the audience for these and I have helped script them, and I want to give you a way to watch one without your roadmap moving an inch until you decide it should.
The thesis of this chapter is small and load-bearing: a frontier model release is an input to your existing process, not an interrupt to your roadmap. The release does not get to preempt your priorities. It gets to enter the Trend Triage Board, get decomposed if it earns it, and wait for a slot like everything else. The flinch, the reflexive reprioritization on launch day, is the thing to train out of yourself and your team, because the flinch is how the vendor's launch calendar becomes your strategy calendar.
What a release actually is, and is not
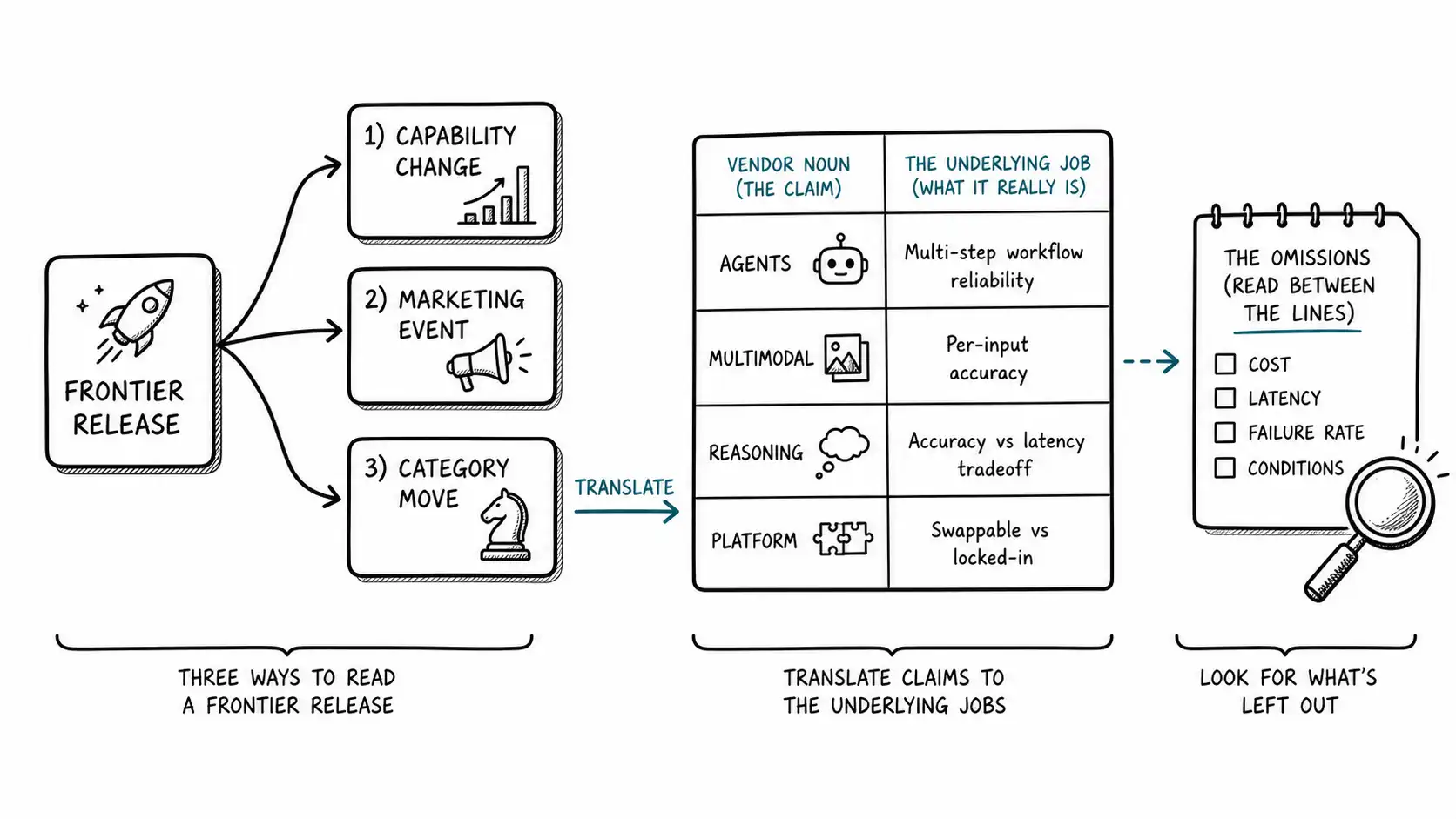
Strip the production and a frontier release is three things bundled together, and you should unbundle them on sight.
It is a capability change. The new model can do some things the old one could not, or can do them better, cheaper, or faster. This part is often real and worth knowing. It is also the part you cannot assess from the livestream, because, per the demos chapter, the stream shows the capability's ceiling under ideal conditions, not its behavior on your distribution.
It is a marketing event. The framing, the category language, the choice of which benchmarks to show and which to omit, the demo selection, all of it is optimized to drive adoption and to make non-adoption feel risky. This part is not a lie, exactly, but it is advocacy, and you should read it as advocacy, the way you read a candidate's stump speech rather than a referee's report.
It is a category move. Increasingly, the most important thing in a release is not the model but the word: "agents," "reasoning," "computer use," "multimodal," whatever the new noun is. The word is doing strategic work. It is trying to redefine the problem space so that the vendor's product is the natural answer, and it is trying to make you feel that you owe the category a strategy. This is the part that does the most damage to clear thinking, so it gets its own treatment below.
Vendor categories: who names the problem owns the answer
When a vendor creates a category, they are not just describing a capability, they are proposing a way of carving up the world, and the carving is shaped to put their product at the center. This is one of the most effective and least noticed moves in the whole hype cycle, and the defense is to refuse the category as given and rebuild the problem in your own terms.
The pattern is consistent. A capability emerges. A vendor gives it a noun. The noun gets adopted by analysts and press because nouns are convenient. Suddenly there is an "agent strategy" you are supposed to have, a "reasoning model" you are supposed to be using, a "platform" you are supposed to standardize on. The category creates an implied obligation. But the category was never a neutral description of your needs. It was a description of the vendor's product, generalized into a noun, and then handed back to you as if it were your problem.
The way out is to translate the category back into the underlying job. "Do we have an agent strategy" is the wrong question because "agent" is the vendor's word. The right question is "are there multi-step workflows in our operation where chaining tool calls under a goal would create value net of the reliability cost, and is the technology good enough at that yet." That question is answerable with the decomposition sheet and a replay. The category question is not answerable at all, because it is not really a question, it is a frame. When you find yourself asked whether you have a strategy for a vendor's noun, the first move is always to replace the noun with the job it is standing in for, and then ask whether you have that job and whether the tech does it for you.
A frontier release runbook
Here is the literal sequence I run when a major release lands on something near my business, designed to take an hour or two and produce a disposition, not a reprioritization. Notice that none of the early steps involve changing any plans.
First, do nothing to the roadmap. The release is an input to be processed, and processing takes a day, not a launch-day reaction. Resist the channel message that says "we need to respond today." You almost never do.
Second, unbundle the three things above. Write down, separately, what capability is claimed, what the marketing framing is, and what category move is being made. Keeping them apart prevents the marketing energy from coloring your read of the capability.
Third, find the omissions. What did the release not show? Which benchmarks were absent? What was the latency, the cost, the failure rate, the context window cost at scale? What conditions were the demos run under? The omissions are usually more informative than the inclusions, because a release shows its best and hides its binding constraints, and the binding constraint is exactly what you need to know.
Fourth, run the SANE Filter on the capability, stripped of category language. Scope it in your own words, surface the assumptions for your situation, name the number that would change a decision, assess your exposure. Most releases come out of this as "park" with a trigger, because most releases are real but not yet relevant to a decision you have in front of you.
Fifth, update the Trend Triage Board and the watch triggers. A release often does not change a disposition but does change a trigger's proximity. The agent capability that was on "watch" pending 90 percent end-to-end reliability is still on watch, but the release moved the public number from, say, 60 to 75, so the trigger is closer. That is the correct kind of update: a recalibration of distance, not a reprioritization of work.
Sixth, only if the release fires an existing trigger, advance the trend to a slot via the exchange rule, decompose it, and put it on the reversibility ladder at the appropriate rung. This is the rare case, and when it happens it happens through the process, with something traded out to make room, on the lowest reversible rung that will teach you what you need.
First principles for the recurring category waves
The book's job is to outlast specific releases, so rather than analyze whichever model is current as you read this, let me give you the durable first-principles read on the category waves that keep recurring, so that the next instance of each is decomposable on sight.
Agents. The category claim is autonomous multi-step task completion. The first-principles read is the reliability multiplication from the demos chapter: the value is real and the binding constraint is almost always end-to-end reliability across the real number of steps, which compounds downward. So the question for any agent claim is never "are agents real," it is "what is the end-to-end success rate on my specific multi-step workflow, measured on my data, and is it high enough that the automation saves more than the failures cost." Decompose to steps, measure each on replay, multiply, decide. The category dissolves into arithmetic.
Multimodal. The category claim is that the model handles images, audio, video, and text together. The first-principles read is that the relevant question is per-modality, per-task reliability on your inputs, because "multimodal" averages over modalities the model is excellent at and ones it is poor at. A model can be superb at reading clean charts and weak at reading the specific kind of degraded scanned document your business actually receives. So you never evaluate "multimodal," you evaluate the exact modality and input type you have, on your data, via replay.
Reasoning. The category claim is that the model thinks before answering and is therefore more reliable on hard problems. The first-principles read is that the relevant trade is accuracy gain against the latency and cost the extra computation adds, because reasoning modes typically cost more and run slower. So the question is whether the accuracy gain on your task clears your latency and cost budget, which is a cost-accuracy frontier question from the benchmarks chapter, not a question about whether reasoning is impressive.
Small and on-device models. The category claim, often from the opposite camp, is that you do not need the frontier, a small model is enough and cheaper. The first-principles read is the same cost-accuracy frontier from the other direction: find the smallest, cheapest model that clears the accuracy bar your task genuinely requires, which for many tasks is well below the frontier. This is not a competing ideology, it is the same analysis. The frontier-versus-small debate is a false binary; the answer is always "the cheapest thing that clears the bar," and the bar is set by your task, not by the discourse.
Platforms. The category claim is that you should standardize on one vendor's full stack. The first-principles read is straight from the reversibility ladder: standardizing on a platform is a high-rung, hard-to-reverse commitment during a period of rapid change, so the evidence bar is high and the engineered reversibility, abstraction layers and data ownership, matters enormously. The platform pitch is precisely the moment to be most careful about the one-way door.
Notice that none of these reads required knowing which specific model triggered the wave. Each category dissolves into a question you already have a tool for: reliability arithmetic, per-input replay, a cost-accuracy frontier, or the reversibility ladder. That is the point of first principles. The nouns will keep changing. The questions underneath them do not.
The vendor claim interrogation checklist
When you do engage a vendor seriously, after a release has earned a slot, here is the interrogation I run, designed to surface the things the release omitted. These are the questions vendors find uncomfortable, which is how you know they are the right ones.
- On what data was this evaluated, and how close is it to ours? Will you run it on a sample of our actual data before we commit?
- What is the failure rate on a task like ours, and what do the failures look like, loud or silent?
- What is the fully loaded cost per useful outcome at our volume, including retries and the review our failure rate forces?
- What is the p95 latency under concurrency like ours, not the best-case single-call number?
- What does integration with our systems actually require, in our environment, with our auth and data shapes?
- How is this governed and audited, and can we stand behind its decisions to a customer or a regulator?
- What is our exit cost? Can we keep our data and prompts, swap models, and leave without re-platforming?
- What changed between the last version and this one that might break what we build on it, and how often does that happen?
A vendor who answers these crisply and offers to run on your data is a vendor worth advancing. A vendor who deflects to the benchmark chart and the demo is telling you the release was mostly the marketing event and the category move, with the capability and its binding constraints left conveniently offstage.
Summary
A frontier release is a capability change, a marketing event, and a category move bundled together, and the discipline is to unbundle them, process the release as an input rather than reacting to it as an interrupt, and refuse to let the vendor's category define your problem. Translate every category noun back into the underlying job, then answer the job with the tools you already have: reliability arithmetic for agents, per-input replay for multimodal, the cost-accuracy frontier for reasoning and small models, the reversibility ladder for platforms. Run a launch-day runbook that touches the triage board and the watch triggers but not the roadmap, and only advance a trend to a slot when an existing trigger fires, through the exchange rule, on the lowest reversible rung. The nouns will keep changing. Refuse to let them run the meeting.
Key Takeaways
- A frontier release is an input to your process, not an interrupt to your roadmap. The launch-day flinch is how the vendor's calendar becomes your strategy calendar. Train it out.
- Unbundle every release into three things: a capability change, a marketing event, and a category move. Keep them separate so marketing energy does not color your read of the capability.
- The omissions in a release, the absent benchmarks, the unstated cost, latency, and failure rate, are usually more informative than what is shown, because the release hides its binding constraints.
- When a vendor names a category, they own the answer. Translate the noun back into the underlying job and ask whether you have that job and whether the tech does it, on your data.
- Category waves dissolve into questions you already own: agents into end-to-end reliability arithmetic, multimodal into per-input replay, reasoning and small models into a cost-accuracy frontier, platforms into the reversibility ladder.
- Frontier versus small is a false binary. The answer is always the cheapest model that clears the bar your task sets, not the one the discourse crowns.
- Run a launch-day runbook that updates triggers and the triage board but not the roadmap, and advance a trend only when an existing trigger fires, through the exchange rule, on the lowest reversible rung.