Demos Are Not Deployments
A demo proves a capability can happen once, a deployment proves it happens reliably at cost, and the distance between them is where most AI strategy goes to die.

Read this alongside the First Principles AI book, the AI-Native thesis, and the full book library when you want the surrounding argument. I once shipped a demo that worked exactly once on camera and never that cleanly again, and I want to start there because confession is more useful than theory. The product was a document-extraction tool. In the demo it read a messy invoice and pulled out every field perfectly. What the audience did not see was that I had run the same invoice forty times that morning, watched it fail in a dozen different ways, and selected the take where the model happened to be right about all of it at once. I was not lying. Every frame was real. I had simply filmed the coin landing heads and left the tails on the cutting-room floor.
That is the cleanest way I know to define the gap this chapter is about. A demo is a proof that a capability can happen. A deployment is a proof that it happens reliably, at acceptable cost, inside real systems, for real users, on the bad inputs as well as the good ones. These are not two points on the same line. They are different kinds of claim, and confusing them is the single most expensive mistake in AI adoption, because the demo is free and the deployment is the whole iceberg.
What the camera hides
Let me enumerate what the demo cannot show, because the list is the gap.
The demo hides the failure distribution. You see one success. You do not see the shape of the failures: how often, how badly, and whether the failures are detectable. A system that fails 30 percent of the time but fails loudly, flagging that it is unsure, is shippable with a review step. A system that fails 10 percent of the time but fails silently, confidently producing wrong answers, can be worse, because the silent failures slip into production undetected. The demo shows neither rate nor character.
The demo hides the input distribution. The demo input was chosen, consciously or not, from the easy part of the distribution. Production inputs are drawn from the whole distribution, including the malformed, the adversarial, the out-of-domain, and the merely weird. In my invoice case, the demo invoice was clean. Real invoices include handwriting, coffee stains, three languages, and a column that means something different at every customer. The capability was real on the demo's distribution and absent on a quarter of the real one.
The demo hides integration. The demo's data was already where the model could reach it. In production, the data is behind an auth boundary, in a schema the model has never seen, in a system whose owner has not approved the access. The demo's tools were pre-wired. Yours are a quarter of integration work that nobody filmed. This is why timelines from demo to deployment are routinely off by a factor of five: the visible part, the capability, was the part that was already done.
The demo hides cost at scale. One run is free. A million runs is a budget line, and once you add the retries that the failure rate forces and the human review that the silent failures require, the fully loaded cost per unit of useful work can be many times the headline token cost. I have seen a system that cost a fraction of a cent per call and a fortune per correct outcome, because most calls were not correct outcomes.
The demo hides the maintenance tail. The demo is a snapshot. A deployment lives in time, which means the model gets deprecated, the prompt that worked drifts as the model updates, the data distribution shifts, and the integration breaks when an upstream system changes. None of this is visible in a thirty-second clip, and all of it is most of the total cost of ownership.
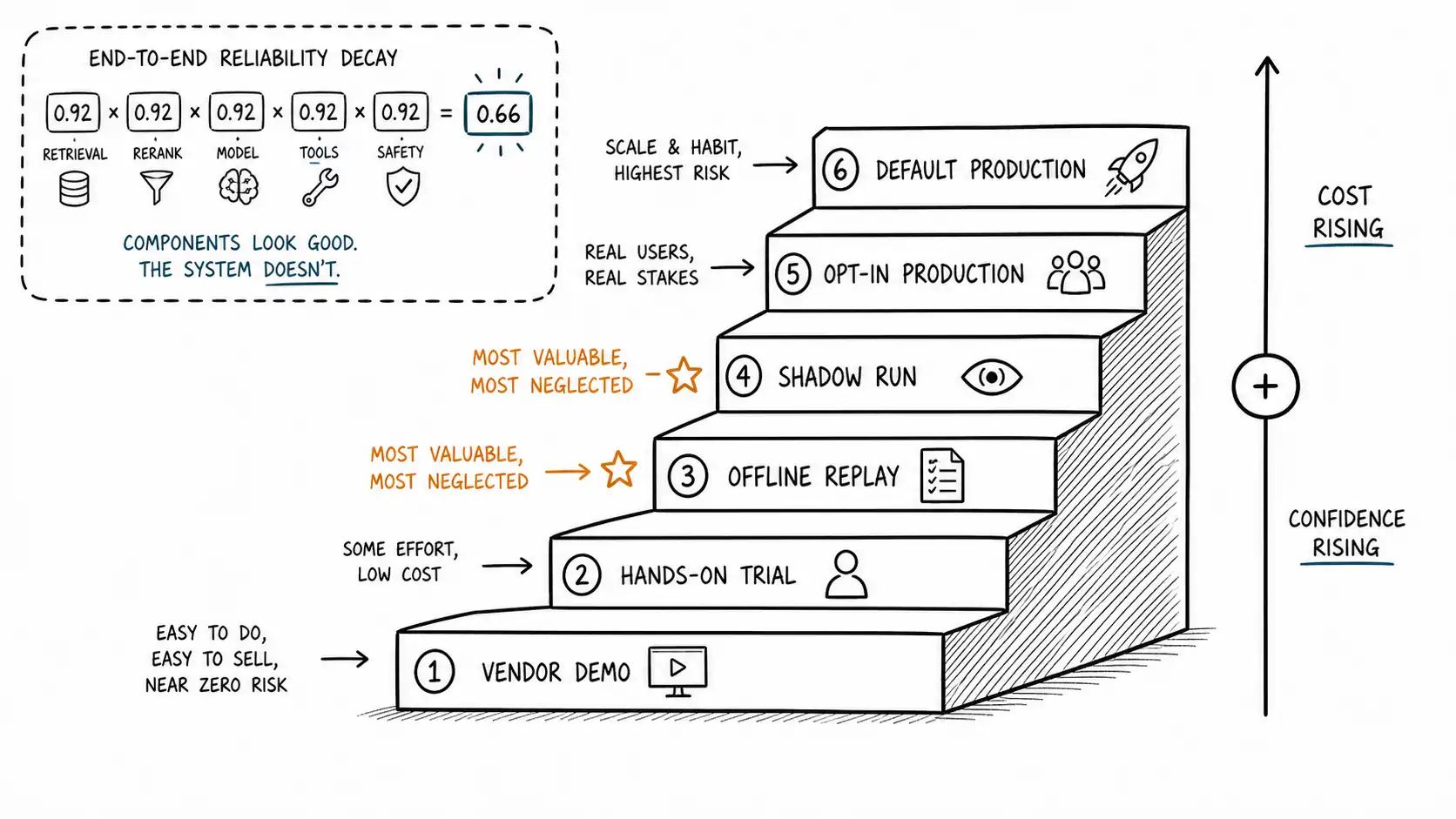
The evidence ladder
Because the gap is large and the demo sits at the bottom of it, you need a graded sequence of evidence, each step more expensive and more convincing than the last, so that you can stop as soon as you have learned what kills the use case and not before. I call it the evidence threshold ladder. Each rung answers a different question, and the discipline is to climb only as far as the decision's exposure requires.
| Rung | Evidence | Question it answers | Roughly what it costs |
|---|---|---|---|
| 0 | Vendor demo / clip | Can this capability exist at all? | free, and worth what you pay |
| 1 | Hands-on trial on your own easy inputs | Does it work for us on the good cases? | hours |
| 2 | Offline replay on historical real data | What is the failure rate and character on the full distribution? | a few days |
| 3 | Shadow run alongside the current process | Does it hold up on live volume without touching anything? | weeks |
| 4 | Limited opt-in production with a human in the loop | Does it survive real users and real consequences? | a quarter |
| 5 | Default production at scale | Does it hold cost, latency, and reliability over time? | ongoing |
The two most underused rungs are 2 and 3, and they are the two that do the most work for the least money. Offline replay, rung 2, is the test I keep returning to in this book, because for most AI use cases your most valuable asset is a pile of historical cases with known correct outcomes. You can run the new system against last quarter's tickets, invoices, or transactions and measure exactly how often it would have been right, on the real distribution, with no production risk, in a few days. Almost nobody does this before getting excited. Everybody does it after getting burned. Do it first.
Shadow running, rung 3, runs the new system in parallel with the existing one on live traffic, recording what it would have done without acting on it. This catches the failures that historical data cannot, the ones that come from live conditions, while keeping the exposure at zero because the system's output is observed, not used. The cost is the engineering to wire the shadow path, which is real, but it buys you a deployment-quality picture without a deployment-quality risk.
What the research says about the gap
This is not just my scar tissue. The most rigorous ongoing study of software delivery, the DORA program behind the Accelerate State of DevOps reports, found something pointed in its 2024 work: AI adoption raised individual developer productivity and self-reported flow, while delivery throughput dipped slightly and delivery stability dropped meaningfully, on the order of a seven percent decline in stability for teams adopting AI tooling (DORA, 2024 Accelerate State of DevOps Report). And only 39 percent of respondents expressed confidence in AI-generated output.
Read that carefully, because it is the demo-deployment gap measured in a real population. The demo of AI coding tools is "the engineer goes faster," and that part is true, productivity and flow went up. The deployment reality is that the same tooling, without the surrounding discipline of review and validation, made the system as a whole less stable. The capability was real. The deployment was worse, until the organization built the review and observability around it. DORA's own conclusion was that the gains arrive only inside a well-governed ecosystem that absorbs the new change rather than amplifying its risk. That is the evidence ladder, restated by researchers: the capability is rung 1, the stable deployment is rungs 4 and 5, and skipping the middle is what produced the stability drop.
The five-step reliability trap
I want to dwell on the arithmetic of multi-step reliability, because it is the most common way a demo lies without anyone intending to, and it is the reason the current wave of "agent" demos deserves particular suspicion.
A single-step task that succeeds 90 percent of the time is a fine demo and often a fine product. An agent demo, though, shows a task with several steps: read the request, look up the account, decide on an action, call a tool, confirm. Each step has its own success rate, and the steps are in series, which means the rates multiply. Five steps at 90 percent each is 0.9 to the fifth power, which is 59 percent end to end. Five steps at 95 percent each is 77 percent. To get to a 90 percent end-to-end success rate across five steps, each step needs to succeed about 98 percent of the time, which is a far higher bar than most demos are anywhere near.
This is why a demo of a five-step agent can be genuinely impressive and a deployment of the same agent can be genuinely unusable. The demo showed one chain that completed. The deployment runs thousands of chains, and the multiplication grinds the end-to-end rate down below what the workflow can tolerate. The fix is not to argue about whether agents work. It is to decompose the agent into its steps, measure each step's rate on real data via offline replay, multiply, and look at the product. The product is the only number that matters, and it is never in the video.
END-TO-END RELIABILITY CHECK
steps in the real workflow: n = 5
per-step success rate (measured): p = 0.92
end-to-end success: p^n = 0.92^5 = 0.659 (65.9%)
target end-to-end success: 0.90
required per-step rate: 0.90^(1/5) = 0.979 (97.9%)
gap between measured 92% and required 98% per step
= the entire difference between the demo and a deploymentHow to run the gap deliberately
Here is the operating procedure I now use whenever a demo lands on something that matters. It is the evidence ladder plus the reliability check, run as a sequence with explicit stop conditions.
First, name the workflow precisely and count its steps. A demo without a named, step-counted target workflow is not evaluable, and the vagueness is doing work for the seller. Second, pull the historical data for that exact workflow and run rung 2, the offline replay, measuring per-step and end-to-end success on the real distribution. Stop here if the end-to-end number is fatally low, you have your answer for a few days of cost. Third, if rung 2 survives, run rung 3, the shadow, to catch the live-only failures, for a few weeks. Fourth, only if rungs 2 and 3 survive, move to rung 4, opt-in production with a human in the loop and full logging, sized so that being wrong is recoverable. Fifth, expand to rung 5 only after rung 4 has held its cost, latency, and reliability numbers over enough time to trust the maintenance tail.
The stop conditions are the point. Most use cases die at rung 2, cheaply, which is exactly what you want: the failures should be cheap and early, not expensive and late. The organizations that get hurt are the ones that jump from rung 0, the demo, to rung 4 or 5, real production, on the strength of the clip, and discover the failure distribution with their customers instead of with their historical data.
Summary
A demo proves a capability can happen once. A deployment proves it happens reliably, at cost, in your systems, for your users, on your worst inputs, over time. The camera hides the failure distribution, the input distribution, integration, cost at scale, and the maintenance tail, which together are most of the work. Climb the evidence ladder only as far as the exposure requires, and lean hard on the two cheap, neglected rungs: offline replay on historical data and shadow running on live traffic. And before you believe any multi-step agent demo, measure the per-step rate and multiply, because the end-to-end product is the real claim and it is never in the video.
Key Takeaways
- A demo proves a capability can happen once. A deployment proves it happens reliably, at cost, in your systems, on bad inputs, over time. They are different kinds of claim.
- The camera hides the failure distribution, the input distribution, integration work, cost at scale, and the maintenance tail. That hidden material is most of the total cost.
- Use a graded evidence ladder and climb only as far as the decision's exposure requires, so failures stay cheap and early.
- Offline replay on historical data (rung 2) and shadow running on live traffic (rung 3) are the most valuable and most neglected rungs. Do them before getting excited, not after getting burned.
- Multi-step reliability multiplies: five steps at 92 percent each is 66 percent end to end. Hitting 90 percent end to end across five steps needs about 98 percent per step.
- DORA's 2024 research shows AI tooling raised individual productivity but lowered delivery stability until teams built the review and observability around it. The gains live in the governed deployment, not the capability.
- Never let a vendor leave the target workflow vague. Name it, count its steps, and measure the end-to-end product. That number is the real claim.