Defense-in-Depth: The Whole Architecture
> **Working claim: ** No single control in this book stops prompt injection. That is not a weakness in the controls; it is the nature of the problem, because the model layer is irreducibly probabilistic.

Defense-in-Depth: The Whole Architecture composes every prior control into a system where model failure does not equal system failure.
Key Takeaways
- Stacking correlated probabilistic controls is not the same as defense-in-depth.
- The useful architecture has a probabilistic skin that reduces attack rate and a deterministic skeleton that bounds impact.
- The defense matrix is the review artifact: every attack path needs prevent, bound, and detect columns.
- Residual harm remains, so testing, monitoring, and incident response are part of the architecture, not afterthoughts.
Read this beside Security Boundaries for Tool-Using Systems, Agents That Actually Work, and Devlyn's AI security and red-teaming work when moving from patterns to architecture.
**Working claim: ** No single control in this book stops prompt injection. That is not a weakness in the controls; it is the nature of the problem, because the model layer is irreducibly probabilistic. Security comes from composition: independent controls of different kinds at different points, arranged so that defeating one leaves the attacker facing a qualitatively different obstacle, and the worst-case outcome is bounded no matter which layers the attacker beats. This chapter assembles the whole stack and maps every attack path to the controls that contain it.
The principle, restated precisely
Chapter 4 defined real defense-in-depth against the strawman of "the same defense stacked." Here we make it the organizing principle of an architecture. The mathematics is simple and worth holding explicitly: if an attacker defeats one probabilistic layer with probability p, stacking three correlated layers (all probabilistic, all looking for the same thing) gives you something close to p still, because the input that beats one beats all. But composing a probabilistic layer (p) with a deterministic boundary that the model cannot influence gives you p × 0 for the outcomes the boundary covers: the boundary holds regardless of whether the probabilistic layer was beaten. Defense-in-depth works not by multiplying small probabilities but by ensuring that the catastrophic outcomes are gated by deterministic checks, so that beating the model layer (which the attacker can do) does not beat the system.
This is why the architecture is shaped the way it is: a thin probabilistic skin (input handling, model robustness) that lowers the rate of attempts reaching the boundaries (the OWASP LLM Top 10 catalogs the full attack surface this skin must reduce), wrapped around a deterministic skeleton (data ACLs, tool gates, egress control, write gates, human approval) that bounds the impact when the rate-reduction fails. The skin saves the skeleton work; the skeleton saves the system.
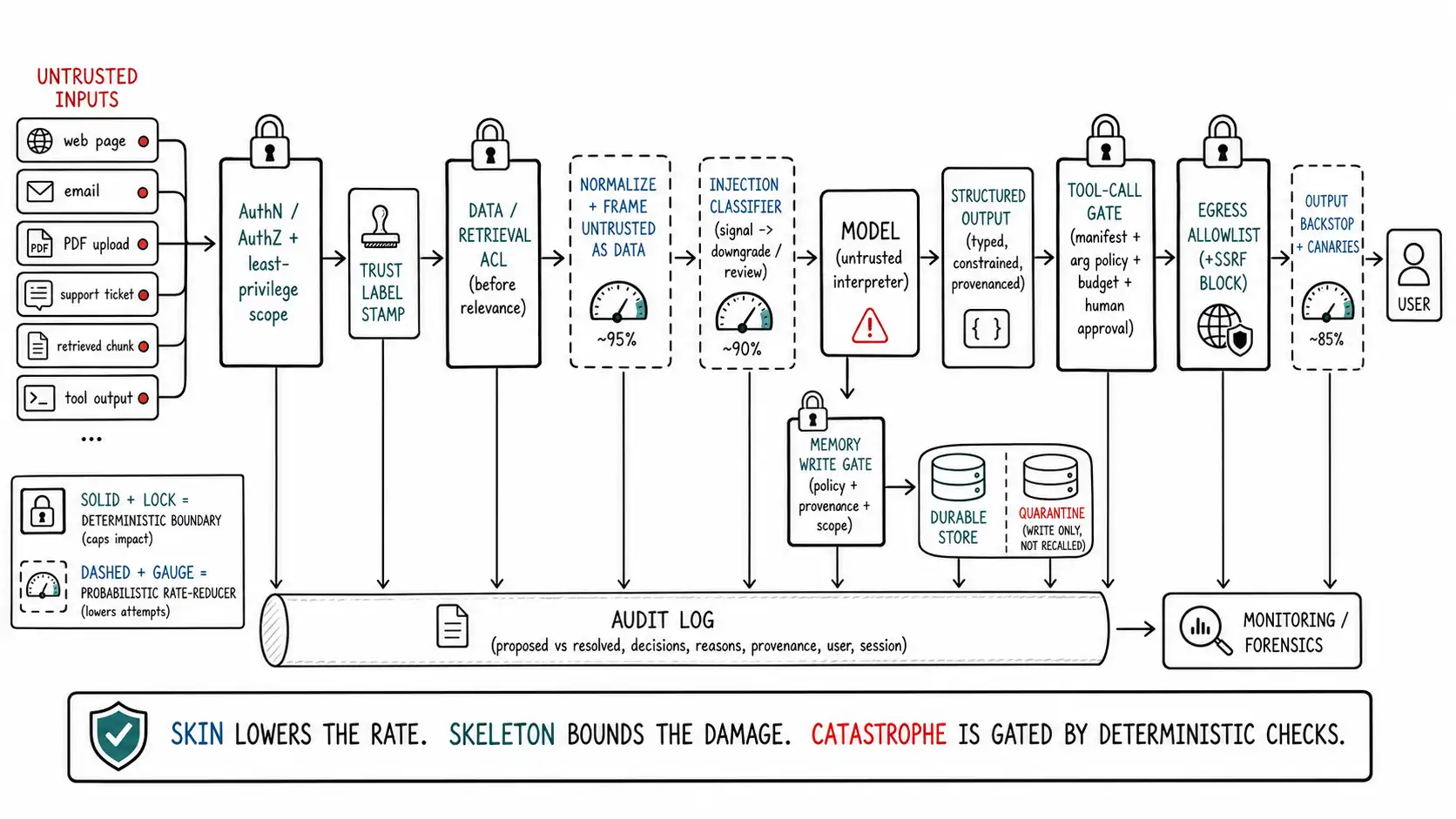
The stack, layer by layer
Here is the full defense stack for an LLM application that reads untrusted text and can act, ordered along the request path. For each layer: what it does, whether it is a boundary or a rate-reducer, and which chapter built it.
| # | Layer | Does | Kind | Chapter |
|---|---|---|---|---|
| 1 | AuthN / AuthZ | Establish who the session is and scope to least privilege | Boundary | 3, 4 |
| 2 | Trust labeling at ingestion | Stamp every input's source-trust; carry it through | Foundation | 7 |
| 3 | Retrieval / data ACL | Filter readable data by user+task before relevance | Boundary | 4, 8 |
| 4 | Input normalization + framing | Strip concealment; wrap untrusted as data | Rate-reducer | 6 |
| 5 | Injection classifier (signal) | Score input; downgrade capability / route to review | Rate-reducer | 6 |
| 6 | Model + robust prompt | Generate; resist common attacks | Rate-reducer | 2, 5 |
| 7 | Structured output | Constrain output form for safe parsing | Foundation | 9, 10 |
| 8 | Tool-call gate | Authorize tool + validate args + budget + approval | Boundary | 9, 10 |
| 9 | Egress / network control | Allowlist outbound destinations; block SSRF | Boundary | 11 |
| 10 | Output backstop + canaries | Catch plaintext leaks; alert on canaries | Rate-reducer + detect | 11, 12 |
| 11 | Memory write gate | Reject instruction-shaped persistence; quarantine | Boundary | 13 |
| 12 | Audit + monitoring | Log every decision; detect attacks; enable forensics | Foundation | 10, 16 |
The boldface boundaries are the load-bearing wall. Read down the "Kind" column and the architecture's logic is visible: the rate-reducers (4, 5, 6, 10) lower how often the boundaries are tested and provide signal, while the boundaries (1, 3, 8, 9, 11) deterministically cap what a fully manipulated model can do. Microsoft's defense-in-depth writeup and the OWASP cheat sheet describe materially the same layering, untrusted-by-default, isolate, constrain capability, validate output, monitor, and the agreement across independent guidance is itself a signal that this shape is the consensus, not one team's preference.
The secure reference architecture, drawn
The defense matrix: attack path versus control
The single most useful artifact a security review can produce for an LLM application is a matrix mapping each attack path to the controls that contain it, marked by whether each control prevents, bounds, or merely detects the outcome. Filling it in for your own system surfaces the paths with only detection and no bound: your real exposure.
| Attack path | Prevent | Bound (cap blast radius) | Detect |
|---|---|---|---|
| Direct jailbreak → policy-violating text | Robust model, framing (partial) | Output is text-only; user's own perms | Classifier signal; output backstop |
| Direct → unauthorized data read | - | Data ACL (user can't exceed own scope) | Audit of reads |
| Indirect (RAG) → goal hijack | Evidence framing (partial) | Tool gate stops resulting action | Classifier; tool-call audit |
| Indirect → cross-tenant data | - | Retrieval ACL / visibility scope (deterministic) | Audit; canary in tenant doc |
| Indirect → tool manipulation | Arg validation (partial) | Tool gate + arg-to-app-fact binding | Tool-call audit (proposed vs resolved) |
| Indirect → unauthorized write | - | Tool gate + human approval + reversibility | Audit; approval log |
| Any → exfiltration via URL/image/tool | - | Egress allowlist (deterministic) | Egress block log; active canary |
| Any → prompt leak | Keep no secrets in prompt | Leak is harmless (nothing sensitive) | System-prompt canary |
| Any → memory/index poisoning | Write gate (instruction-shaped reject) | Quarantine; scope; expiry; provenance cleanup | Scheduled scan; rejection-rate spike |
| Agent loop → escalation | Cap iterations | Cumulative budget; taint -> human review | Budget-exceed log; taint flag |
Two patterns in this matrix are the whole chapter. First, the Prevent column is mostly empty or "(partial)", because prevention means stopping the model from being fooled, which is the probabilistic thing we cannot guarantee. Second, the Bound column is full of deterministic boundaries (boldface), because bounding the blast radius is the thing we can guarantee, and it is where the security actually lives. A team whose matrix has full Prevent columns is fooling itself; a team whose Bound column is full has a defensible system. The honest goal is not an empty threat surface, it is a fully populated Bound column and a populated Detect column, accepting that Prevent is best-effort.
Composing the layers in code
The architecture is not just a diagram; it is a request pipeline where each layer is a discrete, testable stage, and the boundaries are deterministic functions the model cannot influence. The shape:
def handle_request(raw_inputs, user, manifest):
# L1 - authn/authz: scope this session to least privilege (boundary)
ctx = authorize(user, scope="task") # ctx carries the user's real perms
# L2 - trust labeling at ingestion (foundation): every input gets a source-trust
inputs = [ingest(i.text, i.channel, i.source_ref, DETECTORS) for i in raw_inputs]
# L3 - data/retrieval ACL BEFORE relevance (boundary): forbidden data never candidates
evidence = retrieve_for_user(query=ctx.task_query, user=user) # Ch.8
# L4/L5 - normalize, frame, classify (rate-reducers + signal -> capability downgrade)
inputs = [normalize_and_frame(i) for i in inputs]
route = classify_and_route(combined(inputs), ctx) # may restrict to read-only
# L6/L7 - model generates structured output (rate-reducer + form foundation)
proposal = model.generate(build_messages(SYSTEM_PROMPT, inputs, evidence),
response_schema=ACTION_SCHEMA)
# L8/L9 - EVERY proposed effect passes deterministic gates (boundaries)
for call in proposal.tool_calls:
decision = tool_call_gate(call, GateContext(manifest, user, ctx.session,
tainted_by_untrusted=route.tainted))
if decision[0] == "allow":
url_args(call).foreach(egress_guard) # egress allowlist (boundary)
execute_with_broker(call, ctx) # secrets server-side (Ch.12)
elif decision[0] == "require_human":
queue_for_approval(call, render_resolved_effect(call, ctx)) # show real effect
# deny: logged, dropped
# L11 - memory candidates pass the adversarial write gate (boundary)
for cand in extract_memory_candidates(proposal):
memory_write_gate(cand)
# L10/L12 - output backstop + audit EVERYTHING (rate-reducer + foundation)
text, findings = output_backstop(proposal.text, ctx)
audit(ctx.request_id, inputs, evidence, proposal, findings) # forensics substrate (Ch.16)
return textEvery deterministic boundary in this pipeline runs regardless of what the model produced. The model's proposal is exactly that, a proposal, and the gates dispose. Notice that the model sits in the middle, untrusted, surrounded by checks on both sides: ACL-scoped data going in, gated effects coming out. This is the architectural expression of "the model is an untrusted interpreter inside the perimeter" from Chapter 3.
What this architecture does not promise
Honesty is the spine of this book, so the chapter ends by naming the residual risk this architecture leaves, because a defense that oversells itself is the comfortable framing in a new costume.
It does not make the model un-foolable. A determined attacker can still manipulate the model's text output and its proposals. What the architecture guarantees is that manipulation cannot, by itself, cross a deterministic boundary: cannot read data the user can't, cannot fire an unauthorized or unreviewed high-impact action, cannot exfiltrate to a non-allowlisted destination, cannot persist an instruction-shaped memory. Within those bounds, residual harm remains, a manipulated model can still produce a wrong or policy-violating answer to the user, can still take authorized actions for the wrong reasons, can still leak data the user was allowed to see through a channel that is allowed. Those residuals are real, and they are why testing, monitoring, and incident response (Ch. 15, 16) are not optional add-ons but the final, necessary layers: you bound the catastrophic outcomes deterministically, and you watch for the non-catastrophic ones you couldn't bound. The architecture turns "we might have a catastrophic breach we never see" into "we have a bounded, monitored, recoverable risk surface, " which is the realistic, achievable goal, the same goal mature security teams hold for every system, not a special lowering of standards for AI. NIST's AI RMF frames this exactly as managing risk to an acceptable level, not eliminating it, which is the only honest promise available.
Chapter summary
No single control stops prompt injection, because the model layer is irreducibly probabilistic; security comes from composition, and the math is that stacking correlated probabilistic layers barely helps (the input beating one beats all) while composing a probabilistic layer with a deterministic boundary the model can't influence drives the catastrophic outcomes to zero regardless of whether the probabilistic layer was beaten. So the architecture is a thin probabilistic skin (input normalization/framing, injection classifier, robust model) that lowers the rate of attempts reaching the boundaries, wrapped around a deterministic skeleton (authz/least-privilege, data/retrieval ACL, tool-call gate, egress control, memory write gate, human approval) that bounds the impact when rate-reduction fails, the skin saves the skeleton work, the skeleton saves the system. The full twelve-layer stack runs along the request path with each boundary executing regardless of model output, the model sitting untrusted in the middle with ACL-scoped data going in and gated effects coming out. The defense matrix mapping attack paths to prevent/bound/detect is the key review artifact, and its lesson is stark: the Prevent column is mostly empty or partial (prevention means un-fooling the model, which we can't guarantee) while the Bound column is full of deterministic boundaries (where security actually lives), a team with full Prevent columns is fooling itself; a team with a full Bound column has a defensible system. The architecture explicitly does not make the model un-foolable: residual harm remains (wrong answers, authorized-but-misguided actions, allowed-channel leaks of allowed data), which is precisely why testing, monitoring, and incident response are the necessary final layers: turning "a catastrophic breach we never see" into "a bounded, monitored, recoverable risk surface, " which per NIST's AI RMF is the only honest promise: manage risk to an acceptable level, don't pretend to eliminate it.