The Confused Deputy, Least Privilege, and Blast Radius
> **Working claim: ** The damage of a successful injection is not set by the attacker's privileges. It is set by *your system's* privileges, exercised on the victim's behalf.

The Confused Deputy, Least Privilege, and Blast Radius reframes prompt injection around borrowed authority: the attacker tricks your model into using your reach.
Key Takeaways
- Prompt injection is structurally the confused-deputy problem with a language model as the deputy.
- Authentication is not authorization; the model should not inherit every permission the user happens to hold.
- Least privilege applies to data, tools, credentials, actions, time, and durable writes.
- Blast radius replaces the vague question "is it safe?" with a capability-by-capability damage assessment.
Read this beside Security Boundaries for Tool-Using Systems, Agents That Actually Work, and Devlyn's AI security and red-teaming work when you scope tool authority.
**Working claim: ** The damage of a successful injection is not set by the attacker's privileges. It is set by your system's privileges, exercised on the victim's behalf. This is the confused-deputy problem, it is the oldest bug in computer security wearing a new hat, and it means the most powerful thing you can do for security is not detect attacks better: it is give the model less to be confused with.
A 1988 bug, rediscovered
In 1988, Norm Hardy described a problem he called the confused deputy. The setup: a compiler service runs with permission to write to a billing file (so it can charge for compilation) and accepts, as an argument, the name of a file to write its debug output to. A user invokes the compiler and passes the billing file's name as the debug-output path. The compiler dutifully overwrites the billing file. The user never had permission to write that file. The compiler did, and the user tricked the compiler into using its authority on the user's behalf. The deputy, the compiler, was confused into misusing a power that was legitimately its own.
Read that and then reread the support copilot from Chapter 1. An attacker who could not read the customer's account record wrote a ticket that convinced the copilot, which could read it, to put that record in a reply. The attacker borrowed the deputy's authority. Prompt injection is, structurally, the confused-deputy problem with a language model as the deputy, as Greshake et al. demonstrated against real LLM-integrated applications. This is not a metaphor or an analogy reaching for relevance; it is the same bug. And it is clarifying, because it tells you exactly where the control point is. You will not stop attackers from trying to confuse the deputy, confusing it is a probabilistic game you cannot win outright (Ch. 2). What you can control is how much authority the deputy has to misuse. A confused deputy with no dangerous powers is a deputy that produces a weird sentence. A confused deputy holding the keys to everything is an incident.
Authentication is not authorization (and the model is neither)
A distinction security engineers know cold but that LLM teams routinely collapse: authentication is establishing who a principal is; authorization is deciding what that principal may do. The session is authenticated as Alice. That is a true and useful fact. It is also where many LLM systems stop thinking, and the stopping is the bug.
The leap from "authenticated as Alice" to "the model, on Alice's behalf, may do anything Alice may do" is the disaster. Alice, as a human, may be able to read every record in her department, send email from her account, and update twenty kinds of CRM field. Those powers are appropriate for Alice exercising deliberate human judgment. They are not appropriate for a probabilistic component processing attacker-influenceable text as Alice. The model is neither the authenticator nor a trustworthy authorizer; it is a deputy acting under Alice's authentication, and authorization must be decided outside it, scoped to the task, not inherited wholesale from the user.
Concretely: the support copilot resolving a ticket needs to read this customer's plan and status. It does not need, and must not be granted, Alice's ability to read any customer, any field. The authorization for the model's actions should be the intersection of "what Alice may do" and "what this task requires, " and it should be enforced in the data and tool layers, not assumed because the session is Alice's. OWASP names the failure of over-granting here Excessive Agency (LLM06): the system has more functionality, permissions, or autonomy than the task warrants, so a manipulated model can reach further than it ever should.
Least privilege, applied to a probabilistic deputy
Saltzer and Schroeder's 1975 principle of least privilege, every component should operate with the minimum privileges needed for its task, is the single highest-return idea in this book, and it predates LLMs by half a century. For a deterministic component, least privilege limits the damage from bugs. For a probabilistic deputy that will sometimes be confused by its inputs, least privilege is not a nice-to-have; it is the primary control, because it is the thing that holds when every behavioral defense fails.
Least privilege for an LLM application decomposes along several axes, and a mature design applies it on all of them:
- **Data scope. ** The model can read the minimum data the task needs, scoped by tenant, by record, by field. Not "the user's whole CRM" but "these fields of this account for this ticket."
- **Tool scope. ** The model is exposed only the tools the task needs, and read tools are separated from write tools (Ch. 9). A summarization task does not get a delete tool in its manifest, ever.
- **Credential scope. ** Tools execute with narrowly scoped service credentials, not the application's god-mode key. A read tool's credential cannot write. A "send email to the ticket's customer" tool's credential cannot send to arbitrary addresses.
- **Action scope. ** High-impact actions are bounded by limits (amounts, rates, destinations) and gates (approval, dry-run), so even an authorized action cannot be amplified into a catastrophe (Ch. 10).
- **Temporal scope. ** Authority is granted for the task and revoked after, not held ambiently. A token good for one operation, not a standing grant.
The mental shift is from securing the model to starving it. You are not trying to make the deputy un-confusable. You are trying to ensure that a fully confused deputy is holding almost nothing worth misusing. Every privilege you decline to grant is an attack you do not have to detect.
Blast radius: the question that replaces "is it safe?"
"Is the system safe from prompt injection?" is an unanswerable question, because the honest answer is "the model can probably be confused, so no, not in the sense you mean." The answerable question, the one mature teams ask instead, is about blast radius: if untrusted text fully manipulates the model, what is the worst outcome, and is that outcome acceptable?
Blast radius is computed, not vibed. For a given feature, you enumerate what the model can read, write, call, and persist (the capability manifest, Ch. 10), and you ask, for each, what the worst-case misuse achieves. The discipline forces a number and a verdict per capability.
# A blast-radius assessment as code: enumerate capabilities, rate worst-case misuse,
# verify a deterministic control caps each. This runs as a pre-launch check.
from dataclasses import dataclass
from enum import IntEnum
class Impact(IntEnum):
NEGLIGIBLE = 0 # a weird sentence to the user only
LOW = 1 # discloses data the user could already see
MEDIUM = 2 # reversible action, or limited data exposure
HIGH = 3 # cross-user/tenant exposure, or hard-to-reverse action
CRITICAL = 4 # irreversible: money moved, data deleted, secrets leaked
@dataclass
class Capability:
name: str
worst_case: str # what a fully-manipulated model achieves with it
impact: Impact
deterministic_control: str | None # the gate that caps it, or None
reversible: bool
def assess(caps: list[Capability]) -> list[str]:
findings = []
for c in caps:
if c.impact >= Impact. HIGH and c.deterministic_control is None:
findings.append(f"BLOCKER: {c.name} is {c.impact.name} with NO deterministic control.")
if c.impact == Impact. CRITICAL and c.reversible is False and \
"human_approval" not in (c.deterministic_control or ""):
findings.append(f"BLOCKER: {c.name} is irreversible+critical without human approval.")
return findings or ["OK: all high/critical capabilities have deterministic caps."]
# Example, for the refund-capable agent of Chapter 17:
caps = [
Capability("summarize_ticket", "emit a wrong summary", Impact. NEGLIGIBLE, None, True),
Capability("read_account", "expose another tenant's data", Impact. HIGH,
"tenant_isolation_in_data_layer", True),
Capability("issue_refund", "refund attacker-chosen amount to attacker", Impact. CRITICAL,
"amount_cap + human_approval_over_threshold", False),]
print(assess(caps))This is the artifact that turns "is it safe?" into engineering. Every HIGH or CRITICAL capability must have a named deterministic control, or it is a launch blocker. Every irreversible critical action must pass human approval. The check fails the build if a dangerous capability is exposed without a cap. Notice what it does not do: it never asks "is the model good at refusing attacks?" The model's resistance is irrelevant to blast radius. Only the caps matter.
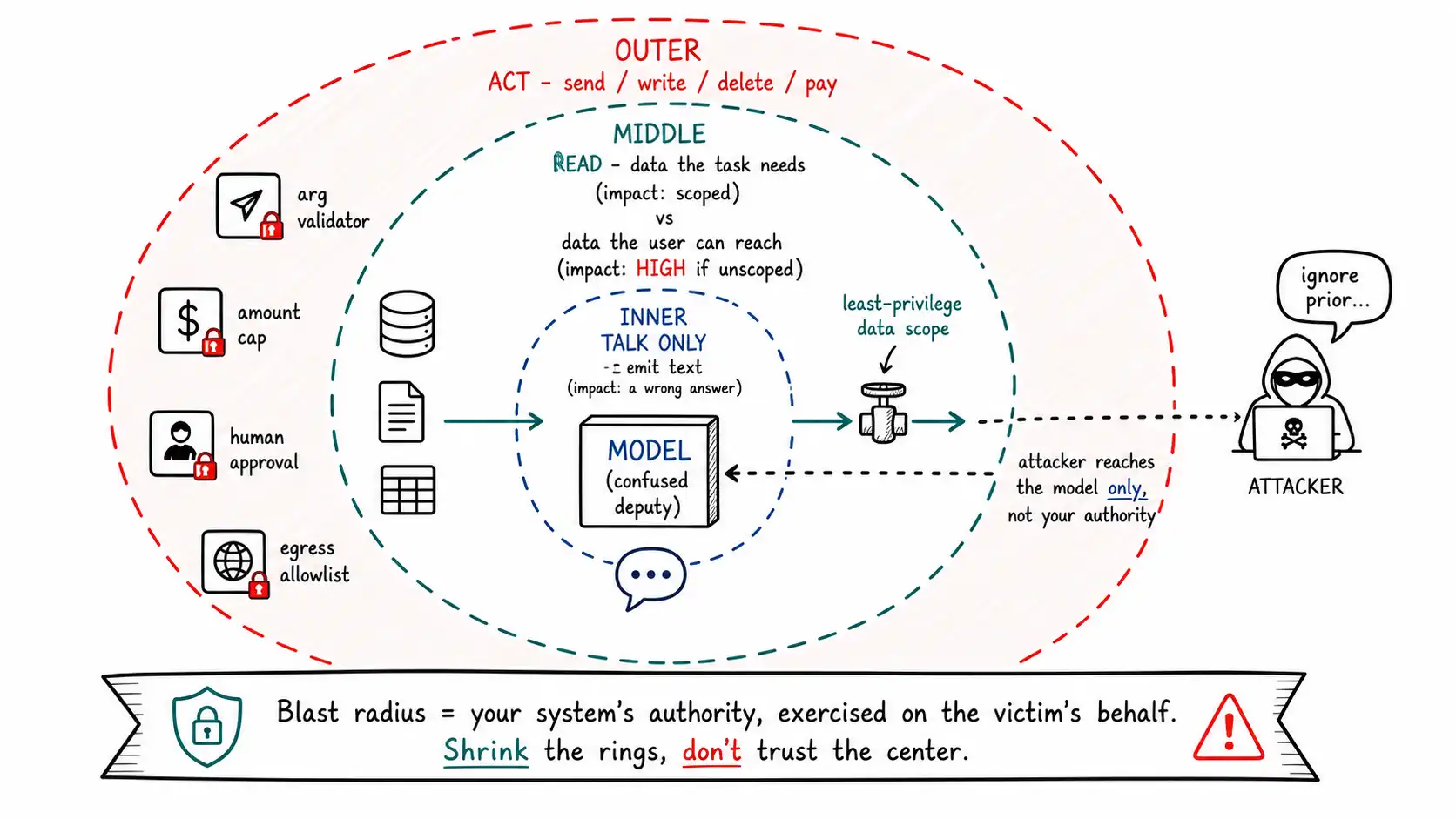
The blast-radius map
A picture helps a team feel the asymmetry between what the model can read and what it can do, because the two are governed differently.
The figure's geometry carries the argument. The attacker reaches only the center. The damage is the radius of the rings, and the radius is set by your grants, not the attacker's skill. Pinch the data valve (least privilege on reads), put gates on the outer ring (least privilege on actions), and a fully confused model still only sloshes around the inner ring producing wrong text, recoverable, observable, non-catastrophic.
Defense-in-depth, defined against a strawman
"Defense-in-depth" is said so often it has gone soft, so let us define it sharply and against the wrong version. The wrong version is "many layers of the same kind of defense", three input classifiers stacked, all probabilistic, all looking for the same patterns, all defeated by the same novel obfuscation. That is not depth; it is one layer painted three times, and an attacker who beats it once beats it thrice.
Real defense-in-depth is independent controls of different kinds at different points, so that an attacker who defeats one faces a qualitatively different obstacle at the next, and the probability of defeating all of them on the same input is the product of small numbers rather than a single small number. The support copilot's hardened design is depth done right: a probabilistic input/labeling layer (lowers the rate), then a deterministic data-scope boundary (the model literally cannot fetch the secret field), then a deterministic tool gate (the send literally cannot fire without review), then monitoring (the anomaly is logged even if everything else fails). Beating the labeling does nothing to the data scope. Beating the data scope, somehow, still leaves the tool gate. The layers do not share a failure mode, which is the entire point. Chapter 14 assembles the full stack; this chapter establishes why the layers must be different in kind, and the reason is the confused deputy: since you cannot stop the center from being confused, you surround it with checks that do not depend on it being un-confused.
The economics of starving the deputy
There is a practical objection: scoping is work, and product teams feel it as friction. Building a per-task scoped credential is harder than reusing the app's main key. Field-allowlisting a CRM read is harder than returning the whole record. Separating read and write tools is harder than one do-everything tool. The objection is real, and the answer is to be honest about the trade and then make the secure path the easy path.
The honest trade: least privilege has an up-front engineering cost and a near-zero ongoing cost, while the alternative, broad grants plus hope, has a near-zero up-front cost and a catastrophic tail cost (the incident, the disclosure, the cross-tenant breach, the regulator). NIST's AI RMF frames exactly this as risk management: you are trading a known, bounded engineering cost for a reduction in an unbounded, low-probability loss. For any capability whose worst case is HIGH or CRITICAL, that trade is not close.
Make the secure path easy by building scoping infrastructure once, a credential broker that vends task-scoped tokens, a data-access layer that takes a scope object, a tool registry that enforces manifests, so that product teams get least privilege by default rather than by heroics. The teams that get this right do not ask every engineer to remember to scope. They make broad access the thing you have to explicitly, visibly, reviewably ask for, and scoped access the default. That is the same move as "untrusted by default" from Chapter 3, applied to authority instead of text: the safe choice is the one that happens when no one is being clever.
Chapter summary
A successful injection's damage is bounded by your system's authority exercised on the victim's behalf, not by the attacker's privileges, this is Hardy's 1988 confused deputy problem with a language model as the deputy, and it tells you the control point is not in stopping confusion (you can't) but in limiting what a confused deputy can misuse. LLM teams collapse authentication (who the session is) into authorization (what the model may do), and the leap from "authenticated as Alice" to "the model may do anything Alice may do" is the bug; authorization must be decided outside the model, scoped to the task, not inherited from the user, OWASP calls over-granting here Excessive Agency.Least privilege, fifty years old and the highest-return idea in the book, applies on every axis, data scope, tool scope, credential scope, action scope, temporal scope, and the goal is to starve the deputy: every privilege you decline to grant is an attack you don't have to detect. Replace the unanswerable "is it safe?" with the computable blast radius: enumerate what the model can read/write/call/persist, rate each capability's worst-case misuse, and require a named deterministic control on every HIGH/CRITICAL one (human approval on every irreversible CRITICAL one), failing the build otherwise, never consulting the model's "resistance." Defense-in-depth means independent controls of different kinds at different points, so beating one is no help against the next; stacking three of the same probabilistic classifier is one layer painted thrice. The economics favor scoping, bounded up-front cost versus an unbounded tail loss, so build scoping infrastructure once and make least privilege the default that happens when no one is being clever.