Read Tools, Write Tools, and the Argument Nobody Validated
> **Working claim: ** A model that can only emit text produces, at worst, a wrong sentence. The moment you give it a tool, you give injection a way to reach the world.

Read Tools, Write Tools, and the Argument Nobody Validated is about the point where prompt injection stops being text and starts reaching systems.
Key Takeaways
- Read tools and write tools carry different risk; write tools turn model confusion into external effects.
- The argument is often the attack, so validating shape without validating meaning is not enough.
- Structured outputs help parsing but do not decide whether a requested action is authorized.
- Treat the model as a client and the tool layer as a hardened server with policy checks.
Read this beside Tools, Permissions, and Side Effects, Agents That Actually Work, and Devlyn's AI agents and workflow automation before exposing write tools.
**Working claim: ** A model that can only emit text produces, at worst, a wrong sentence. The moment you give it a tool, you give injection a way to reach the world. The danger of a tool is not whether the model calls it but what the call does and what arguments it carries, and the place almost every team is exposed is the tool argument, which is model-generated, attacker-influenceable, and validated by no one before it executes against a real system.
The line between talk and impact
Everything before this chapter has been about influence, text steering a model. This chapter is about the moment influence becomes effect. The pivot is the tool call. Up to the tool boundary, a compromised model has produced tokens; past it, the model has caused something to happen in a real system: an email sent, a record updated, a query run, a file deleted, a payment moved. The tool boundary is therefore the single most important place to spend your security budget, because it is where the abstract risk of "the model can be confused" turns into the concrete risk of "the model did something."
OWASP's Excessive Agency (LLM06) is the named risk here, and its three sub-causes are worth memorizing because they are the three knobs you actually control: excessive functionality (the tool can do more than the task needs), excessive permissions (the tool's credentials can reach more than the task needs), and excessive autonomy (the tool acts without a check the impact warrants). Notice that none of the three is "the model got confused." All three are design choices about what the model is allowed to reach, which is the good news, because design choices are yours to make.
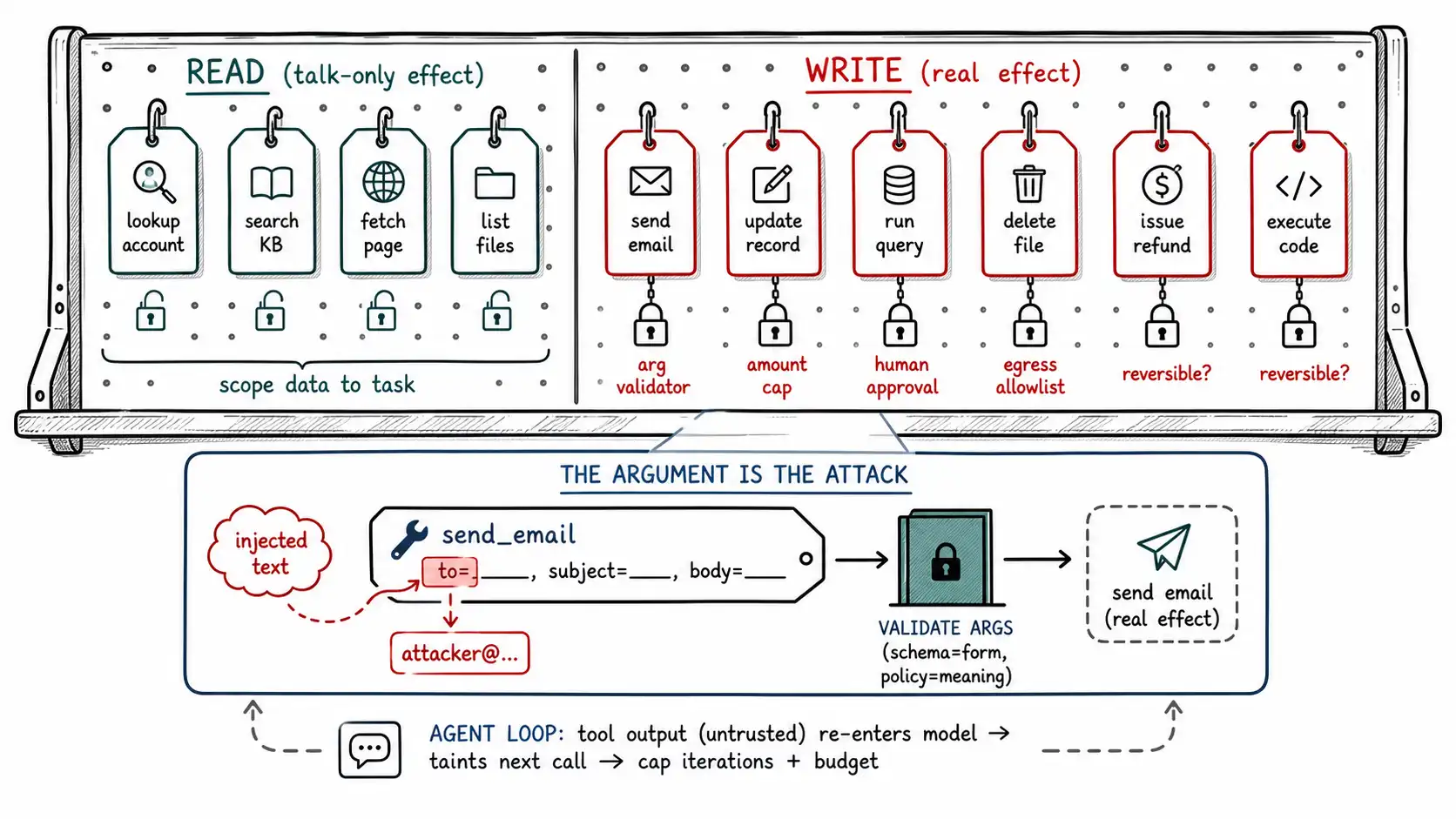
Read tools and write tools are different animals
The first and most useful taxonomy is by effect, and the line is between reading and writing.
Read tools retrieve information: look up an account, search the knowledge base, fetch a webpage, query a database, list files. Their primary risk is confidentiality, they can surface data into the model's context (and from there toward exfiltration, Ch. 11), and trust, because their output is untrusted content that re-enters the model (Ch. 7). A read tool, properly scoped, cannot directly change the world; its damage is bounded by what it can read and where that data can subsequently flow. The defense for read tools is mostly the data-access ACL (Ch. 8): scope what they can read to the task and the user's authority.
Write tools change state: send an email, update a record, create a ticket, delete a file, move money, execute code, open a URL that has side effects. Their risk is integrity and availability and, for the irreversible ones, finality. A write tool turns a confused model into an actor with consequences. The defense for write tools is the tool-call gate, argument validation, limits, and approval (Ch. 10).
The cardinal architectural rule that falls out of this distinction: **never expose a write tool when a read tool would do, and never combine read and write in one tool. ** A "manage_account" tool that can both read and update is a write tool with a read tool's casual reputation; an injected instruction that reaches it reaches update. Separate them, expose the narrowest, and the most common task, answering a question, never has a write capability in scope at all. The support copilot from Chapter 1 was, in its hardened form, exactly this: read and draft, never send. The separation is what made it a near-miss instead of a breach.
| Read tools | Write tools | |
|---|---|---|
| Effect | Surface information | Change state / cause action |
| Primary risk | Confidentiality, trust of output | Integrity, availability, finality |
| Worst case from injection | Data flows toward exfiltration | Unauthorized/irreversible action |
| Primary control | Data-access ACL, output-as-untrusted | Tool gate, arg validation, limits, approval |
| Default exposure | Only the fields/sources the task needs | Only when the task demonstrably requires it |
| Reversibility | N/A | Prefer reversible; gate irreversible hardest |
The argument is the attack
Here is the exposure almost every team misses, stated bluntly: **the dangerous part of a tool call is usually not which tool, but the arguments. ** Teams reason about tools at the granularity of "should the model have a send-email tool?" and stop, having decided yes because the product needs it. But a send-email tool is called with arguments, recipient, subject, body, attachments, and those arguments are generated by the model, which means they are influenced by everything in the model's context, which includes attacker-authored text. The injection does not need to add a tool; it needs to bend the arguments of a tool you already, correctly, exposed.
Consider the shapes, described as test cases for your own validator, never as recipes:
- A send tool with a model-chosen recipient: injection bends the recipient to an attacker address. The tool is legitimate; the argument is the exploit.
- A database query tool with a model-generated filter: injection widens the filter to return rows the user shouldn't see, or, if the tool naively interpolates, injects query syntax.
- A file tool with a model-chosen path: injection points it at a sensitive file (the confused-deputy compiler from Ch. 4, exactly).
- An HTTP tool with a model-chosen URL: injection points it at an attacker-controlled endpoint, turning a "fetch" into exfiltration or SSRF (Ch. 11).
- A refund tool with a model-chosen amount and destination: injection sets both.
In every case the tool is one you meant to expose and the argument is where the attack lives. This reframes validation: it is not enough to gate whether a tool runs; you must validate what arguments it runs with, against a schema and a policy, deterministically, before execution. OWASP's Insecure Output Handling risk is precisely this, treating model output (including tool-call arguments) as untrusted input to the downstream system, the way you would treat a form field from a browser.
# The exposure: model output flows DIRECTLY into a real effect. The recipient,
# the amount - all model-generated, all attacker-influenceable, none validated.
def execute_tool_call_VULNERABLE(call):
if call.name == "send_email":
smtp.send(to=call.args["to"], subject=call.args["subject"], body=call.args["body"])
elif call.name == "issue_refund":
payments.refund(amount=call.args["amount"], to=call.args["destination"])
# The model said so, so it happens. This is the whole bug.The fix is the subject of Chapter 10, but the principle starts here: a tool call emitted by the model is a request, not a command. It is a proposal from an untrusted interpreter that must be parsed, schema-validated, policy-checked, and possibly approved before it becomes an effect. The model proposes; the deterministic gate disposes.
Structured outputs: necessary, not sufficient
Before the gate, one upstream discipline reduces a whole category of risk: make the model emit tool calls and structured results through a constrained schema rather than free text you parse heuristically. Structured outputs: JSON-schema-constrained generation, or the native tool-calling interfaces, guarantee the shape of the output: the recipient field is a string, the amount is a number, the action is one of an enumerated set. This kills the class of attacks that rely on the model emitting malformed or out-of-band content that your fragile parser mishandles, and it gives your validator clean, typed fields to check.
But structured output is necessary and not sufficient, and conflating the two is a trap. A schema guarantees the amount is a number; it does not guarantee the number is reasonable. A schema guarantees the recipient is a well-formed email; it does not guarantee the recipient is allowed. A schema constrains form, not meaning. The injected refund still type-checks as a valid number to an attacker's valid email. So structured output is the floor, always do it, it removes the parsing-attack surface and feeds the validator, and the value/policy validation in Chapter 10 is the wall. The mistake is shipping structured outputs and feeling protected, the same false floor as the input classifier in Chapter 6.
from pydantic import BaseModel, EmailStr, conint
class SendEmailArgs(BaseModel): # schema constrains FORM
to: EmailStr # well-formed address (not: allowed address)
subject: str
body: str
class IssueRefundArgs(BaseModel):
amount_cents: conint(gt=0) # positive integer (not: reasonable amount)
destination_account_id: str
# A valid SendEmailArgs(to="attacker@evil.test", ...) PASSES the schema.
# Form is checked. Meaning and authority are NOT. That is Chapter 10's job.Agent loops multiply the surface
A single tool call is dangerous; an agent loop, model proposes a tool, tool returns output, output re-enters the model, model proposes the next tool, repeat, multiplies the danger in two ways that deserve naming.
First, tool outputs are untrusted content that re-enters the context (Ch. 7). An agent that browses a page, reads the result, and decides what to do next has fed attacker-authored text back into its own reasoning. The injection in the page can now steer the next tool call. This is the mechanism behind the scariest browser-agent attacks: the agent visits an attacker page, the page's content hijacks the agent, and the agent, now executing the attacker's plan, uses its other tools (email, files) against the user. The loop turns one poisoned read into a chain of writes.
Second, the loop can be driven to escalate. Each step seems locally reasonable; the aggregate is an attack. An injected instruction can patiently walk the agent toward a goal across many steps, each below whatever per-step threshold you set, defeating defenses that examine steps in isolation (the multi-turn problem from Ch. 5, now with tools). This is why per-action gates must consider the cumulative effect of a session, total spend, total records touched, total external sends, not just the current call (Ch. 10).
The architectural responses, previewed here: cap loop iterations and total tool budget per session; re-evaluate trust after every tool output (a result from an untrusted source taints subsequent decisions and should restrict capabilities); and never let read-tool output silently expand write-tool authority. An agent that browsed an untrusted page should not, in the same loop, be allowed to send email without a fresh, explicit, human-confirmed reason.
The mental model: the model is a client, the tool layer is a server
The cleanest way to hold all of this is a borrowed pattern every backend engineer knows. **Treat the model as an untrusted client and the tool layer as a hardened API server. ** You would never let a browser client's request directly execute a privileged operation because the client "asked nicely"; you authenticate it, authorize the specific action, validate every parameter against a schema and business rules, enforce rate limits and quotas, and log everything. The model's tool call deserves exactly the same treatment, for exactly the same reason: it is a request from a component you do not control, carrying parameters you cannot trust, and the server's job is to be the boundary.
This reframe dissolves a lot of confusion. People ask "how do I make the model not call the wrong tool?", a probabilistic, model-side question with no clean answer (see Greshake et al. for documented cases where attacker-authored text caused exactly this failure in real deployed applications). The server-side reframe replaces it with "how does my tool API authorize and validate this request?", a deterministic, well-understood question that backend security has answered for thirty years. You do not have to invent new security for tool calls. You have to apply old security to a new kind of client, and the new client just happens to be more easily talked into sending malicious requests than a normal one. Chapter 10 builds that hardened server: the capability manifest (what's even exposed), the policy engine (authorize the action and arguments), the limits and approval flows (cap the impact), and the audit log (see what happened).
Chapter summary
The tool call is where influence becomes effect, the most important place to spend security budget (the OWASP Prompt Injection Prevention Cheat Sheet covers mitigation patterns at this layer), and OWASP's Excessive Agency names its three controllable causes: excessive functionality, permissions, and autonomy, none of which is "the model got confused." Tools split by effect into read tools (risk: confidentiality and untrusted output re-entering the model; control: data-access ACL) and write tools (risk: integrity, availability, finality; control: tool gate, arg validation, limits, approval), yielding the cardinal rule: never expose a write tool when a read tool would do, and never combine read and write in one tool, separation is what made the Chapter 1 copilot a near-miss. The exposure almost everyone misses is that the argument is the attack: the dangerous part of a call is usually not which tool but the model-generated, attacker-influenceable arguments, recipient, filter, path, URL, amount, so you must validate what arguments run, deterministically, before execution, treating model output as untrusted input per OWASP Insecure Output Handling. Structured outputs (schema-constrained generation, native tool-calling) are necessary, they kill parsing attacks and give the validator typed fields, but not sufficient: a schema constrains form, not meaning, so the injected refund still type-checks. Agent loops multiply the surface because tool outputs are untrusted content re-entering the context (one poisoned read drives a chain of writes) and because injections can escalate below per-step thresholds, demanding cumulative budgets and post-tool trust re-evaluation. The unifying mental model: treat the model as an untrusted client and the tool layer as a hardened API server, authenticate, authorize the specific action and parameters, rate-limit, log, which replaces the unanswerable "make the model not call the wrong tool" with the thirty-year-solved "how does my API authorize and validate this request, " built out in Chapter 10.