Capability Manifests, Tool-Call Gates, and Approval Flows
> **Working claim: ** This is the chapter where the book's central promise becomes a system you can build. The model is an untrusted client; the tool layer is a hardened server.

Capability Manifests, Tool-Call Gates, and Approval Flows turns the book's claim into a buildable tool-security system.
Key Takeaways
- A capability manifest makes absence a control: a tool outside the manifest cannot be called by injection.
- The tool-call gate enforces policy outside the model, checking tool membership, arguments, budgets, and approvals.
- Human approval works only when it receives a decision packet, not a vague model request.
- Audit logs must reconstruct why a tool call happened, which inputs influenced it, and which gate allowed or denied it.
Read this beside Read Tools, Write Tools, and the Argument Nobody Validated, Human Handoffs and Approvals, and Devlyn's AI security and red-teaming work.
**Working claim: ** This is the chapter where the book's central promise becomes a system you can build. The model is an untrusted client; the tool layer is a hardened server. Between them sits a gate that answers, deterministically and outside the model, four questions for every proposed action: Is this tool even allowed here? Are these arguments valid and in-policy? Is the cumulative impact within budget? Does this effect need a human? Build that gate and a fully confused model can still do almost nothing irreversible.
The capability manifest: a contract for what's even possible
Before any runtime check, there is a design-time artifact: the capability manifest, an explicit, reviewable declaration of every tool the system may call, what each does, what arguments it takes, how dangerous it is, and what controls cap it. The manifest is to an agent what a permissions file is to a mobile app, the single place where "what can this thing do?" is answered, in version control, reviewable in a pull request, auditable by security.
The manifest matters because the alternative is implicit capability: tools registered scattered across the codebase, exposed to the model by whoever added a feature, with no single place that answers "what is the full set of things a confused model could do?" The OWASP LLM Top 10 names this Excessive Agency (LLM06) and the OWASP Prompt Injection Prevention Cheat Sheet recommends manifest-level controls as a primary mitigation. That question must have a crisp, enumerable answer, and the manifest is it. If you cannot produce your system's manifest in under a minute, you do not know your blast radius (Ch. 4), and neither does your attacker, until they find out experimentally.
# capability-manifest.yaml - the complete, reviewed set of what the agent can do.
# If a tool isn't here, the model cannot call it. Default: deny.
agent: support-copilot
version: 7
tools:
- name: lookup_account
kind: read
args: { account_id: {type: string, source: from_ticket_context} }
data_scope: { fields_allow: [plan, status, region], fields_deny: [ssn, full_txns, payment_method] }
risk: low
controls: [acl_tenant_isolation]
- name: search_kb
kind: read
args: { query: {type: string} }
risk: low
controls: [retrieval_acl, untrusted_evidence_framing]
- name: draft_reply
kind: write_local # produces a draft; no external effect
args: { body: {type: string} }
risk: low
controls: [pii_egress_scan_on_draft]
- name: send_reply
kind: write_external
args: { to: {type: email, policy: must_equal_ticket_requester}, body: {type: string} }
risk: high
controls: [arg_policy, recipient_allowlist, human_approval] # never autonomous
- name: issue_refund
kind: write_external
args:
amount_cents: {type: int, policy: "0 < x <= 5000"} # hard cap in policy
destination: {type: string, policy: must_equal_account_on_file}
risk: critical
controls: [arg_policy, amount_cap, destination_lock, human_approval, daily_budget]
# Tools NOT listed (delete_account, export_all, run_shell, open_arbitrary_url)
# are simply absent. Absence is the strongest control: the model cannot propose
# what the gate does not know how to execute.Three design choices in this manifest are load-bearing. The data_scope on lookup_account field-allowlists, denying secrets at the data layer (Ch. 8) so a confused model cannot even retrieve them. The policy expressions on argument fields (must_equal_ticket_requester, 0 < x <= 5000, must_equal_account_on_file) move meaning validation into the manifest, these are the checks structured output cannot do (Ch. 9). And the comment about absent tools states the strongest control of all: the most dangerous tools are not gated, they are not exposed, because a capability the model has no way to invoke is a capability no injection can reach. Least privilege at the manifest level is the cheapest, hardest boundary you own.
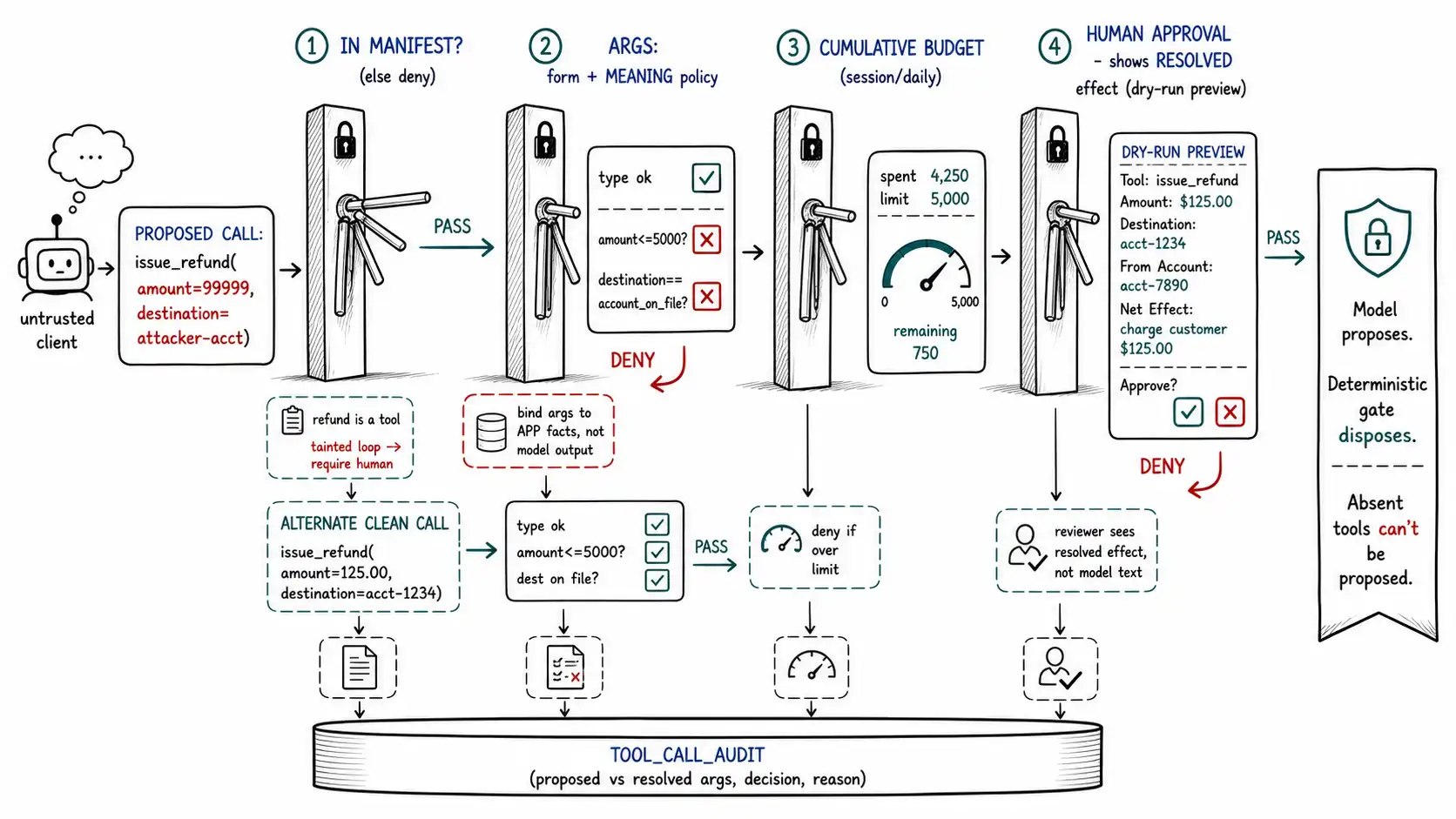
The tool-call gate: the policy engine outside the model
The manifest is static; the gate is the runtime enforcement. Every tool call the model proposes passes through it before any effect, and it answers four questions in order, denying by default at every step.
from dataclasses import dataclass
@dataclass
class ToolCall:
name: str
args: dict
proposed_by: str # which model/turn - provenance for audit
@dataclass
class GateContext:
manifest: dict
user: object
session: object # cumulative budgets live here
tainted_by_untrusted: bool # set if untrusted tool output entered this loop (Ch.9)
class Decision:
@staticmethod
def deny(reason): return ("deny", reason)
@staticmethod
def allow(): return ("allow", None)
@staticmethod
def require_human(reason): return ("require_human", reason)
def tool_call_gate(call: ToolCall, ctx: GateContext):
spec = ctx.manifest["tools"].get(call.name)
# Q1 - Is this tool allowed here AT ALL? (manifest membership + context)
if spec is None:
return Decision.deny(f"tool '{call.name}' not in manifest") # absence = deny
if spec["kind"] == "write_external" and ctx.tainted_by_untrusted:
# An agent loop that read untrusted content may not silently gain write power.
return Decision.require_human("external write after untrusted tool output")
# Q2 - Are the ARGUMENTS valid (form) and in-policy (meaning)?
ok, why = validate_args_against_policy(call.args, spec["args"], ctx) # schema + policy exprs
if not ok:
return Decision.deny(f"arg policy: {why}")
# Q3 - Is the CUMULATIVE impact within session/daily budget?
if not within_budget(call, spec, ctx.session): # spend, sends, rows
return Decision.deny("budget exceeded") # caps escalation loops
# Q4 - Does this EFFECT require a human?
if spec["risk"] in ("high", "critical") or "human_approval" in spec.get("controls", []):
return Decision.require_human(f"{spec['risk']}-risk action requires approval")
return Decision.allow()The gate is short, deterministic, and outside the model, which is exactly why it is a boundary. Notice the order: membership first (cheapest, and absence ends it), then argument policy (the meaning checks), then cumulative budget (defeats slow-escalation agent loops, Ch. 9), then the human gate for high-impact effects. Every branch returns a reason, and every decision, allow, deny, require-human, is logged for forensics (Ch. 16). The tainted_by_untrusted flag implements the agent-loop discipline from Chapter 9: if the loop has read attacker-controlled content, an external write is forced to human review rather than fired autonomously, because the model's "decision" to write is now downstream of an untrusted influence. This is Microsoft's layered posture, assume the model may be manipulated, and put deterministic checks between it and effect, in a few dozen lines.
Argument validation: form and meaning
Chapter 9 established that the argument is the attack and that structured output checks form but not meaning. The gate's Q2 is where meaning gets checked. Argument validation has two layers stacked.
Form (from structured output): the field is the right type, present, well-shaped. An email field is a valid email; an amount is a positive integer. This is the structured-outputs layer and it should be enforced at generation time so malformed calls never reach the gate.
Meaning (the policy expressions): the value is allowed in this context. The recipient equals the ticket's actual requester (not an arbitrary attacker address the model was talked into). The refund amount is within the cap. The destination equals the account on file (not an attacker's account). The file path is within an allowed directory. The URL is on the egress allowlist (Ch. 11). These checks need context, the ticket, the account, the session, that only the application has, which is why they live in the gate and not in the schema.
def validate_args_against_policy(args, arg_specs, ctx):
for field, spec in arg_specs.items():
val = args.get(field)
# FORM (defense in depth even though structured output should have ensured it)
if not matches_type(val, spec["type"]):
return False, f"{field}: bad type"
# MEANING - the policy expression, evaluated against application context
policy = spec.get("policy")
if policy == "must_equal_ticket_requester" and val!= ctx.session.ticket.requester_email:
return False, f"{field}: recipient not the ticket requester"
if policy and policy.startswith("0 <") and not eval_numeric_bound(policy, val):
return False, f"{field}: out of allowed range"
if policy == "must_equal_account_on_file" and val!= ctx.user.account_on_file:
return False, f"{field}: destination not the account on file"
if spec["type"] == "url" and not on_egress_allowlist(val):
return False, f"{field}: url not on egress allowlist"
return True, NoneThe pattern to internalize: **bind dangerous arguments to application facts, not to model output. ** The safest send tool does not accept a model-chosen recipient at all, it accepts no recipient and sends to the ticket requester the application looked up. The safest refund tool does not accept a model-chosen destination, it refunds to the account on file. Wherever you can, remove the dangerous argument from the model's control entirely and let the application supply it from trusted context. The argument the model cannot set is the argument the injection cannot bend. This is the strongest form of argument validation: not checking the model's value, but never asking the model for the value.
Approval, dry-run, and the limits of human-in-the-loop
For effects that survive the manifest and the gate as require_human, the approval flow is the last boundary. Done right it is powerful; done lazily it is theater, and the difference is worth being precise about.
A real approval flow shows the human the exact effect that will occur, the resolved recipient, the resolved amount, the resolved destination, the full body, in a form they can actually evaluate, and requires an affirmative action to proceed, with the default being no action = no effect. A dry-run mode is the supporting discipline: the system computes and displays what would happen (the diff, the outbound message, the records that would change) without executing, so the human reviews a concrete preview rather than an abstract intent. The support copilot's human review worked in Chapter 1 because the agent saw the actual draft with the actual data in it and recognized it was wrong, the effect was concrete and reviewable.
But human-in-the-loop has real limits that you must design around honestly, or it becomes the weakest link disguised as the strongest:
- **Approval fatigue. ** Ask for approval on everything and humans rubber-stamp. Reserve the gate for genuinely high-impact, hard-to-reverse effects (the manifest's
riskfield), and let low-stakes reversible actions flow, so the human's attention is spent where it matters. - **The reviewer must see the real thing. ** An approval that shows "send email?" without showing the resolved recipient and body is theater, the human cannot catch the bent argument they cannot see. Always render the concrete, resolved effect.
- **Humans can be socially engineered too. ** An injection can craft a draft that looks legitimate to a rushed reviewer. Approval reduces risk; it does not eliminate it, which is why it stacks on top of argument binding and limits rather than replacing them.
- **It doesn't scale to high volume. ** For high-throughput low-stakes actions, the control is limits and monitoring, not per-action approval. Match the control to the impact.
The design principle: **make the irreversible reversible wherever possible, and gate the truly irreversible with human approval that shows the real effect. ** A "delete" that is a soft-delete with a recovery window needs less gating than a hard delete. A "send" that can be recalled within a minute is safer than one that cannot. Reversibility is a security property; engineer for it, and you reduce how much you must lean on the fallible human.
The audit log: you cannot defend what you cannot reconstruct
Every gate decision, every allow, deny, and human-approval, with the proposed call, the resolved arguments, the policy outcome, and the reason, is logged. This is not optional bookkeeping; it is the substrate of detection (Ch. 16) and the only way to answer, after an incident, *what did the model try to do, what did the gate stop, and what got through. *
CREATE TABLE tool_call_audit (
id BIGSERIAL PRIMARY KEY,
request_id TEXT NOT NULL, -- ties to the session/turn
tool_name TEXT NOT NULL,
proposed_args JSONB NOT NULL, -- what the model wanted (redact secrets)
resolved_args JSONB, -- what app-bound facts produced
decision TEXT NOT NULL, -- allow | deny | require_human | approved | rejected
reason TEXT, -- policy/budget/taint reason
tainted BOOLEAN NOT NULL, -- was the loop touched by untrusted content?
risk TEXT NOT NULL,
actor TEXT, -- who approved, if human gate
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
-- A spike of denies for one tool, or proposed_args with out-of-scope recipients,
-- is your earliest signal that a session is under injection. (Ch. 16)The proposed_args versus resolved_args distinction is forensic gold: it records what the model wanted (which reveals the injection's intent) versus what the application bound (which reveals what the boundaries enforced). A pattern of proposed_args with attacker-shaped recipients and decision = deny is a system successfully defending and simultaneously telling you you're under attack, exactly the signal Chapter 16 turns into alerting.
Chapter summary
This chapter builds the boundary the whole book points at, treating the model as an untrusted client and the tool layer as a hardened server. The capability manifest is the design-time contract, every tool, its args, its risk, its controls, in version control and reviewable; its strongest control is absence, because a tool not in the manifest cannot be proposed by any injection, so the most dangerous capabilities are not gated but simply not exposed (least privilege at the manifest level). The tool-call gate is the runtime policy engine outside the model, denying by default and answering four ordered questions per proposed call: is the tool allowed here (membership, plus forcing human review on external writes after an untrusted-tainted loop), are the arguments valid in form (structured output) and meaning (policy expressions evaluated against application context), is the cumulative impact within session/daily budget (defeating slow-escalation agent loops), and does the effect need a human. Argument validation's deepest move is to bind dangerous arguments to application facts, not model output, the recipient the app looked up, the account on file, because the argument the model cannot set is the argument the injection cannot bend. Approval flows are the last boundary and must show the human the resolved, concrete effect (dry-run preview), reserve the gate for high-impact irreversible actions to avoid rubber-stamping, acknowledge that reviewers can be socially engineered, and lean on reversibility as a security property so the truly irreversible is rare (the NIST AI Risk Management Framework frames gate design as risk management: engineering a bounded cost to cap an unbounded tail loss). Everything is recorded in a tool-call audit log whose proposed_args-versus-resolved_args distinction is forensic gold: it shows what the injection wanted versus what the boundaries enforced, and a pattern of denied attacker-shaped calls is simultaneously a system defending and a system telling you it is under attack.