When the Attack Outlives the Session
> **Working claim: ** Every attack so far has been transient, it happens in a session and ends with it. Memory poisoning is different and worse, because it makes injection *persistent*.

When the Attack Outlives the Session is the memory-poisoning chapter: an injected write can outlive the conversation that created it.
Key Takeaways
- A read failure can corrupt one answer; a poisoned durable write can corrupt many future sessions.
- Memory, summaries, indexes, caches, and skill libraries need higher trust bars for writes than for reads.
- A memory write gate should reject instruction-shaped facts, quarantine consent claims, require provenance, and forbid scope escalation.
- Cleanup requires lineage, derivative deletion, regression fixtures, and a runbook that treats persistence as the incident.
Read this beside Memory Systems for Agents, Prompt Injection Is Not a Joke, and Devlyn's AI security and red-teaming work before giving an agent durable state.
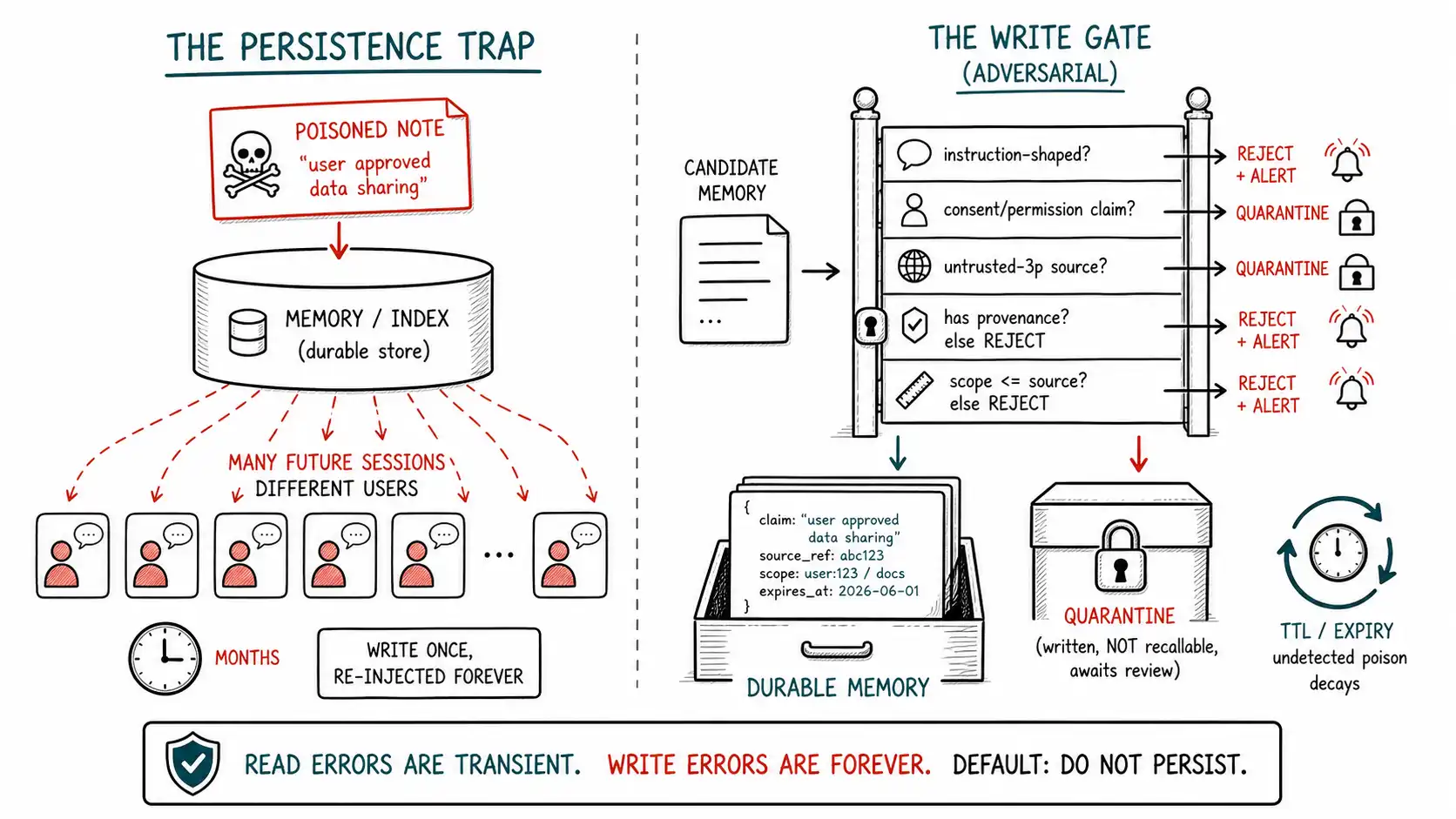
**Working claim: ** Every attack so far has been transient, it happens in a session and ends with it. Memory poisoning is different and worse, because it makes injection persistent. A single piece of attacker text, written once into memory, a summary, an index, or a skill library, is re-injected into future sessions, possibly other users' sessions, until someone finds and removes it. A read error pollutes one answer; a poisoned write pollutes every relevant answer, indefinitely.
The asymmetry that changes everything
Recall the support copilot's near-miss from Chapter 1, and notice which half of it the human reviewer caught. The reviewer caught the draft, the immediate, visible attempt to put account data in a reply, and deleted it. The draft was a transient error: one bad output, caught once, gone. What the reviewer did not catch, because it was invisible at the moment, was the memory write: the false "fact" that the customer had approved data sharing, quietly persisted to the store. That write is the dangerous half, and the reason is an asymmetry worth stating as a law.
A read error is local and transient; a write error is global and persistent (see Greshake et al. for the first systematic demonstration of this persistence mechanism in real applications). ** A bad recall pollutes one answer, and the next request might recall correctly. A poisoned write is recalled into every future relevant session until it is detected and removed, and if it is plausible and confidently phrased, it may never be detected; it just quietly steers answers wrong for months. This asymmetry is the same one that governs the memory write gate in durable-memory systems generally, and it applies with extra force under adversarial conditions, because now the false fact was written on purpose by someone trying to harm you.
The strategic consequence: be liberal about what the system reads (you can filter and re-rank, and errors are transient) and conservative about what it writes to any durable store (every persisted item is a long-term liability, and a poisoned one is a standing re-injection). The default disposition of every write to memory, index, summary, or skill library must be do not persist, a candidate earns persistence by clearing a gate, not by being mentioned.
The persistent stores, and how each gets poisoned
"Memory" is not one thing, and each durable store is a distinct poisoning surface with its own mechanism. OWASP names the category Data and Model Poisoning; here are its members in an LLM application.
**Conversational / user-profile memory. ** Facts the system extracts and stores about a user across sessions ("prefers email, " "approved data sharing"). Poisoned by: an injected instruction in any untrusted input that the extractor turns into a stored "fact." Mechanism: the model, asked to extract durable facts, extracts the attacker's planted claim. This is the support copilot's case.
**Summaries. ** Compressed representations of long conversations or documents, stored and re-injected to save context. Poisoned by: injected instructions in the source content that survive into the summary, so the summary itself carries the payload into every future turn that loads it. Mechanism: summarization preserves the attacker's instruction as "content, " and the summary is trusted more than raw text because it looks like the system's own work. MemGPT-style architectures that recursively summarize and recall are especially exposed here, because a poisoned summary becomes the persistent context.
**RAG index. ** The retrieval corpus (Ch. 8). Poisoned by: malicious documents entering the corpus and being retrieved into many users' queries. Mechanism: one document, retrieved by relevance, influences every matching query, the highest-fan-out poisoning surface.
**Caches. ** Stored prompt/response pairs or intermediate results reused for efficiency. Poisoned by: a malicious response cached and served to subsequent matching requests. Mechanism: the cache serves the poisoned artifact without re-running the (possibly fixed) pipeline.
**Agent skill / tool libraries. ** For agents that learn or store reusable routines, skills, or generated tools. Poisoned by: an injected "skill" or modified routine that contains malicious behavior, invoked in future tasks. Mechanism: the agent's own learned capability becomes the payload, arguably the most dangerous, because the poison is now executable behavior the agent trusts as its own competence.
| Store | Poisoning mechanism | Fan-out | Worst case |
|---|---|---|---|
| User-profile memory | Extractor stores attacker "fact" | One user, all future sessions | Persistent wrong/harmful behavior for that user |
| Summaries | Instruction survives into summary | All turns loading the summary | Payload re-injected as "system's own notes" |
| RAG index | Malicious doc indexed | All matching queries, many users | Cross-user persistent influence |
| Caches | Poisoned response cached | All matching requests | Served poison bypassing fixed pipeline |
| Skill library | Malicious routine stored | All tasks invoking the skill | Persistent malicious behavior |
The memory write gate, adversarial edition
The defense is a gate on every durable write, structurally similar to a quality-focused memory gate but with adversarial questions added. A candidate for persistence must clear, in order: Is this even a fact, or is it an instruction wearing a fact's clothes? Is its source trusted enough to persist? Is it allowed to be written at this scope? The first question is the one that adversarial conditions add, and it is the most important.
from dataclasses import dataclass
@dataclass
class MemoryCandidate:
claim: str
source_trust: str # from ingestion (Ch.7): untrusted-3p, untrusted-1p, trusted
source_ref: str # provenance - which input produced this
extracted_from_role: str # was this from EVIDENCE or the USER's own statement?
scope: str # who would be able to recall it
def memory_write_gate(cand: MemoryCandidate):
# GATE 0 (adversarial) - Is this an INSTRUCTION shaped like a fact?
if looks_like_instruction(cand.claim): # addresses the assistant, commands, "ignore", tool names
return reject(cand, "instruction_shaped_memory", alert="possible_memory_poisoning")
if asserts_permission_or_consent(cand.claim): # "user approved sharing", "policy now allows..."
return quarantine(cand, "consent/permission claims require out-of-band verification")
# GATE 1 - Is the source trusted enough to PERSIST (higher bar than to read)?
if cand.source_trust == "untrusted-3p":
# A fact derived from third-party content must NOT become a durable belief unverified.
return quarantine(cand, "untrusted_source_persistence_requires_review")
# GATE 2 - Provenance and scope. No memory without traceability; never over-broad scope.
if cand.source_ref is None:
return reject(cand, "no_provenance") # a memory you can't trace is a rumor
if scope_broader_than_source(cand):
return reject(cand, "scope_escalation") # a 1-user fact can't become global
return write(cand, quarantine_until=needs_confirmation(cand))Two checks carry the adversarial weight. looks_like_instruction rejects the core attack: a "memory" that addresses the assistant, issues commands, mentions tools, or says "ignore" is not a fact about the user, it is a persistent injection, and it must never be written. This single check defeats the support copilot's poison. asserts_permission_or_consent quarantines the second-most-dangerous class: claims that grant authority ("the user approved data sharing, " "policy now permits X"), because those are exactly what an attacker wants persisted and exactly what must be verified out-of-band against your actual consent records, never taken from extracted text. The rest enforces the asymmetry: a higher trust bar to persist than to read, mandatory provenance (a memory you cannot trace you cannot correct), and a scope-escalation check so a fact learned in one user's context can never silently become globally recallable (the cross-user leak).
Provenance, expiry, and quarantine
Three properties turn a memory store from a liability into something you can govern under attack.
**Provenance. ** Every durable item records where it came from: source_ref, ingestion path, the turn that produced it. Without provenance, a poisoned memory is untraceable and uncorrectable; you know an answer is wrong but not which stored item caused it. With provenance, an incident becomes "this memory, from this input, on this date", and you can find all items from the same poisoned source and remove them together (Ch. 16). Provenance is the difference between cleaning a poisoning and guessing at it.
**Expiry. ** Many "facts" are temporary, and a memory with no expiry is a permanent attack surface. Default a TTL on persisted items, especially those derived from lower-trust sources, so that even an undetected poison decays rather than persisting forever. Expiry is a backstop for detection failure: the poison you never find still eventually stops being recalled.
**Quarantine. ** Candidates that are suspicious but not clearly malicious, flagged by the gate, derived from untrusted sources, asserting permissions, go to a quarantine store: written but not recallable until reviewed and released. Quarantine separates "we noticed this" from "we trust this, " giving you a human or automated review step before a borderline item can influence future sessions. It is the memory analogue of the human-approval gate for tool calls (Ch. 10): hold the high-risk write until something deterministic clears it.
Detecting and cleaning a poisoned store
Prevention is imperfect, so you need detection and a cleanup path, because the question is not whether a poison ever gets in but whether you can find and remove it before, or after, it causes harm.
**Detection. ** Scan durable stores for instruction-shaped content on a schedule, not just at write time, because gates improve over time and a poison that passed an old gate should be catchable by a new scan. Watch for the behavioral signature: answers that consistently steer toward a particular harmful action, a memory that asserts unusual permissions, a summary that contains assistant-directed text. Monitor the rate of gate rejections and quarantines as an attack indicator (Ch. 16), a spike in instruction-shaped memory candidates from one source is an attack in progress.
**Cleaning. ** This is where provenance pays off. When a poisoned item is found, you do not just delete that item; you use its source_ref to find every item derived from the same poisoned source, every memory, summary, and index entry that traces back to the malicious input, and remove them as a set. Then you regenerate the derived artifacts: re-summarize the affected conversations without the poisoned source, reindex the affected corpus, recompute the affected profile. Deleting the visible poison while leaving its derivatives (a summary that absorbed it, an index entry that copied it) is a partial cleanup that leaves the attack partly live.
def clean_poisoned_source(source_ref):
"""Remove a poisoned source and ALL its derivatives, then regenerate."""
affected = lineage_log.find_all_derived_from(source_ref) # memories, summaries, index entries
for item in affected:
store_for(item).revoke(item.id, reason=f"poisoned_source:{source_ref}") # soft-delete, audited
for summary in affected.summaries:
regenerate_summary(summary.conversation_id, excluding=source_ref) # recompute clean
for corpus in affected.corpora:
reindex(corpus, excluding=source_ref) # remove from index
audit_log.record("poison_cleanup", source_ref=source_ref, removed=len(affected))This is why provenance and a lineage log (Ch. 8) are non-negotiable: without them, cleanup is impossible to do completely, and an incomplete cleanup is an incident that keeps recurring. The OWASP poisoning guidance, the OWASP Prompt Injection Prevention Cheat Sheet, and the discipline of NIST's AI RMF "Manage" function all point at exactly this: you must be able to trace, contain, and remediate poisoned data, and that capability is built before the incident, not during it.
Chapter summary
Memory poisoning makes injection persistent, which is what makes it worse than every transient attack: by a hard asymmetry, a read error pollutes one answer (transient, possibly self-correcting) while a poisoned write is re-injected into every relevant future session, possibly other users', until found and removed, and a plausible one may never be found. So be liberal about reads and conservative about writes, with every durable store defaulting to do not persist. The persistent stores are distinct poisoning surfaces: user-profile memory (extractor stores the attacker's "fact"), summaries (instruction survives compression and is trusted as the system's own notes), the RAG index (highest fan-out, cross-user), caches (poison served bypassing a fixed pipeline), and agent skill libraries (the poison becomes executable behavior the agent trusts as its own). The adversarial memory write gate adds the crucial Gate 0, reject memories that are instructions shaped like facts (addressing the assistant, commanding, mentioning tools) and quarantine claims that grant permission or consent (verify those out-of-band, never from extracted text), atop a higher-than-read trust bar to persist, mandatory provenance, and a scope-escalation check that stops a one-user fact becoming global. Provenance makes poison traceable and correctable, expiry ensures undetected poison decays, and quarantine holds suspicious writes unrecallable pending review (the memory analogue of the tool-call human gate). Because prevention is imperfect, scan durable stores on a schedule, watch for behavioral signatures and rejection-rate spikes, and, when poison is found, use its source_ref to remove all derivatives (memories, summaries, index entries) and regenerate the clean versions, since deleting the visible poison while leaving its absorbed copies is a partial cleanup that leaves the attack live. Provenance and a lineage log are therefore non-negotiable, built before the incident, not during it.