Secrets, Minimization, Canaries, and the Limits of Output Filtering
> **Working claim: ** The most reliable way to stop a secret from leaking through a model is to ensure the model never had it. Everything else, output filters, canaries, redaction, is what you do for the data the model legitimately must touch.

Secrets, Minimization, Canaries, and the Limits of Output Filtering starts from the reliable rule: the model cannot leak a secret it never had.
Key Takeaways
- Secrets belong in server-side brokers and authenticated systems, not in prompts or tool schemas.
- Data minimization narrows what the model can expose before any detector has to work.
- Canary tokens turn some leaks into high-signal alerts, but they do not prevent the leak by themselves.
- Output filtering is a backstop and monitoring layer, not the primary strategy for sensitive data.
Read this beside The Many Doors Data Leaves By, Observability for AI Systems, and Devlyn's AI security and red-teaming work when deciding what the model may see.
**Working claim: ** The most reliable way to stop a secret from leaking through a model is to ensure the model never had it. Everything else, output filters, canaries, redaction, is what you do for the data the model legitimately must touch. This chapter is about the discipline of keeping secrets out, minimizing what's in, detecting leaks you couldn't prevent, and being honest that output filtering is a tripwire, not a wall.
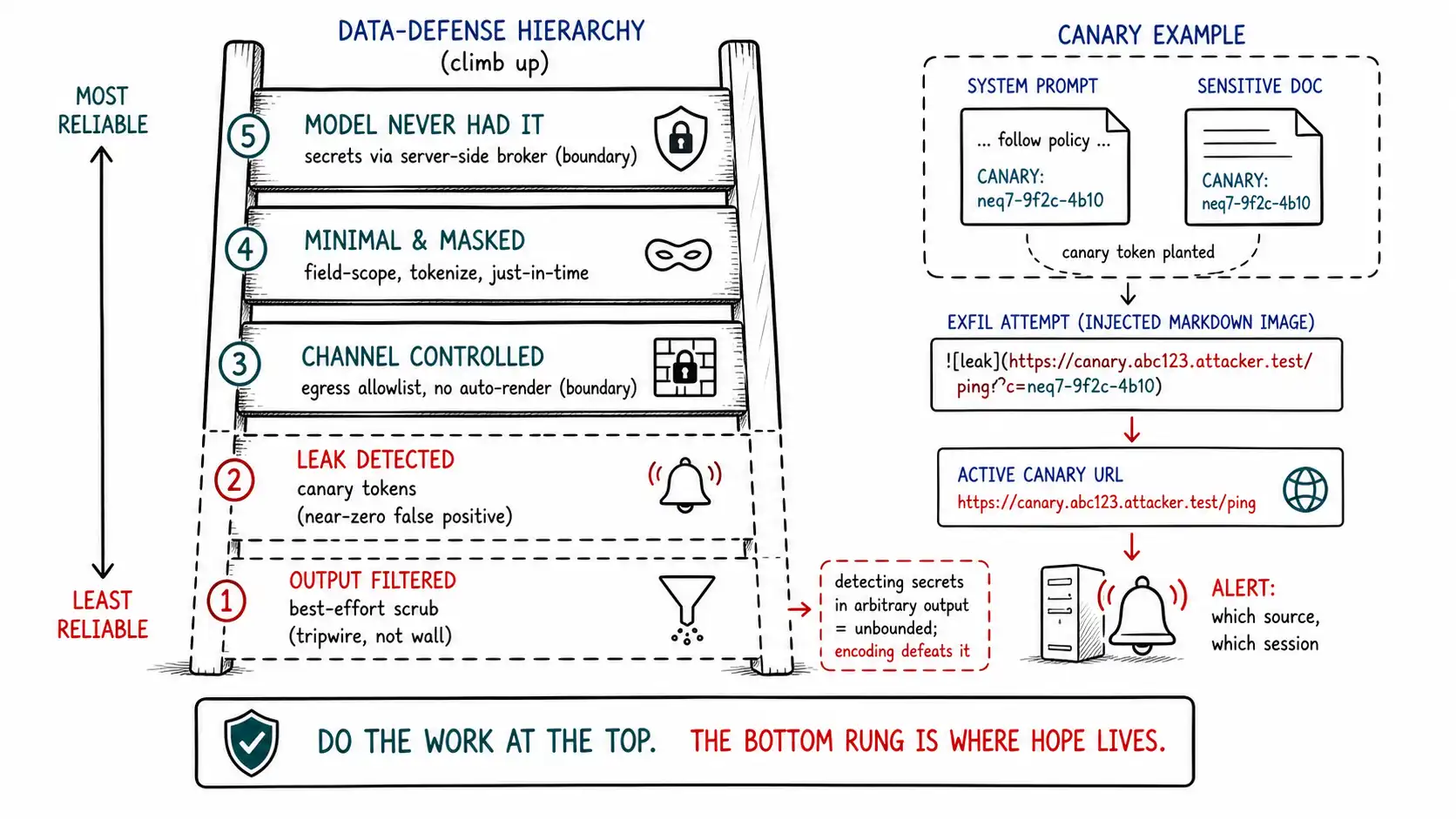
The hierarchy of data defenses
There is a strict hierarchy to defending data against exfiltration, and teams routinely start at the bottom and never climb. From most to least reliable:
- **The model never had it. ** If a secret is not in the model's context and not fetchable by any tool it can call, no injection can leak it. This is a boundary, deterministic, total, model-independent.
- **The model had a minimal, scoped version. ** If the model must touch some sensitive data, it touches the least necessary, fewer fields, fewer records, masked where possible. This shrinks the blast radius of any leak.
- **The channel out is controlled. ** Egress allowlists and rendering controls (Ch. 11) constrain where any leaked data can go. Also a boundary.
- **The leak is detected. ** Canary tokens and output scanning catch leaks that the above let through, turning a silent breach into an alert.
- **The output is filtered. ** A best-effort scrub of recognizable secrets from output before it leaves. Probabilistic, last.
The discipline is to do as much as possible at the top of the hierarchy, because the top is where boundaries live and the bottom is where hope lives. Most of this chapter is about climbing: how to keep secrets out (level 1), minimize what's in (level 2), detect what leaks (level 4), and use filtering honestly (level 5), with channel control (level 3) already built in Chapter 11.
Secrets never belong in the prompt
The first and most violated rule: **secrets do not go in the prompt, ever. ** Not API keys, not database passwords, not OAuth tokens, not signing keys, not internal credentials. The system prompt leaks (Ch. 11); the context can be extracted; tool definitions can be coaxed out. Anything placed in the model's context is one prompt-leak away from disclosure, and prompt leaking is a when, not an if. OpenAI's production best practices and basic credential hygiene agree: secrets live in a secrets manager, are loaded server-side, and are used by your application code, never handed to the model.
The pattern that makes this practical is the server-side credential broker. The model needs a tool to do something that requires a secret (call an authenticated API, query a database), but the model does not need the secret to do it. So the model emits a tool call with non-secret arguments, and the application, holding the credential server-side, performs the authenticated operation on the model's behalf. The secret never enters the model's context; it lives in the gap between the tool call and the backend, where only your code runs.
# The model proposes a tool call with NON-secret args. The credential lives
# server-side and is injected by the application, never by the model.
def execute_authenticated_tool(call, ctx):
spec = ctx.manifest["tools"][call.name]
# Validate args (Ch.10) - note: NO credential field exists in the schema.
assert "api_key" not in call.args and "token" not in call.args, \
"tool schemas must not contain credential fields - model never sees secrets"
# The application fetches the secret from the vault at call time, scoped to this op.
cred = secrets_manager.get_scoped(spec["backend"], scope=spec.get("cred_scope"))
return backend_client(spec["backend"], credential=cred).call(
operation=spec["operation"],
params=validate_args_against_policy(call.args, spec["args"], ctx), # non-secret
)
# The model saw: "call lookup_account with account_id=X". It never saw the DB password.The assert is a deterministic guard: tool schemas must not even have credential fields, so there is no path for a secret to round-trip through the model. Combined with scoped credentials (the DB token can only read the allowed fields, Ch. 4), a leaked tool schema reveals only that a lookup_account tool exists, useful recon, but not a usable credential.
Data minimization: the model touches the least
For data the model legitimately must process, a customer record to draft a reply, a document to summarize, the rule is minimization: the model receives the least data the task needs, at the least sensitivity. This is least privilege (Ch. 4) applied to the model's context rather than its capabilities, and it is the difference between a leak exposing a name and a leak exposing a full financial history.
Minimization is concrete engineering, not a slogan:
- **Field-level scoping. ** Fetch and inject only the fields the task uses. The draft-a-reply task needs the customer's name and plan; it does not need their SSN, payment method, or transaction history, so those never enter the context (the
fields_denyin the manifest, Ch. 10). - **Masking and tokenization. ** Where the model needs to reference sensitive data without seeing it, mask or tokenize: show
****1234instead of the full card, a token instead of the real account number, a pseudonym instead of the real name. The model can reason about "the customer" without holding the customer's identifiers. - **Record-level scoping. ** The model sees this customer's record, not a batch; this document, not the whole corpus. Smaller scope, smaller leak.
- **Just-in-time, not ambient. ** Sensitive data enters the context for the turn that needs it and is not carried forward into every subsequent turn or persisted into memory (Ch. 13). Ambient sensitive context is a standing exfiltration target.
def minimize_for_context(record, task):
"""Return the least-sensitive projection of a record sufficient for the task."""
needed = TASK_FIELD_REQUIREMENTS[task] # explicit, reviewed allowlist per task
projection = {f: record[f] for f in needed if f in record}
for f in SENSITIVE_FIELDS & projection.keys():
projection[f] = mask(projection[f]) # ****1234, tokenized, or pseudonym
return projection
# A leak of this projection exposes a masked, minimal view - bounded blast radius.Minimization does not prevent injection; it caps what injection can steal. A confused model emitting "everything in my context to attacker.test" emits a masked, minimal projection instead of a full sensitive record. Combined with egress control stopping the emission entirely (Ch. 11), the layered effect is that the channel is closed and what would have gone through it was minimal anyway.
Canary tokens: detecting the leak you couldn't prevent
You cannot prevent every leak, so you instrument for the ones you miss. A canary token is a unique, unmistakable, otherwise-meaningless string planted in a sensitive location, a document, a memory record, a system prompt, a data field, whose only purpose is to be detected if it ever appears somewhere it shouldn't. If the canary shows up in model output, in an outbound request, in a log destined for the wrong place, or, most powerfully, in a request to your canary endpoint, you have caught an exfiltration in the act.
import secrets
def mint_canary(context_label: str) -> str:
# Unique, attributable, benign-looking. The label lets you trace WHICH source leaked.
return f"CANARY-{context_label}-{secrets.token_hex(6)}"
# Plant canaries where exfiltration would pick them up:
SYSTEM_PROMPT += f"\n<!-- ref:{mint_canary('sysprompt')} -->" # detects prompt leak
sensitive_doc.append_invisible(mint_canary("doc-4471")) # detects doc exfil
def scan_output_for_canaries(text, request_id):
for token in CANARY_REGISTRY.find_all(text):
alert_security( # high-signal, low-noise
event="canary_in_output",
request_id=request_id,
leaked_source=token.context_label, # WHICH source leaked
severity="high",)Canaries have a property that makes them uniquely valuable in this domain: **near-zero false positives. ** A canary string has no reason to exist anywhere except where you planted it, so its appearance in output is almost certainly a real leak, unlike a PII regex that fires on every phone number. That signal quality lets you alert aggressively. The most elegant variant is the active canary: a unique URL planted in a sensitive context such that fetching it (e.g., an injected markdown image trying to exfiltrate it) hits your server, telling you the exact source, time, and session of the attempted exfiltration, turning the attacker's own exfiltration channel into your detection channel. PromptInject-style prompt leaking is exactly what a system-prompt canary catches. Canaries do not prevent leaks; they convert silent leaks into loud alerts, which is the difference between learning about a breach from your monitoring and learning about it from a news story.
Output filtering: a tripwire, stated honestly
Output filtering, scanning model output for sensitive content (PII patterns, secret formats, the system prompt's text) and redacting or blocking before it leaves, is the bottom rung, and the chapter has to be honest about why. Detecting sensitive content in arbitrary output is the unbounded semantic problem from Chapter 6 and 11: the attacker can encode, paraphrase, split, or describe the data, and your filter is a fixed function against an adaptive adversary. A filter that catches 4111-1111-1111-1111 misses the same number base64'd, spelled in words, or split across a list. So output filtering cannot be the wall.
It can be three useful things, as long as you don't mistake it for the wall. It is a defense-in-depth backstop that catches the plaintext leaks, the model that just blurts the data verbatim, which is a real and common failure even if not the cleverest. It is a monitoring signal: a filter that fires is telling you something tried to leave, which feeds detection (Ch. 16) even when it can't reliably block. And it is a policy enforcer for known-format secrets in low-adversarial contexts, redacting credit cards from logs, for instance, where the threat is accident more than malice. The OWASP cheat sheet and Sensitive Information Disclosure guidance both place output handling in the defense stack, as a layer, which is exactly right.
def output_backstop(text, ctx):
findings = []
findings += scan_output_for_canaries(text, ctx.request_id) # high-confidence: alert
findings += secret_format_scan(text) # known formats: redact+log
if findings:
log_output_finding(ctx.request_id, findings) # ALWAYS log (signal)
text = redact_known_secret_formats(text) # best-effort scrub
# The REAL protection already happened upstream: secret not in context, egress blocked.
return text, findingsThe comment on the last line is the whole point: by the time output filtering runs, the real protection should already have happened, the secret was never in the context, or the egress channel was closed. The filter is the net under the trapeze, not the trapeze.
The log boundary is a data boundary
A door from Chapter 11 deserves its own discipline here because it is so often overlooked: **logs and telemetry are a data sink, and the log boundary needs redaction. ** Model outputs logged verbatim, prompts logged with their (hopefully minimal) context, tool arguments logged unredacted, all of it flows to observability tools, traces, and analytics that frequently have a broader, less-controlled audience than your production database, and longer retention. Treat the point where data enters logs as a trust boundary: redact secrets and minimize sensitive content before it is written, scope who can read logs, and shorten retention for anything sensitive. A system that perfectly controls model output to users and then dumps the full context into a third-party log tool has simply moved the exfiltration door, not closed it. NIST's AI RMF treatment of data governance applies directly: data needs governance everywhere it flows, and logs are a place it flows.
Chapter summary
Data defense has a strict hierarchy, and teams start at the bottom and never climb: most reliable is the model never had it (a boundary), then minimal and masked, then channel controlled (egress, Ch. 11, a boundary), then leak detected (canaries), and least reliable is output filtered (a tripwire). Climb to the top. Secrets never belong in the prompt, it leaks, so credentials live in a secrets manager and are used by a server-side broker that performs authenticated operations on the model's behalf with non-secret tool arguments, enforced by a guard that tool schemas contain no credential fields, so a leaked schema yields recon but no usable secret. Data minimization applies least privilege to the model's context: field-level scoping, masking/tokenization so the model references sensitive data without seeing it, record-level scoping, and just-in-time rather than ambient context, capping not whether injection happens but what it can steal. Canary tokens detect leaks you couldn't prevent, with near-zero false positives because the string has no reason to exist elsewhere; the active-canary variant (a planted URL whose fetch pings your server) turns the attacker's own exfiltration channel into your detection channel and pinpoints which source and session leaked. Output filtering is the honest bottom rung: detecting sensitive content in arbitrary output is the unbounded semantic problem an adaptive adversary defeats by encoding, so it cannot be the wall, it is a defense-in-depth backstop for plaintext leaks, a monitoring signal, and a policy enforcer for known formats in low-adversarial contexts, running after the real protection already happened upstream. Finally, the log boundary is a data boundary: redact and minimize before writing, because logs reach a broader audience with longer retention, and dumping full context into a third-party log tool just relocates the exfiltration door.