The Supply Chain of Untrusted Text
This chapter turns the supply chain of untrusted text into a concrete operating problem for the ai native security book.

The Supply Chain of Untrusted Text is the production attack surface: every external channel that feeds the model can carry instructions disguised as data.
Key Takeaways
- Indirect injection is worse than a chat-box jailbreak because the attacker may never log in or see the system prompt.
- Webpages, emails, PDFs, tickets, code comments, OCR, tool outputs, and memory all become source channels.
- Durable stores turn one poisoned document into a standing influence across future sessions.
- Trust labels and durable-write gates are the control points that make the rest of the defense possible.
Read this beside the RAG attack-surface chapter, Retrieval That Survives Contact, and Devlyn's AI security and red-teaming work when auditing ingestion paths.
**Working claim: ** Indirect prompt injection is the real production problem because production systems are built to read content from outside, and every channel you proudly added, browse the web, summarize the email, read the PDF, retrieve the document, process the tool output, is an attacker-writable input. The defining and terrifying property is that the attacker needs no account, no session, and no relationship with your system. They just need to author content your system will eventually read.
The feature list is the attack surface
Open the marketing page for any modern AI product and read the feature bullets as a security engineer."Connects to your inbox." "Browses the web for you." "Reads your documents." "Searches your knowledge base." "Integrates with your tools." Each bullet is a sales point and, simultaneously, a sentence that means: *this system will read text authored by someone other than the user, and feed it to a model that treats text as instruction. * The feature list and the attack surface are the same list, a pattern Simon Willison has documented extensively. There is no version of "the assistant reads your email" that is not also "the assistant reads text an attacker emailed your user."
This is the inversion that makes indirect injection feel unfair to teams the first time they see it. In a normal web app, you decide what inputs to accept and you validate them at a known edge. In an LLM application with connectors, you have deliberately built paths for arbitrary external content to flow to the model, because reading external content is the product. You cannot close the paths without deleting the features. So the work is not to stop the text from arriving, it is to ensure that text, no matter how malicious, arrives as data with a known low trust level and a capped blast radius, never as privileged instruction. The whole of Movement IV is that work.
Greshake et al.'s "Not What You've Signed Up For", with its Black Hat USA 2023 whitepaper, demonstrated this against real LLM-integrated applications: content placed where the system would read it, a webpage, a document, could redirect the system's behavior, exfiltrate data, and manipulate the user, all without the attacker ever interacting with the application directly. That paper is the moment prompt injection stopped being a chat-box joke and became an application-security discipline, and it is the intellectual anchor of this chapter.
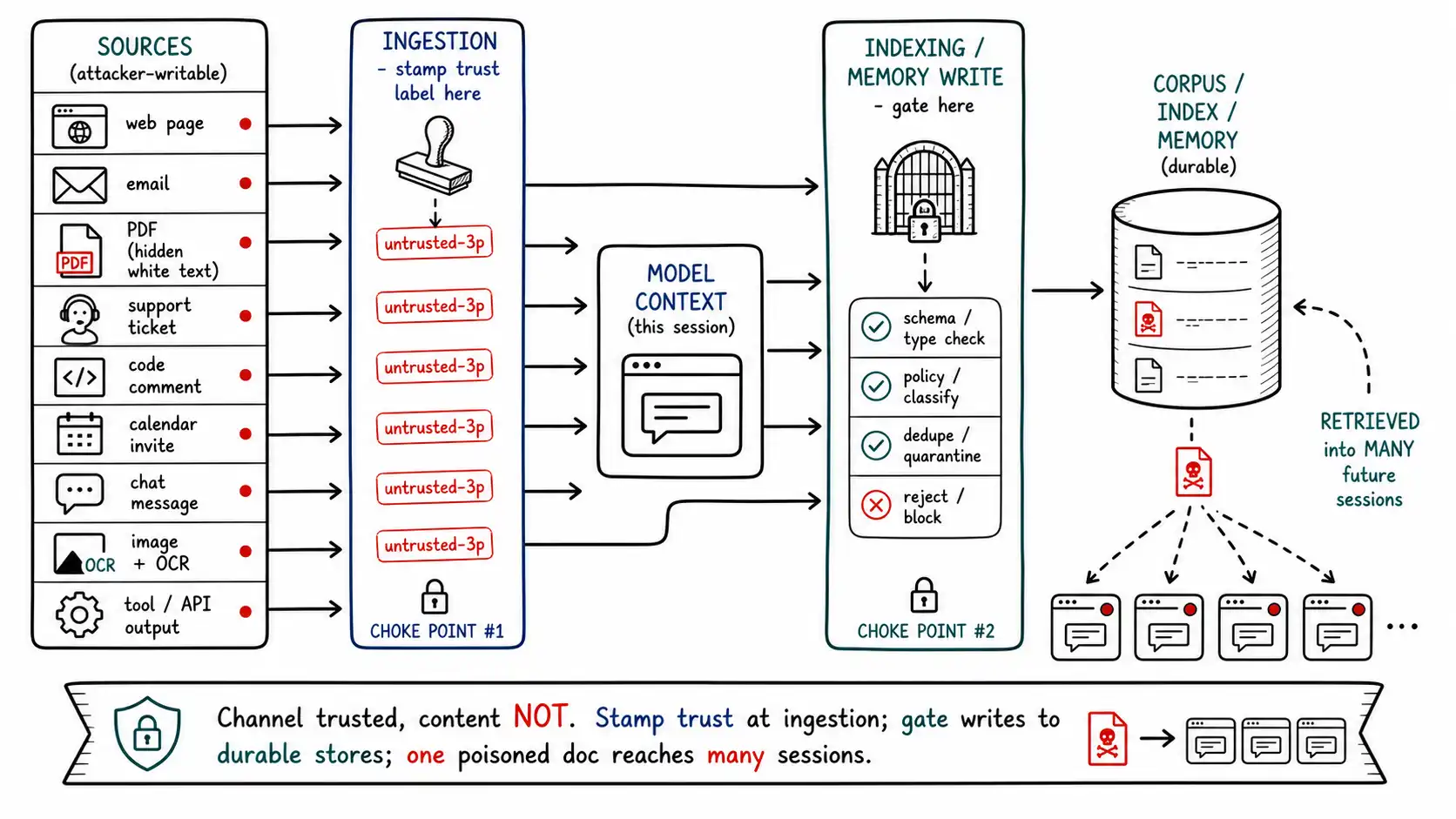
The channels, catalogued
A defender needs the full catalogue, because the failure mode is protecting the channels you thought of and leaving the ones you forgot. For each channel: who can write to it, and why it is easy to forget.
**Webpages. ** Any page a browse/fetch tool retrieves. The attacker controls the entire content of a page they host, and can also inject into pages they merely contribute to, comments, reviews, profile fields, wiki edits, forum posts. Easy to forget because "the web" feels like neutral information rather than attacker-authored content, but a browsing agent reads exactly what the page's author wrote.
**Emails. ** Any message the assistant reads or summarizes. The attacker is anyone who can send your user an email, i.e., anyone, since email accepts mail from strangers by design. Easy to forget because the user is trusted and the email arrives "to the user, " obscuring that the email body is third-party content.
**PDFs and documents. ** Uploaded or retrieved files. The attacker authored the document, and PDFs are especially dangerous because they can carry text invisible to a human reader (white-on-white, tiny fonts, off-page, in metadata, in layers) that the extractor pulls out in full. Easy to forget because a document "looks like" trustworthy reference material.
**Support tickets, forms, and chat messages. ** Anything a customer or external party submits through your intake channels. The attacker is your "customer, " possibly a fake one created to deliver the payload. Easy to forget because intake is supposed to be read and acted on, that is its purpose.
**Code comments and repository content. ** For coding assistants and code-review bots. The attacker is anyone who can land content in a repo the assistant reads, a dependency, a contributed file, a pull request, a comment, a commit message, an issue. Easy to forget because code feels like a controlled artifact, but assistants read comments, docstrings, and third-party dependencies as text.
**Calendar invites and meeting content. ** Invites, descriptions, attendee notes. The attacker is anyone who can send your user an invite. Easy to forget because the calendar feels internal.
**Slack/Teams and collaboration messages. ** Channel content, DMs, shared files, integrations. The attacker is anyone in a shared channel, anyone who can DM, or any connected app posting messages. Easy to forget because the workspace feels like a trusted boundary, but external guests, integrations, and compromised accounts all post text.
**Retrieved RAG chunks. ** The output of your own retrieval over your own corpus, which is only as trusted as the least trusted document in that corpus (Ch. 8). Easy to forget because it is "internal, " but corpora ingest public docs, customer uploads, and scraped content.
**OCR and image-derived text. ** Text extracted from images and screenshots. The attacker hides instructions in an image that a human glances past but OCR transcribes. Easy to forget because the image is the input and the text is a derived layer the security review never looked at.
**Tool outputs. ** The response from any tool the agent calls, an API result, a search result, a database free-text field, another model's output. The attacker is whoever controls the data that tool returns. Easy to forget because "it's a tool we built, " but the tool returns content authored elsewhere.
The pattern across all ten: the channel is trusted, the content flowing through it is not, and the gap between those two is where teams get hurt."Our email connector is secure" is true and irrelevant; the connector is fine, the email bodies are the attack.
The supply chain, drawn
These channels are not independent puddles; they form a supply chain where untrusted text can flow from a public source, through ingestion, into durable storage, and be retrieved into many future sessions. Seeing it as a flow, with the choke points marked, is how you decide where to put trust labels and filters.
The figure shows the two properties that make indirect injection worse than direct. First, the fan-in: ten kinds of source converge into the model's context, and you must defend all of them, not the one you remembered. Second, the fan-out: text that reaches a durable store (corpus, index, memory) is retrieved into many future sessions, so one poisoned document is not one bad answer, it is a standing influence on every query it matches, possibly across users (Ch. 8, 13). The choke points where you stamp trust labels and gate durable writes are the control points; everything downstream depends on having labeled correctly at ingestion.
No account, no session, no relationship
The property worth dwelling on, because it reorders your threat model, is that the indirect attacker needs no relationship with your system at all. Consider the threat models you are used to: a malicious user (has an account), an insider (has access), a compromised credential (had access). All assume the attacker touched your system. Indirect injection breaks that assumption. The attacker who poisons a webpage your agent will browse, or sends an email your assistant will summarize, or uploads a document to a public repository your RAG pipeline ingests, never authenticated, never logged in, never appeared in your access logs as anything but "content."
This has three consequences that should reshape your defenses.
First, **your authentication and authorization on the user side do not touch this attacker. ** Rate-limiting accounts, MFA, user reputation, none of it applies, because the attacker is not a user. The only place you can act on them is at the content layer: trust-labeling sources, sanitizing channels, capping what content can influence.
Second, **you cannot enumerate the attackers. ** In a normal threat model you can reason about "our users." Here the attacker population is "anyone who can author content that will eventually reach our model, " which for a web-browsing agent is the entire internet. You defend against a capability (content reaching the model) rather than against identified actors.
Third, **the attack can be planted long before it fires. ** A poisoned webpage sits dormant until an agent browses it. A document with hidden instructions sits in a corpus until a query retrieves it. The attacker and the victim need never be online at the same time, which defeats real-time, session-based detection and demands defenses that travel with the content (trust labels, provenance) rather than living in the session.
Microsoft's defense writeup is built around exactly this reframing: treat all external content as untrusted by default, isolate it, and assume the model may be influenced by it, because there is no upstream identity check that will catch a content-borne attacker.
A trust-labeling discipline for ingestion
The single most important engineering move in this movement is to **stamp a trust label on every piece of external content at the moment of ingestion, and carry that label through the entire pipeline. ** The label is set by the ingestion path (which connector, which source), never by the content (which can lie). This is the implementation of TRUST's "T, text source" and it is the choke point the figure marks.
from dataclasses import dataclass, field
from datetime import datetime, timezone
@dataclass(frozen=True)
class IngestedContent:
text: str
channel: str # "web" | "email" | "pdf" | "ticket" | "repo" | "ocr" | "tool" | ...
source_ref: str # URL, message-id, file hash, ticket id - for forensics
trust: str # set by CHANNEL POLICY, never by content
ingested_at: datetime
flags: list[str] = field(default_factory=list) # detector signals attached here
# Channel -> default trust. Almost everything external defaults to untrusted-3p.
CHANNEL_TRUST = {
"web": "untrusted-3p", "email": "untrusted-3p", "pdf": "untrusted-3p",
"ticket": "untrusted-3p", "repo": "untrusted-3p", "ocr": "untrusted-3p",
"tool": "untrusted-3p", # tool OUTPUT is untrusted even from our own tool
"user_typed": "untrusted-1p", # the user's own request: low trust, but theirs
"system": "trusted", # only the server-fixed system prompt
}
def ingest(text, channel, source_ref, detectors) -> IngestedContent:
trust = CHANNEL_TRUST.get(channel, "untrusted-3p") # unknown channel => most-untrusted
flags = []
text = normalize_for_visibility(text) # close human/model gap (Ch.6)
for d in detectors: # attach signals, don't block here
if (f:= d.scan(text)):
flags.append(f)
return IngestedContent(text, channel, source_ref, trust,
datetime.now(timezone.utc), flags)Three disciplines make this real. The trust default for an unknown channel is the most-untrusted value, so forgetting to classify a new connector fails safe. Tool output is untrusted-3p even when the tool is yours, because the tool returns content authored elsewhere. And detectors attach flags at ingestion rather than blocking, because the blocking decision belongs downstream where it can be combined with capability risk (Ch. 6, 8). The source_ref is your forensic lifeline (Ch. 16): when an incident traces back to a poisoned input, you need to know exactly which URL, message, or file delivered it.
The reframe to carry into the RAG chapter
Indirect injection forces a reframe that the next chapter operationalizes for retrieval specifically: **internal storage does not confer trust. ** A document is not trustworthy because it is in your database; it is trustworthy only if you can trace it to a trusted source and verify it was not poisoned in transit. RAG corpora are the place this reframe bites hardest, because the entire premise of RAG, retrieve relevant text and feed it to the model as evidence, is a machine for moving content from storage into the model's context, and if any of that content is attacker-authored, RAG is a machine for delivering payloads. Chapter 8 treats RAG as the attack surface it is (OWASP LLM01 classifies this as prompt injection in the indirect delivery form). The bridge from this chapter: every chunk in your index arrived through one of the ten channels above, carries (or should carry) a trust label from ingestion, and must be treated as untrusted evidence at retrieval time no matter how cozy it feels to call it "our knowledge base."
Chapter summary
Indirect prompt injection is the production problem because production systems are built to read external content, so the feature list, browse, summarize email, read PDFs, retrieve documents, process tool outputs, is the attack surface; you cannot close the channels without deleting the product, so the work is to make all incoming text arrive as low-trust data with capped blast radius, never as privileged instruction. The channel catalogue spans webpages, emails, PDFs/documents (which can hide human-invisible text), tickets/forms, code comments and repo content, calendar invites, collaboration messages, retrieved RAG chunks, OCR/image-derived text, and tool outputs: and the uniting pattern is that the channel is trusted while the content flowing through it is not. These form a supply chain with a dangerous fan-in (all channels converge on the model, so you must defend the one you forgot) and fan-out (content reaching a durable store is retrieved into many future sessions, so one poisoned document is a standing cross-session influence). The defining property is that the indirect attacker needs no account, session, or relationship: your user-side authn/authz doesn't touch them, you cannot enumerate them, and the attack can be planted long before it fires, so defenses must travel with the content (trust labels, provenance) rather than living in the session. The core engineering move is to stamp a trust label at ingestion based on the channel, never the content, default unknown channels and tool outputs to most-untrusted, normalize for the human/model visibility gap, attach detector flags without blocking, and keep a source_ref for forensics, carrying the label through the whole pipeline into the RAG layer, where "internal storage does not confer trust" becomes the rule of the next chapter.