Ten Systems, Ten Threat Models, Ten Launch Checklists
> **Working claim: ** The frameworks of this book only matter if they survive contact with real systems.

Ten Systems, Ten Threat Models, Ten Launch Checklists is the practical exam for the book: the framework must survive ten real system shapes.
Key Takeaways
- Each system has different assets, untrusted inputs, tools, attack paths, and unacceptable residual risks.
- A browser agent, email assistant, RAG copilot, support agent, and refund agent fail differently because their capabilities differ.
- The launch checklist forces every high-impact capability to name a deterministic gate before release.
- The exercise proves the point of the book: security is per-system architecture, not a universal prompt.
Read this beside Prompt Injection Is Not a Joke, Agents That Actually Work, and Devlyn's AI security and red-teaming work when adapting the checklists.
**Working claim: ** The frameworks of this book only matter if they survive contact with real systems. This chapter applies TRUST, blast radius, the defense matrix, and the boundary stack to ten concrete applications, each with its assets, untrusted inputs, tools, dominant attack paths, required controls, the residual risks that must block launch, and a launch checklist. Read the one you are building; read two others to see how the same skeleton bends to different shapes.
How to read a threat model
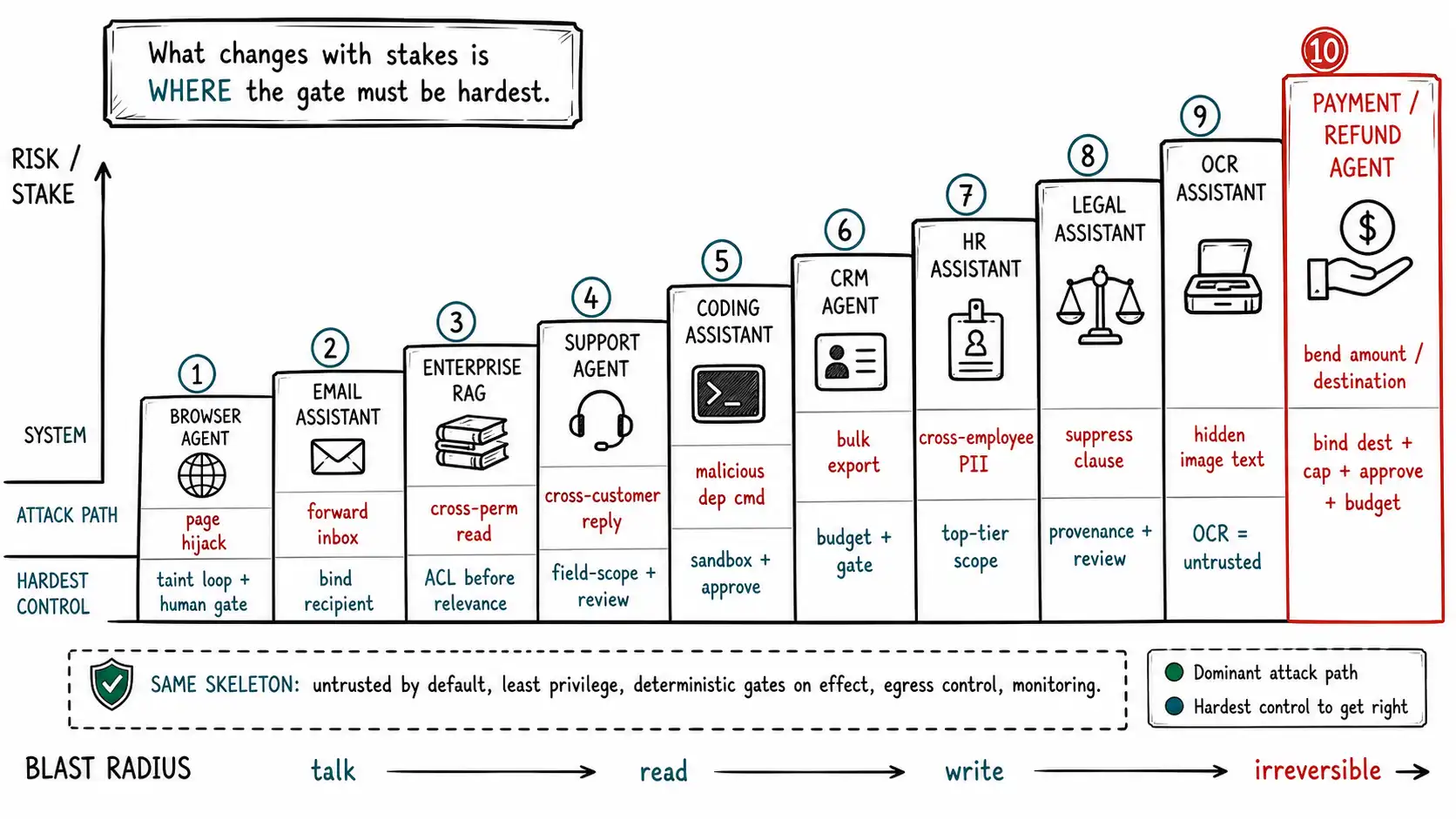
Each system below follows one shape, derived from the threat-model worksheet of Chapter 3: assets (what's worth protecting), untrusted inputs (the supply chain that feeds the model), tools (the capabilities and their blast radius), dominant attack paths (the chains most likely to hurt), required controls (the boundaries that bound them), unacceptable residual risks (the things that, if possible, block launch), and a launch checklist. The systems are ordered roughly by increasing blast radius, from the browser agent that can touch the whole internet to the refund agent that can move money, because watching the controls intensify as the stakes rise is the lesson. Across all ten, the same skeleton holds: untrusted by default, least privilege, deterministic gates on effect, egress control, and monitoring. What changes is where the dangerous capability is and therefore where the gate must be hardest.
1. Browser agent
An agent that autonomously browses the web to accomplish a user's task, research, booking, form-filling.
- **Assets: ** the user's session credentials and authenticated tabs, any data the agent accesses while browsing, the user's identity in services it acts on.
- **Untrusted inputs: ** every webpage it visits, the entire internet is the attacker (Ch. 7). This is the highest-untrusted-input system in the book.
- **Tools: ** navigate, click, fill forms, read page content, and often act on logged-in services. Mixed read and write, with write reaching authenticated sessions.
- **Dominant attack paths: ** indirect injection from a visited page hijacks the agent → it uses its other authenticated tabs/tools against the user (the agent-loop escalation, Ch. 9); exfiltration by navigating to an attacker URL with data in the query string (Ch. 11).
- **Required controls: ** treat every page as untrusted-3p and taint the loop after any browse (Ch. 9); separate read-browsing from any authenticated action with a human gate between them; egress allowlist so the agent cannot navigate to arbitrary exfil destinations; per-task credential scoping so a hijacked agent cannot reach the user's full account set.
- **Unacceptable residual risks (block launch): ** autonomous authenticated actions (purchase, post, send) after browsing untrusted content without human confirmation; ability to reach arbitrary destinations.
- **Launch checklist: ** ☐ every page tainted as untrusted-3p ☐ authenticated actions require human confirm after any browse ☐ egress allowlist enforced ☐ credentials scoped per task ☐ loop iteration + budget caps ☐ red-team corpus includes hostile-page fixtures.
2. Email assistant
Reads, summarizes, drafts, and (sometimes) sends email on the user's behalf.
- **Assets: ** the user's entire inbox (often years of sensitive correspondence), contacts, the ability to send as the user.
- **Untrusted inputs: ** every email body, anyone who can email the user is the attacker (Ch. 7), and the body rides in "to the user" while being third-party content.
- **Tools: ** read mailbox, search, draft, send, forward. Send/forward are high-impact writes that act with the user's identity.
- **Dominant attack paths: ** an email body instructs the assistant to forward the inbox (or specific sensitive threads) to an external address (indirect → exfiltration via send tool, Ch. 11); a body instructs deletion or auto-reply with sensitive data.
- **Required controls: ** email bodies framed as untrusted data, segregated from the user's request (Ch. 2, 6); send/forward recipient bound to application context or human-confirmed, never a model-chosen external address (Ch. 10); egress/recipient allowlist; data minimization on what the assistant loads per task (Ch. 12).
- **Unacceptable residual risks (block launch): ** autonomous send/forward to a model-chosen external recipient; bulk forwarding without human confirmation.
- **Launch checklist: ** ☐ email bodies are untrusted, framed as data ☐ send recipient bound to context or human-confirmed ☐ no autonomous external forward ☐ per-task inbox scoping ☐ canary in a planted sensitive-looking thread ☐ egress allowlist.
3. Enterprise RAG copilot
Answers employee questions over an internal knowledge base spanning many sources and permission levels.
- **Assets: ** confidential internal documents at varying sensitivity and access levels; cross-department and cross-tenant data.
- **Untrusted inputs: ** the corpus itself, which is mixed-trust (Ch. 8), synced wikis, uploaded docs, imported public content, plus the user's query.
- **Tools: ** mostly read (retrieve, look up); the danger is confidentiality, not action.
- **Dominant attack paths: ** RAG poisoning (a malicious doc indexed, retrieved into many users' answers, Ch. 8); cross-permission exposure (retrieval returns documents the asking user shouldn't see); cross-tenant leak in multi-tenant deployments.
- **Required controls: ** retrieval ACL filtering by the user's permissions before relevance (Ch. 8), the load-bearing boundary here; ingestion policy with visibility scoping so uploaded/public content can't reach unauthorized users; per-chunk provenance and instruction-scanning at ingestion.
- **Unacceptable residual risks (block launch): ** any path where a user retrieves a document they lack permission for; cross-tenant retrieval.
- **Launch checklist: ** ☐ ACL-first retrieval (permission before relevance) ☐ tenant isolation tested with a cross-tenant fixture ☐ ingestion visibility scoping ☐ instruction-scan + quarantine on untrusted sources ☐ per-chunk provenance ☐ scheduled index poison scan.
4. Customer support agent
Reads customer tickets, retrieves help content, looks up accounts, drafts replies, the Chapter 1 system.
- **Assets: ** customer account data, the ability to communicate as the company, internal KB.
- **Untrusted inputs: ** ticket bodies (the attacker can be a fake "customer"), retrieved KB chunks, account free-text fields.
- **Tools: ** read account (scoped), search KB, draft reply, optionally send.
- **Dominant attack paths: ** the Chapter 1 chain, ticket injection → goal hijack → include other customers' data in reply → exfiltration; and memory poisoning (persist a false consent "fact").
- **Required controls: ** field-scoped account reads denying secrets (Ch. 10); reply send human-reviewed showing the resolved draft (Ch. 10); adversarial memory write gate rejecting instruction-shaped/consent memories (Ch. 13); ticket framed as untrusted data.
- **Unacceptable residual risks (block launch): ** cross-customer data in a reply; autonomous send; persistent memory from a ticket instruction.
- **Launch checklist: ** ☐ account reads field-scoped, secrets denied ☐ send human-reviewed with resolved draft shown ☐ memory write gate rejects instruction/consent claims ☐ ticket framed as untrusted ☐ canary in a sensitive account field ☐ tool-call audit on.
5. Coding assistant
Reads a repository, dependencies, issues, and comments; suggests or applies code, and may run commands.
- **Assets: ** source code (confidentiality and integrity), CI/CD credentials, the developer's environment, production if the assistant can deploy.
- **Untrusted inputs: ** third-party dependencies, contributed files, PRs, issues, code comments, commit messages (Ch. 7), code feels trusted but is heavily attacker-influenceable.
- **Tools: ** read files, search, edit, run shell/tests, commit, sometimes deploy. Shell/deploy are critical-impact writes.
- **Dominant attack paths: ** an injected instruction in a comment or dependency README directs the assistant to exfiltrate secrets, insert a backdoor, or run a malicious command (indirect → tool/code execution); poisoned "skill" or generated tool (Ch. 13).
- **Required controls: ** code/comments framed as untrusted data; shell/deploy behind human approval and least-privilege sandboxed credentials (no prod access from a coding session); egress allowlist on the sandbox (Ch. 11); never auto-run commands derived from repo content without confirmation.
- **Unacceptable residual risks (block launch): ** autonomous shell/deploy from repo-derived instructions; sandbox with prod credentials or open egress.
- **Launch checklist: ** ☐ repo content treated as untrusted ☐ shell/deploy human-approved ☐ sandbox least-privilege, no prod creds ☐ sandbox egress allowlisted ☐ no auto-run from comments/deps ☐ secret scan on assistant output.
6. CRM / sales agent
Updates records, logs activities, sends outreach, reads lead data from many sources.
- **Assets: ** customer/prospect PII, pipeline data integrity, the ability to send outreach as the company.
- **Untrusted inputs: ** lead data imported from web forms, enrichment vendors, scraped sources; inbound emails; free-text notes (Ch. 7).
- **Tools: ** read/update records (write to integrity-critical data), send outreach, run reports.
- **Dominant attack paths: ** an injected lead note manipulates the agent into bulk-updating or deleting records (integrity attack), or into exporting/sending the contact database (exfiltration); cross-record scope escalation.
- **Required controls: ** record updates validated and scoped (no bulk operations from model proposal without approval); export/send gated and egress-controlled; lead free-text framed as untrusted; cumulative budget on records-touched-per-session (Ch. 10).
- **Unacceptable residual risks (block launch): ** bulk record modification/deletion from injected content; autonomous database export.
- **Launch checklist: ** ☐ updates scoped + validated, bulk ops human-approved ☐ export gated + egress-controlled ☐ lead notes treated as untrusted ☐ per-session records-touched budget ☐ tool-call audit ☐ reversibility (soft-delete) on record changes.
7. HR assistant
Answers HR questions, reads employee records and policies, may process requests.
- **Assets: ** highly sensitive employee PII (compensation, performance, health, protected-class data), legal compliance posture.
- **Untrusted inputs: ** employee-submitted documents, tickets, uploaded files; policy docs of mixed provenance.
- **Tools: ** read employee records (scoped), retrieve policy, draft responses, sometimes initiate workflows.
- **Dominant attack paths: ** cross-employee data exposure (one employee's query surfaces another's compensation); injection in an uploaded document exfiltrating sensitive records; the special-category-data problem where some data must never be persisted to memory (Ch. 13).
- **Required controls: ** strict per-employee data scoping with the highest sensitivity tier; special-category data prohibited from memory and minimized in context (Ch. 12); uploaded docs untrusted; human gate on any workflow with employment consequences.
- **Unacceptable residual risks (block launch): ** any cross-employee exposure of sensitive HR data; persistence of special-category data; autonomous employment-affecting actions.
- **Launch checklist: ** ☐ per-employee scoping at highest tier ☐ special-category data never persisted, minimized in context ☐ uploads untrusted ☐ employment-affecting workflows human-gated ☐ canary in a sensitive record ☐ tenant/role isolation tested.
8. Legal document assistant
Reviews contracts and legal documents, extracts terms, answers questions, drafts language.
- **Assets: ** privileged and confidential legal documents, matter confidentiality, accuracy that has legal consequence.
- **Untrusted inputs: ** the documents themselves, uploaded by clients or opposing parties, prime carriers of hidden text (Ch. 7), and retrieved precedent of mixed provenance.
- **Tools: ** read documents, retrieve precedent, draft clauses; mostly read, with the integrity risk being subtly wrong extraction.
- **Dominant attack paths: ** hidden instructions in a submitted document manipulate the analysis (e.g., suppress an adverse clause, alter an extracted term), a correctness-as-attack path unique to high-stakes analysis; cross-matter confidentiality breach.
- **Required controls: ** documents framed as untrusted with concealment stripped (hidden/white text, metadata, Ch. 6); per-chunk provenance so every extracted term is attributable to a source span; strict matter-level isolation; human review of consequential extractions.
- **Unacceptable residual risks (block launch): ** cross-matter document exposure; silent suppression/alteration of terms attributable to hidden instructions.
- **Launch checklist: ** ☐ documents untrusted, concealment stripped ☐ extractions attributable to source spans ☐ matter-level isolation tested ☐ consequential outputs human-reviewed ☐ hidden-text fixtures in corpus ☐ provenance on every retrieved chunk.
9. Multimodal document assistant with OCR
Processes images and scanned documents, extracting text via OCR and reasoning over it.
- **Assets: ** the content of processed documents, plus everything downstream the extracted text can reach.
- **Untrusted inputs: ** images, whose OCR-derived text is the forgotten channel (Ch. 7), instructions hidden in an image that a human glances past but OCR transcribes in full, including text in unusual placement, low contrast, or fine print.
- **Tools: ** OCR/extract, then whatever the document workflow allows (often the same as a RAG copilot or document assistant).
- **Dominant attack paths: ** an instruction embedded in the image survives OCR and injects the model (indirect via OCR), dangerous because the security review looked at "the image" and never at "the text OCR will produce"; the human-visible vs model-visible gap is extreme here.
- **Required controls: ** OCR output stamped untrusted-3p like any other channel (Ch. 7); the gap between what a human sees in the image and what OCR extracts explicitly surfaced (show reviewers the extracted text, not just the image); same downstream boundaries as the relevant document workflow.
- **Unacceptable residual risks (block launch): ** OCR text treated as trusted; any downstream effect that fires on OCR-extracted instructions without the document workflow's gates.
- **Launch checklist: ** ☐ OCR output stamped untrusted-3p ☐ extracted text shown to human reviewers (close the visibility gap) ☐ downstream gates apply to OCR text ☐ OCR-hidden-instruction fixtures in corpus ☐ image metadata/text-layer concealment scanned.
10. Agent with payment / refund capability
The highest-blast-radius system: an agent that can move money.
- **Assets: ** funds (directly), financial integrity, fraud exposure, the only system here where a successful attack is immediately, irreversibly a financial loss.
- **Untrusted inputs: ** customer messages, tickets, account notes, any content that reaches the refund-decision context.
- **Tools: ** issue refund, process payment, adjust balance, all critical, mostly irreversible writes.
- **Dominant attack paths: ** injection bends the refund amount and destination (the argument-is-the-attack, Ch. 9) → money to the attacker; volume attacks (many small refunds below a threshold) exploiting cumulative gaps (Ch. 9, 10).
- **Required controls: ** the strongest in the book, amount hard-capped in policy, destination bound to the account on file (never model-chosen, Ch. 10); human approval over a low threshold; cumulative daily/session budget; full audit; reversibility where the rails allow it.
- **Unacceptable residual risks (block launch): ** any refund to a model-chosen destination; any amount above the cap without human approval; absence of a cumulative budget.
- **Launch checklist: ** ☐ destination bound to account on file (not model output) ☐ amount hard-capped in policy ☐ human approval above a low threshold ☐ cumulative daily/session budget ☐ full tool-call audit (proposed vs resolved) ☐ refund-volume anomaly monitoring ☐ refund fixtures in red-team corpus.
The pattern across all ten
Lay the ten systems side by side and the book's argument resolves into a single observation: **the controls are the same; only their intensity and placement change with blast radius. ** Every system treats inputs as untrusted by default, scopes data and tools to least privilege, gates effects deterministically outside the model, allowlists egress, and monitors. The browser agent's hardest control is the loop-taint-plus-human-gate because its untrusted-input surface is the whole internet. The RAG copilot's is the ACL-before-relevance because its risk is confidentiality across permission levels. The payment agent's is destination-binding-plus-cap-plus-approval because its blast radius is irreversible money movement. None of them relies on "the model refuses injection, " because, as the whole book has argued, that is not a control (a lesson reinforced by Greshake et al.). Each relies on the deterministic boundaries that hold when the model is fooled, placed and hardened in proportion to what the system can do. That proportionality is the design discipline: find your highest-blast-radius capability, put the hardest deterministic gate there, and work outward. A team that can fill in the seven-part worksheet for its own system, with a populated "required controls" and a hard "unacceptable residual risks" list, has done the work this book exists to demand, and has stopped asking whether the model can be tricked, because it has made the answer not matter.
Chapter summary
The book's frameworks survive contact with ten real systems, each modeled as assets, untrusted inputs, tools, dominant attack paths, required controls, unacceptable residual risks, and a launch checklist, ordered by rising blast radius. The browser agent (whole internet as attacker) hardens the loop-taint-plus-human-gate on authenticated actions after browsing; the email assistant binds the send recipient and forbids autonomous external forward; the enterprise RAG copilot lives or dies on ACL-before-relevance and tenant isolation; the support agent (Chapter 1's system) field-scopes account reads, human-reviews sends with the resolved draft, and runs an adversarial memory gate; the coding assistant treats repo/dependency content as untrusted and puts shell/deploy behind approval in a least-privilege egress-allowlisted sandbox; the CRM agent gates bulk operations and exports with per-session budgets and reversibility; the HR assistant enforces top-tier per-employee scoping and never persists special-category data; the legal assistant strips concealment, makes extractions attributable to source spans, and isolates matters against a correctness-as-attack path; the OCR assistant stamps OCR output untrusted and surfaces the extreme human-visible-vs-model-visible gap to reviewers; and the payment/refund agent, highest blast radius, binds the destination to the account on file, hard-caps the amount in policy, requires approval over a low threshold, and enforces a cumulative budget. Laid side by side, the controls are the same across all ten, untrusted by default, least privilege, deterministic gates on effect, egress control, monitoring, and only their intensity and placement change with blast radius, so the design discipline is to find your highest-blast-radius capability, put the hardest deterministic gate there, and work outward. None relies on the model refusing injection, because that is not a control; each relies on boundaries that hold when the model is fooled, which is how a team stops asking whether the model can be tricked and instead makes the answer not matter. The full reference set underpinning this chapter: OWASP LLM Top 10, OWASP Prompt Injection Prevention Cheat Sheet, Microsoft's defense writeup, and NIST's AI Risk Management Framework.