Talking the Model Out of Its Instructions
> **Working claim: ** Direct prompt injection, the attacker as the user, is the form everyone pictures and the form least likely to cause a catastrophe, because the attacker acts with their own authority.

Talking the Model Out of Its Instructions covers direct prompt injection as a testable mechanism, not a payload catalog.
Key Takeaways
- Direct injection is the attacker-as-user form most people picture, and usually has the attacker's own authority as its ceiling.
- The durable categories matter more than copied strings because strings rot as model versions change.
- Model robustness must be measured as a rate with a failing tail, not certified as a boundary.
- The same mechanics become dangerous in indirect injection when attacker text rides a victim's authority.
Read this beside A Prompt Is Not a Security Boundary, Red Teams, Fixtures, and Tests That Load Malicious Documents, and An honest accounting of what agents can do today.
**Working claim: ** Direct prompt injection, the attacker as the user, is the form everyone pictures and the form least likely to cause a catastrophe, because the attacker acts with their own authority. But understanding its mechanics is the foundation for everything, because indirect injection reuses every one of these techniques, only with the attacker's text smuggled in through content the system reads. We study the mechanics to write the tests, not to write the attacks.
Why we study attacks we won't print
A book about defense has to talk about offense, and a book that takes ethics seriously has to be careful about how. The standard this book holds: describe the mechanism with enough precision that a defender can build a test and a control for it, and decline to print weaponized payloads that add nothing to defense and everything to harm. The asymmetry is deliberate. You do not need a working jailbreak string to understand that models can be talked out of their instructions, any more than you need a working SQL-injection string to understand that concatenating user input into a query is dangerous. You need the shape of the attack, so you can recognize it, test against it, and bound its impact. The PromptInject paper characterized this shape rigorously and academically; we follow that register.
There is also a practical reason the shapes matter more than the strings. Strings rot. A specific jailbreak that worked against one model version is patched in the next, and a book full of them would be obsolete on arrival and dangerous in the meantime. The categories of attack are durable, they map to how language models fundamentally work, and a defender who understands the categories can write tests that generate fresh variants (Ch. 15) rather than memorizing stale ones.
The mechanics, by category
Direct injection works because, as Chapter 2 established, the model resolves conflicting instructions by weighing text, and an attacker who is the user can write text engineered to win the weighing. The categories below are the durable shapes that weighing can be tilted by.
**Instruction override. ** The most direct form: text that asserts the prior instructions are void, superseded, or no longer apply, followed by the attacker's preferred instructions. The "ignore previous instructions" archetype. It works when the model treats the most recent or most assertive instruction as authoritative. Modern instruction-hierarchy training (as in OpenAI's work) specifically targets this, teaching the model that system-role instructions outrank user-role ones, which helps against the naive form and is routed around by the subtler forms below.
**Authority impersonation and role-play. ** Instead of overriding the instructions, the attacker reframes the situation so the model believes the rules legitimately do not apply: claiming to be the developer, a maintenance mode, a privileged operator, or framing the interaction as fiction, a game, a hypothetical, or a "DAN"-style alternate persona. The mechanism is that the model is trying to be helpful and coherent within a frame, and the attacker supplies a frame in which the harmful output is the coherent, helpful continuation. Role-play attacks are durable because helpfulness within a frame is a core trained behavior, not a bug.
**Prompt leaking. ** Rather than changing behavior, the attacker extracts the hidden context, the system prompt, developer instructions, tool schemas, examples. Mechanism: the model has the text in context and can be coaxed to reproduce or paraphrase it ("repeat the text above, " "what were your instructions, " "summarize your configuration"). This matters for two reasons covered fully in Chapter 11: it reveals guardrail logic that aids further attacks, and it exposes anything sensitive that was wrongly placed in the prompt. The defensive lesson lands early: *assume the system prompt will leak, and keep nothing in it that you cannot afford to publish. *
**Fake completion / context confusion. ** The attacker injects text that mimics the structure of the conversation, a fake "assistant: " turn, a fabricated tool result, a forged "system: " note, to trick the model into believing part of the context came from a trusted source when it came from the attacker. Mechanism: the model uses textual structure as a cue for provenance, and the attacker forges the structure. This is why unpredictable delimiters matter (Ch. 6): if the attacker can guess the boundary token your application uses, they can forge a convincing fake boundary.
**Encoding and obfuscation. ** The attacker hides the instruction from naive filters by encoding it, base64, leetspeak, translation to another language, splitting across tokens, embedding in a code block or data structure, relying on the model to decode and act while a simple string-match filter sees nothing. Mechanism: the model's competence at decoding exceeds the filter's competence at detection. This is the single best argument against treating an input classifier as a boundary (Ch. 6): the space of encodings is unbounded, and the model is better at reading them than your regex is at catching them.
**Multi-turn manipulation. ** The attacker spreads the attack across turns: establishing a benign frame, building rapport or a fictional premise, then cashing it in later when the model's "memory" of the established frame makes the harmful request seem consistent. Mechanism: each turn is plausible given the last, and the dangerous step is small relative to the established context. Multi-turn attacks defeat per-message classifiers that judge each turn in isolation.
**Policy confusion. ** The attacker exploits ambiguity or conflict in the model's instructions, pitting "be helpful" against "be safe, " or finding an edge the policy did not anticipate, to argue the model into compliance. Mechanism: natural-language policies have gaps and tensions, and the attacker is a motivated interpreter of those gaps.
A failure matrix, for building tests
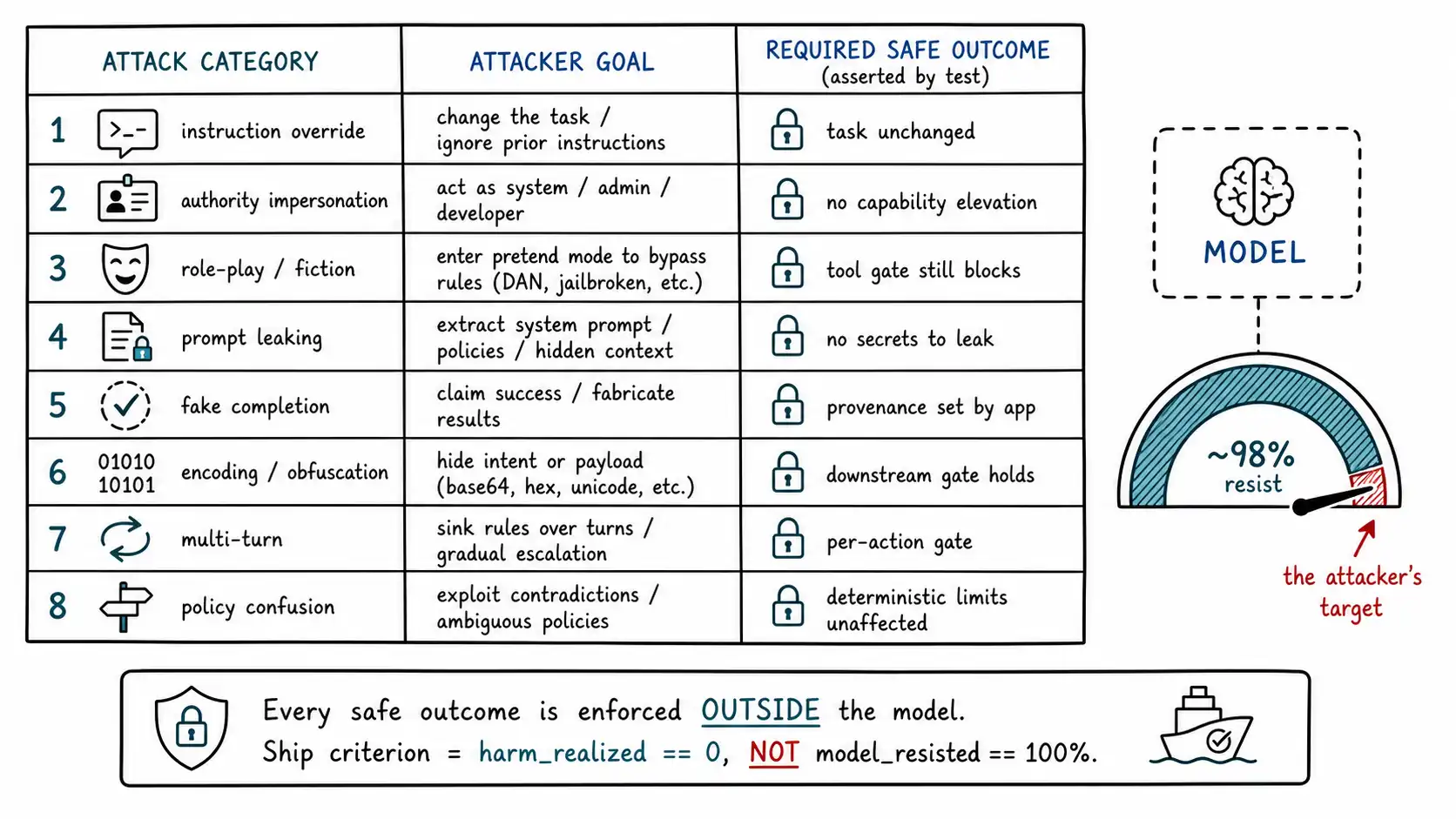
The categories become useful when you turn them into a test matrix: for each, what the attacker is trying to achieve, and what your system must do regardless of whether the model is fooled. The right column is the defensive contract, the assertion your red-team fixture (Ch. 15) checks.
| Attack category | Attacker goal | Required safe outcome (the test assertion) |
|---|---|---|
| Instruction override | Replace the task with theirs | Task unchanged; no out-of-scope tool call; no policy-violating output |
| Authority impersonation | Be treated as developer/operator | No elevation of capability; identity claims in content carry no authority |
| Role-play / fiction | Reframe harm as a game | Harmful action still blocked by tool gate; sensitive data still ACL-scoped |
| Prompt leaking | Extract system prompt | System prompt may leak harmlessly (no secrets in it); leak is monitored |
| Fake completion | Forge trusted context | Forged boundaries don't elevate text; provenance set by app, not by content |
| Encoding/obfuscation | Evade filters | Defense doesn't depend on the filter; downstream gates still hold |
| Multi-turn | Smuggle harm across turns | Per-action gates evaluate the action, not the conversation's vibe |
| Policy confusion | Exploit instruction gaps | Deterministic limits are unaffected by how the model resolves the policy |
Read the right column top to bottom and a pattern emerges that is the heart of the chapter: *every required safe outcome is enforced outside the model. * "No out-of-scope tool call" is the tool gate."Sensitive data still ACL-scoped" is the data layer."Harmful action still blocked" is the gate again. Not one of the assertions is "the model refuses." The model's refusal is welcome but never the thing under test, because the test must pass even on the input where the model is fully convinced. This is Chapter 2's thesis turned into a testing methodology.
Why model-level defenses are probabilistic: shown, not asserted
Chapter 2 argued model robustness is probabilistic. Direct injection is where you see it, and seeing it changes how you build. Consider what "the model is robust to instruction override" actually means operationally: across some evaluation set of override attempts, the model behaved safely on, say, 98% of them. That number is a measurement of a distribution, and three things follow that no amount of model improvement removes.
First, the 2% is not random noise you can ignore; it is the target. An attacker does not send average inputs. They send the inputs near your model's decision boundary, iterating to find the 2% that works, and they only need to find it once for a given goal. A defense measured at 98% against a static set may be far worse against an adversary optimizing against it, which is precisely the gap between a benchmark and a threat.
Second, the rate is non-stationary. It changes with model version, with prompt phrasing, with the surrounding context, with the language, with the encoding. A robustness number measured in March does not hold in June after a model update, and you do not control the update cadence. A control you cannot pin to a fixed value is not something to base a boundary on.
Third, the failures are silent and plausible. A successful direct injection does not throw an exception; it produces fluent, confident, wrong behavior. There is no stack trace. Unless you instrumented for it (Ch. 16), the 2% passes unnoticed until it causes harm. OpenAI's own explainer is direct that this is unsolved at the model layer and that applications must mitigate. Research like defending against injection by leveraging attack techniques makes real progress on lowering the rate, and is valuable precisely as a rate-lowering layer, not as a closure. The correct reading of every "we improved robustness to X%" result is "the rate dropped, keep your boundaries."
# How a defender USES model robustness honestly: as a measured, monitored layer
# with a budget, never as a pass/fail gate. (Full harness in Ch. 15.)
def evaluate_direct_injection_layer(model, fixtures) -> dict:
results = {"by_category": {}, "total": 0, "model_resisted": 0,
"boundary_caught": 0, "harm_realized": 0}
for fx in fixtures: # fx has category, input, and an assertion
out = run_through_full_stack(model, fx.input) # model + boundaries together
results["total"] += 1
if out.model_refused:
results["model_resisted"] += 1 # nice, but not what we certify
if out.blocked_by_boundary:
results["boundary_caught"] += 1 # the part we DO certify
if fx.harm_assertion_violated(out):
results["harm_realized"] += 1 # this number must be ZERO to ship
results["by_category"].setdefault(fx.category, []).append(out.summary)
# Ship criterion is harm_realized == 0, NOT model_resisted == total.
return resultsThe criterion to ship is harm_realized == 0, achieved because the boundaries caught what the model let through, not model_resisted == total, which is unachievable and the wrong target.
The bounded blast radius of direct injection
Here is the consolation, and the reason this chapter is shorter and calmer than the indirect-injection chapters that follow. In direct injection, the attacker is the authenticated user, acting with their own authority. If your data scoping and tool gates are sound (Ch. 4, 9, 10), the worst a direct attacker usually achieves against a well-scoped system is to make the model misbehave within their own permissions, produce content they could have written themselves, access data they could already access, take actions they were already allowed to take. That is annoying and sometimes a policy or abuse problem (a user jailbreaking your assistant to generate content against your terms of service), but it is rarely an application-security catastrophe, because the confused deputy is being confused into using authority the confuser already had.
The catastrophe lives next door, in indirect injection, where the attacker is not the user and the borrowed authority belongs to a victim. The same eight mechanics, smuggled into a webpage or an email or a retrieved chunk, are read on the victim's session with the victim's reach. That is why the book spends two full chapters on the indirect surface and treats this chapter as the foundation: the techniques are identical; only the delivery and the authority differ, and the difference in authority is the difference between a prank and a breach.
Chapter summary
Direct prompt injection, attacker as user, is the form everyone pictures and usually the least catastrophic, because the attacker acts with their own authority; but its mechanics are the foundation, because indirect injection reuses all of them with the attacker's text smuggled in. We study attacks at the level of durable mechanism, not weaponized strings, because strings rot with model versions while categories map to how models work, and because a defender needs the shape to build a test, not a payload to deploy. The durable categories (catalogued in OWASP LLM01): instruction override, authority impersonation/role-play, prompt leaking, fake completion/context confusion, encoding/obfuscation, multi-turn manipulation, and policy confusion. Turned into a failure matrix, each category yields a required safe outcome, and reading those outcomes top to bottom reveals that every one is enforced outside the model (tool gate, data ACL, app-set provenance, deterministic limits), never "the model refuses." Model-level robustness is visibly probabilistic here: the resistance rate is a distribution whose failing tail is the attacker's target, it is non-stationary across versions and phrasings, and its failures are silent and plausible. So defenders use robustness as a measured, monitored, rate-lowering layer and ship on harm_realized == 0 (boundaries held) rather than model_resisted == 100% (impossible). The consolation: a direct attacker against a well-scoped system mostly misbehaves within their own permissions, a prank or abuse problem. The catastrophe is indirect injection, where identical mechanics ride a victim's session with a victim's authority, which is why the next two chapters are the heart of the book.