Operating Models and the New Roles
Centralized, embedded, or federated AI teams, plus the four roles that did not exist three years ago and now decide whether your automation creates use or chaos.

A founder showed me two org charts in the same meeting and asked which was right. The first had a central "AI team" of six people who owned all things AI: tooling, evals, governance, the lot. The second had no AI team at all; AI capability was embedded in every product team, each owning their own. He had been arguing with his head of product for a week about which to build, and he wanted me to break the tie.
I told him the question was wrong, which is not what someone wants to hear after a week of arguing, but it was true. "Centralized versus embedded" is the wrong axis because it asks where the people sit, and the thing that actually has to be decided is where the ownership sits, and those are different questions with different answers for different parts of the work. The right operating model is almost never all-central or all-embedded. It is a deliberate split, with some things owned centrally because they need consistency and governance, and some things owned at the edge because they need context and speed, connected by a feedback loop that most organizations forget to build. This chapter is about getting that split right, and about the four new roles that the split requires, roles that did not exist three years ago and that your org chart probably still does not have boxes for.
Three operating models, and what each is actually for
There are three patterns, and each is correct for a specific thing rather than as a whole-organization religion.
Centralized. A single team owns the AI capability, end to end, for the whole organization. Tooling, model selection, evaluation, governance, guardrails. Every other team consumes it. The strength is consistency and control: one place sets the standard, one place owns the governance, one place builds the deep expertise. The weakness is distance from context: the central team does not understand each product's domain, so they build generic capability that fits no specific workflow well, and they become a bottleneck because every team's needs route through them. Centralized is correct for the things that must be consistent: governance, guardrails, model risk, the acceptance bar, the audit trail. You do not want forty teams each inventing their own AI governance, badly.
Embedded. Each product or function team owns its own AI capability, built into the team. The strength is context and speed: the people closest to the domain own the automation of that domain, so it fits, and there is no central bottleneck. The weakness is the mirror of the centralized strength: no consistency, duplicated effort, forty teams reinventing the same eval harness, and governance that ranges from excellent to nonexistent depending on the team. Embedded is correct for the things that must fit the domain: the specific workflows, the prompts, the domain-specific evaluation of whether the output is actually right for this product.
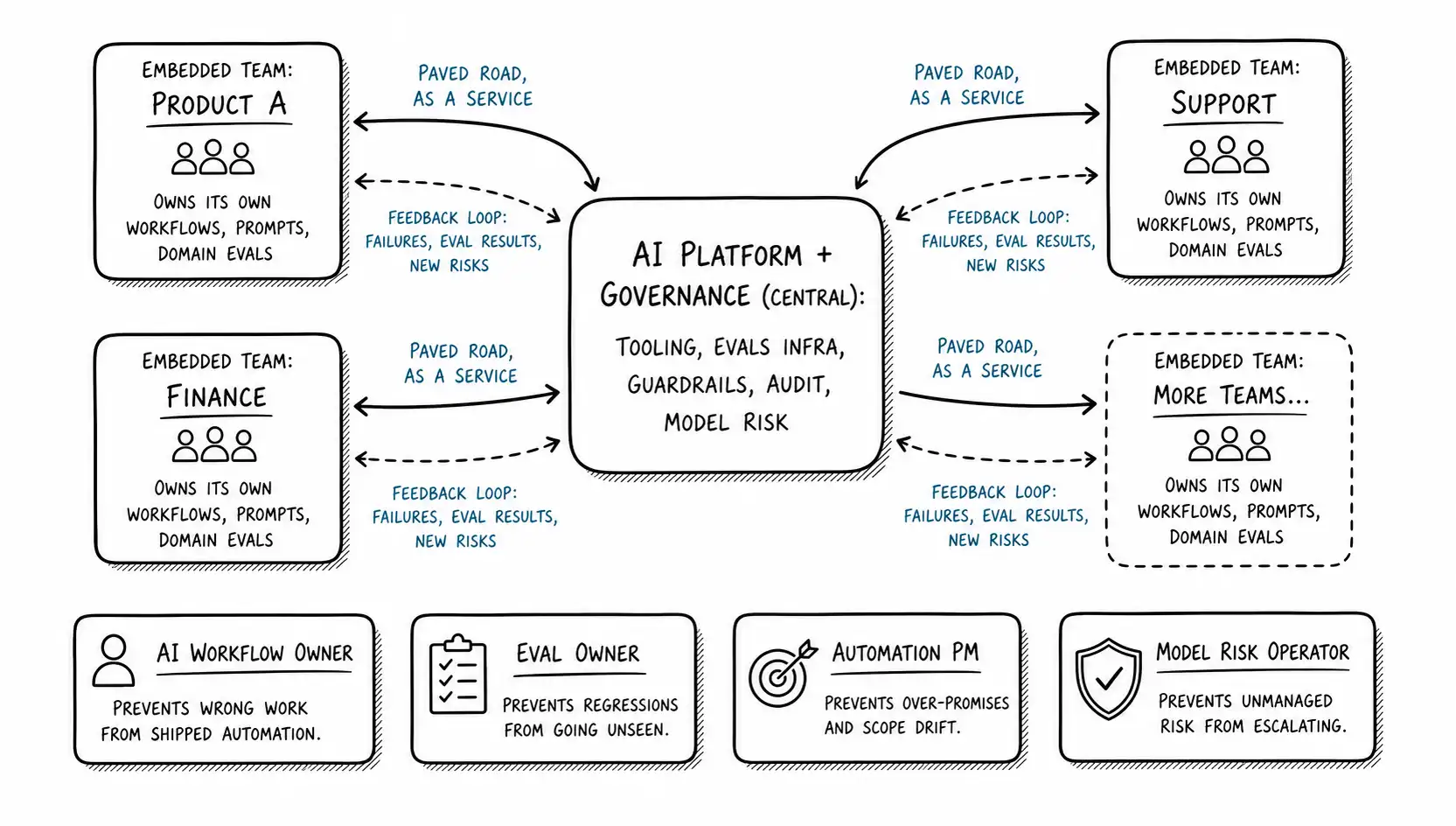
Federated. A central team owns the platform and the governance, the things that must be consistent, and provides them as a product to embedded teams who own the application of AI within their domain, the things that must fit. This is the Team Topologies platform pattern applied to AI: a platform team that treats its internal users as customers, reducing their cognitive load by providing paved-road tooling, evals, and guardrails, while stream-aligned teams own the actual automation of their actual work. The central team is a governor and enabler, not a gatekeeper. The embedded ownership is real, not delegated permission.
Federated is the answer for most organizations past a certain size, not because it is a compromise but because it correctly assigns each kind of ownership to the place that can actually hold it. Consistency-ownership goes central. Context-ownership goes to the edge. The two are connected by a platform-as-product relationship and, critically, a feedback loop.
The design table
Here is the artifact for choosing. For each AI capability or concern, decide where ownership should sit, and the decision rule is the consistency-versus-context tradeoff.
| Concern | Owned centrally | Owned at the edge | Why |
|---|---|---|---|
| Model selection and access | Yes | No | Consistency, cost control, risk |
| Governance, guardrails, audit | Yes | No | Must be uniform; regulators don't accept "it varies by team" |
| Eval infrastructure | Yes | No | Build once, everyone uses it |
| Eval content (what good looks like here) | No | Yes | Only the domain team knows correct for their work |
| Workflow design and prompts | No | Yes | Needs deep domain context |
| The acceptance bar (general policy) | Yes | No | Consistent floor across the org |
| Owning specific AI-generated artifacts | No | Yes | Ownership needs context; central team has none |
| Incident response for AI output | Mostly | Partly | Central owns the pattern; edge owns the instance |
The recurring logic: anything that must be the same everywhere goes central; anything that must fit a domain goes to the edge. The mistake the founder was making was treating it as one decision when it is one decision per row, and the rows split cleanly once you ask "does this need to be consistent or does this need to fit?"
The most-forgotten row is the feedback loop, which is not in the table because it is not a concern, it is the connective tissue. The central team learns what guardrails to build from the failures the embedded teams hit. The embedded teams get better tooling because the central team aggregates what everyone is hitting. Without the loop, federated degrades into centralized-with-extra-steps (central dictates, edge resents) or embedded-with-a-useless-central-team (central builds things nobody uses). The loop is what makes federated a system rather than two disconnected halves.
The four new roles
Federated structure needs roles that most org charts do not have. These are not titles invented to look modern. Each owns a specific failure mode from earlier in this book, and if no one owns the failure mode, the failure happens. I will define each by the disaster it prevents.
The AI Workflow Owner. This is the named human from the ownership chapter, made into a role. They own a specific AI-assisted workflow end to end: the artifacts it produces, the review queue, the acceptance bar, the incident response. They pass the five conditions for that workflow. The disaster they prevent is the orphaned artifact stream, the AI-generated work that reaches consequence with no one accountable. In a federated model, workflow owners sit at the edge, in the embedded teams, because ownership needs context. This is frequently a senior who has made the transition from production to judgment that the seniority chapter described; owning an AI workflow is exactly the judgment-and-ownership-heavy role that seniority now means.
The Eval Owner. Someone has to own the question "what does correct output look like for this workflow, and how do we measure it?" This is harder and more important than it sounds, because the acceptance bar is the thing that turns "the output looks plausible" into "the output is actually right," and plausibility is exactly what AI manufactures and humans fail to question. The eval owner builds and maintains the evaluation: the test cases, the rubrics, the regression suite for the AI output. The disaster they prevent is silent quality drift, the slow degradation where output keeps looking fine while getting subtly worse, which no one catches because no one owns the definition of "fine." Eval infrastructure is central (build the harness once); eval content is at the edge (only the domain team knows what correct means for their work). The eval owner role therefore exists in both places, with different scopes.
The Automation PM. A product manager whose product is the automation itself: which workflows AI is allowed to operate in, at what risk posture, with what guardrails. They own the Automation Displacement Grid for their domain, deciding what is in the easy-win quadrant and what is in the trap zone, and they own the decision to keep something human when the tool could do it. The disaster they prevent is the trap-zone deployment, AI pointed at a high-risk workflow because it saved effort, with no one having explicitly decided the risk was acceptable. The automation PM is the person who says "yes the tool can do this, and no we are not letting it, here is why." They are an allocator of where automation is allowed, which is the institutional version of the manager-as-allocator from the span-of-judgment chapter.
The Model Risk Operator. This role borrows directly from how regulated finance has handled model risk for decades, the supervisory guidance on model risk management that banks have lived under since 2011, which establishes that any model used for consequential decisions needs independent validation, ongoing monitoring, and a named owner of its risk. The model risk operator owns the blast radius: what happens when the model is wrong, how wrong it can be, how that is monitored, and what the containment is. They own the error budget from the ownership chapter. The disaster they prevent is the unbounded failure, the AI error that propagates further than anyone realized was possible because no one owned the question "how bad can this get?" In a federated model this is typically central, because containment and risk monitoring must be consistent, with edge teams feeding it domain-specific risk through the loop.
These four roles are not necessarily four headcount. In a startup, one person may wear all four hats for the whole company. In an enterprise, each may be a team. The point is not the headcount; it is that each ownership must be assigned to someone, because each corresponds to a failure mode that happens when no one owns it. The roles are the failure modes given names and homes.
How the pattern scales
The same logic produces different shapes at different sizes, and pretending one shape fits all is how the founder got stuck.
Startup (under ~30 people). Do not build a central AI team; you do not have the people and you would create a bottleneck. Ownership is embedded by default because everyone is close to everything. The four roles collapse into one or two people wearing all the hats, often a technical founder. The risk at this stage is not inconsistency, it is the trap zone: a small team moving fast will point AI at high-risk workflows because it is fast, and there is no one whose job is to say no. Assign the automation-PM hat explicitly to someone, even part time, even the founder, so that "should AI do this here" is a question someone owns.
Mid-market (~30 to 300). This is where federated becomes necessary and where most organizations get it wrong, usually by either over-centralizing (a central AI team that becomes a bottleneck everyone routes around) or under-governing (embedded everywhere with no consistency and no governance, which works until the first incident or the first audit). Build the thin central platform-and-governance layer, keep workflow and eval-content ownership at the edge, and build the feedback loop deliberately. This is the stage where the four roles start to differentiate into distinct people.
Enterprise (300+). Federated with real teams in each role, and the new failure mode is the loop breaking: central governance ossifies into bureaucracy that edge teams route around, or edge teams fragment so far that central loses visibility into the risk. The enterprise discipline is keeping the central layer a platform and enabler rather than a gatekeeper, and keeping the feedback loop alive against the natural tendency of large organizations to let central and edge stop talking. The model risk operator becomes especially important here, because at enterprise scale the blast radius of an unowned AI failure is large enough to be existential, and regulated enterprises will be held to model-risk standards whether or not they adopted them voluntarily.
The transition trap
One warning that applies at every size. The natural sequence is: adopt the tool, see the productivity gain, and stop there, declaring victory at the tool-adoption stage. That is the headcount-first spreadsheet thinking the whole book is against, and it is where most organizations are stuck right now. They bought the tools, booked the production gain, and never changed the operating model, which means they have all the artifact volume and none of the ownership structure, which means they are accumulating the queue, the leakage, the compression, and the orphaned artifacts that the earlier chapters described.
The operating model is the work. The tool is the easy part, the part you can buy. Redrawing ownership, building the federated structure, staffing the four roles, building the feedback loop: that is the part you cannot buy, and it is the part that determines whether your tool adoption produces use or chaos. The founder with the two org charts eventually built the third option, the federated one, with a thin central platform team and embedded workflow owners, and a feedback loop he had to be reminded twice to actually build. The argument with his head of product dissolved once they stopped asking where the people sit and started asking where each kind of ownership belongs. That reframe is the whole chapter, and it is the bridge to the last one, where we turn all of this into a checklist you can run on Monday.
Key Takeaways
- "Centralized versus embedded" asks where the people sit; the real question is where each kind of ownership belongs. Consistency-ownership (governance, guardrails, model risk) goes central; context-ownership (workflows, prompts, domain evals, the artifacts themselves) goes to the edge.
- The federated model assigns each correctly and connects them with a platform-as-product relationship and a feedback loop. Skipping the loop degrades federated into centralized-with-resentment or embedded-with-a-useless-center.
- Four new roles each own a specific failure mode: the AI Workflow Owner (orphaned artifacts), the Eval Owner (silent quality drift), the Automation PM (trap-zone deployment), and the Model Risk Operator (unbounded blast radius). They are failure modes given names and homes, not necessarily four headcount.
- The pattern scales differently: startups embed and assign the automation-PM hat explicitly to resist the trap zone; mid-market builds the thin central layer and the loop; enterprise fights ossification and loop-breakage and lives under model-risk standards.
- The transition trap is stopping at tool adoption. The tool is the part you can buy; the operating-model redraw is the part that determines use versus chaos, and it is the actual work.