The Output Multiplier Is Also an Ambiguity Multiplier
Every artifact AI generates also generates a decision about whether it is right, and those decisions are the work nobody budgeted for.

Read this alongside the Pov Vol 3 book, the AI-Native thesis, and the full book library when you want the surrounding argument. A failed demo is a good place to start this one, because it shows the mechanism in miniature.
A team I worked with had built an internal tool that drafted customer-facing incident communications. You paste in the incident details, it writes the status-page update, the email, and the executive summary. The demo was flawless. Three polished artifacts in eight seconds. The room was impressed. Then someone asked the question that broke it: "When there's a real incident at 2 a.m., who decides whether to send what it wrote?"
Silence. Because the tool had not removed the hard part of incident communications. The hard part was never the writing. The hard part was the judgment call about what to disclose, when, to whom, and with what legal and reputational exposure. The tool had made the writing free and left the judgment exactly where it was, except now the judgment had to be made three times as fast, on three artifacts, under pressure, by whoever happened to be on call. The demo had multiplied the output and, with it, multiplied the number of high-stakes decisions per unit time. The team had built an ambiguity multiplier and called it a productivity tool.
Every artifact carries a decision
Here is the principle. An artifact is never just an artifact. It is an artifact plus a decision: is this right, and should it ship? When production was expensive, that decision was cheap relative to the production, almost free, because you had spent hours making the thing and a few more minutes deciding about it was nothing. The ratio of decision-cost to production-cost was small, so we never accounted for the decision separately. It rode along with the work.
AI inverts the ratio. Production drops toward zero. The decision does not. So the decision-cost, which used to be a rounding error on top of production, becomes the dominant cost, and there are now many more decisions because there are many more artifacts. You did not just multiply output. You multiplied the number of irreducible judgment calls, and you did it in a domain where the judgment was the entire point.
This is why "AI handles the boring part so humans do the interesting judgment" is half true in a way that misleads. AI does handle the production. But it does not reduce the judgment; it concentrates and accelerates it. The human is left doing nothing but judgment, at a cadence set by a machine that produces faster than any human can decide. That is not liberation. That is a person at the end of a conveyor belt that just got faster, holding the one tool, judgment, that cannot be sped up.
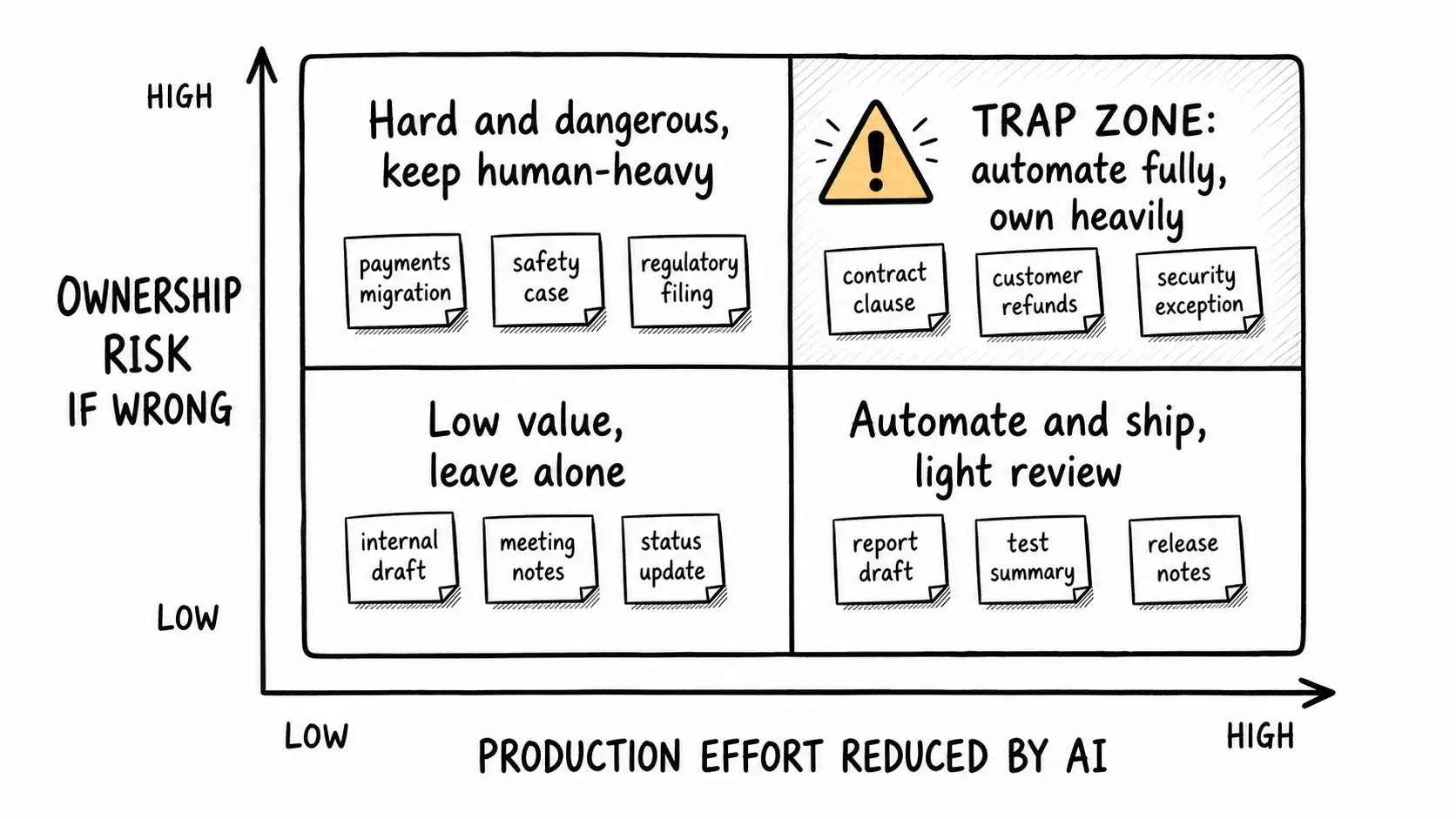
The Automation Displacement Grid
This brings me to the framework that organizes the whole book's treatment of which work to automate and how to own it. It is a two-by-two, but the axes are the point, because almost every rollout I have seen confuses them.
The horizontal axis is production effort reduced by AI: how much of the labor of making this artifact does the tool actually remove? Low on the left, high on the right.
The vertical axis is ownership risk if wrong: what is the cost if this artifact is incorrect and ships? Low at the bottom, high at the top.
These two axes are independent. The amount of effort AI saves has nothing to do with the cost of being wrong. A tool can make a high-stakes legal clause trivial to draft and a low-stakes internal memo trivial to draft, and the effort saved is identical while the risk is wildly different. The grid forces you to hold both in mind, which is exactly what the spreadsheet, optimizing only for effort saved, refuses to do.
The four quadrants:
- Bottom-left, low effort saved, low risk. Leave it alone. Automation here is busywork that adds a dependency for no gain.
- Bottom-right, high effort saved, low risk. This is the easy win. Automate aggressively, review lightly, sleep well. Internal first drafts, boilerplate, low-stakes summaries. Most of the genuine productivity story lives here, and it is real.
- Top-left, low effort saved, high risk. AI does not help much and the stakes are high. Keep these human-heavy. Do not let the existence of a tool tempt you into using it where it saves little and risks much.
- Top-right, high effort saved, high risk. This is the trap zone, and it is where every painful incident I have seen originated. The tool is so good at producing the artifact that the effort saved is enormous, which makes the work feel done. But the cost of being wrong is also enormous. The incident communications tool lived here. So does AI-generated production code in a payments path, an AI-drafted contract clause, an AI-built financial model behind a board decision. The effort axis says "automate, it's basically free." The risk axis says "if this is wrong, it's catastrophic." The two axes are screaming opposite instructions, and the effort axis wins by default because it is the one that feels good and shows up on the dashboard.
The rule the grid encodes: automation should be governed by the risk axis, not the effort axis, but human attention is naturally drawn to the effort axis. The top-right is the most dangerous place in any organization adopting AI, because it combines maximum temptation to automate with maximum cost of getting it wrong, and the temptation is what you feel while the cost is what you defer.
Worked example: the same tool across the grid
Take one capability, AI that writes code, and watch it land in different quadrants depending on where you point it.
| Use | Effort saved | Risk if wrong | Quadrant | Ownership move |
|---|---|---|---|---|
| Internal admin script, run once, by author | High | Low | Bottom-right | Ship, glance at it |
| Test scaffolding for existing covered code | High | Low | Bottom-right | Ship, light review |
| New feature in a non-critical internal tool | High | Medium | Center | Normal review by a second human |
| Migration that alters a production database | High | Very high | Top-right TRAP | Human-heavy review, named owner, rollback plan, staged rollout |
| Auth or payments path change | High | Very high | Top-right TRAP | Treat AI output as a junior's first draft from someone untrusted: full review, owner, tests, no exceptions |
The tool is equally helpful in every row. The effort-saved column is high almost everywhere. If you let that column drive policy, you will review the migration and the payments change as lightly as the throwaway script, because they all "felt" equally automated. The grid's job is to override that feeling with the risk column, which says the bottom two rows demand an entirely different ownership posture even though the tool's contribution was identical.
Ambiguity has a second source: plausibility
There is a reason the trap zone is sharper with AI than with old automation, and it is worth naming because it changes how you review. Traditional automation failed loudly. A broken script threw an error. A failed batch job did not run. The failure was unambiguous, which made the decision easy: it broke, fix it.
AI fails plausibly. It produces an artifact that is well-formed, confident, and wrong in ways that require domain expertise to detect. The migration locks a table you did not expect. The contract clause is subtly unenforceable. The financial model embeds an assumption that is reasonable in general and false for your business. The artifact looks exactly as right as a correct one, which is precisely the condition that defeats human reviewers. The human-factors literature on automation bias and complacency, synthesized by Parasuraman and Manzey in 2010, shows that this is not a training problem you can solve with reminders: complacency in monitoring automation appears in novices and experts alike, intensifies under multitask load, and resists simple practice. Plausible output plus a busy reviewer is a known recipe for missed errors, and AI manufactures plausible output at scale.
So the ambiguity multiplier has two factors. AI produces more artifacts, each carrying a decision, and it produces them in a form specifically optimized to make the decision feel unnecessary. More decisions, each one harder to take seriously. That is the real load, and it lands hardest exactly in the trap zone, where the artifacts are most polished and the stakes are highest.
What this changes about how you staff and review
If every artifact carries a decision, and the decisions concentrate in the trap zone, and the artifacts are engineered to look decision-free, then three things follow for org design, and I will develop each in later chapters.
First, review is now a primary activity, not an overhead. When production was the bottleneck, review was a tax on production. Now review is the bottleneck, which means it is the work, which means it has to be staffed, measured, and rewarded as work rather than treated as something senior people do in the cracks. The chapter on the span of judgment is about exactly how much of it one human can hold.
second, the trap zone needs named owners, not just reviewers. A reviewer says "this looks fine." An owner says "I am accountable if this is wrong." Those are different commitments, and the trap zone needs the second one. The chapter on human-in-the-loop is about why a reviewer without ownership is theater.
Third, you should map your workflows onto the grid before you map your tools onto your workflows. Most rollouts do it backward: they buy a tool, point it everywhere it can save effort, and discover the trap zone during the incident. Run the grid first. Decide, per workflow, whether you are in the easy win, the leave-alone, the keep-human, or the trap, and set the ownership posture accordingly before the tool ever touches the work.
The incident-communications team eventually shipped their tool, narrowed to the bottom-right: it drafts the routine, low-stakes updates for minor incidents, and a human writes anything that touches a major incident from scratch. Same tool, repositioned out of the trap zone by an act of judgment about where it was allowed to operate. That repositioning is the work the grid exists to force. The tool was never the question. Where you let it operate, and who owns the output where you do, is the entire question.
Key Takeaways
- Every artifact carries a decision, "is this right and should it ship," and AI drops production cost toward zero while leaving decision cost unchanged, so judgment becomes the dominant cost and there is far more of it.
- The Automation Displacement Grid plots effort-saved against risk-if-wrong. The axes are independent; the spreadsheet optimizes effort while risk is what hurts you.
- The top-right "trap zone," high effort saved and high risk, is where incidents originate, because maximum temptation to automate coincides with maximum cost of being wrong, and the temptation is felt now while the cost is deferred.
- AI fails plausibly, not loudly, and the automation-bias literature shows plausible output plus a busy reviewer reliably defeats both novices and experts. The ambiguity multiplier has two factors: more decisions, each harder to take seriously.
- Govern automation by the risk axis, staff review as primary work, demand named owners in the trap zone, and map workflows onto the grid before pointing tools at them.