Why Productivity Is Not Capacity
A team can produce more and absorb less at the same time, and the spreadsheet that conflates the two will quietly drown you.

Let me give you a model first, because this chapter is really about a single accounting error, and the error is easiest to see as math before it is seen as management.
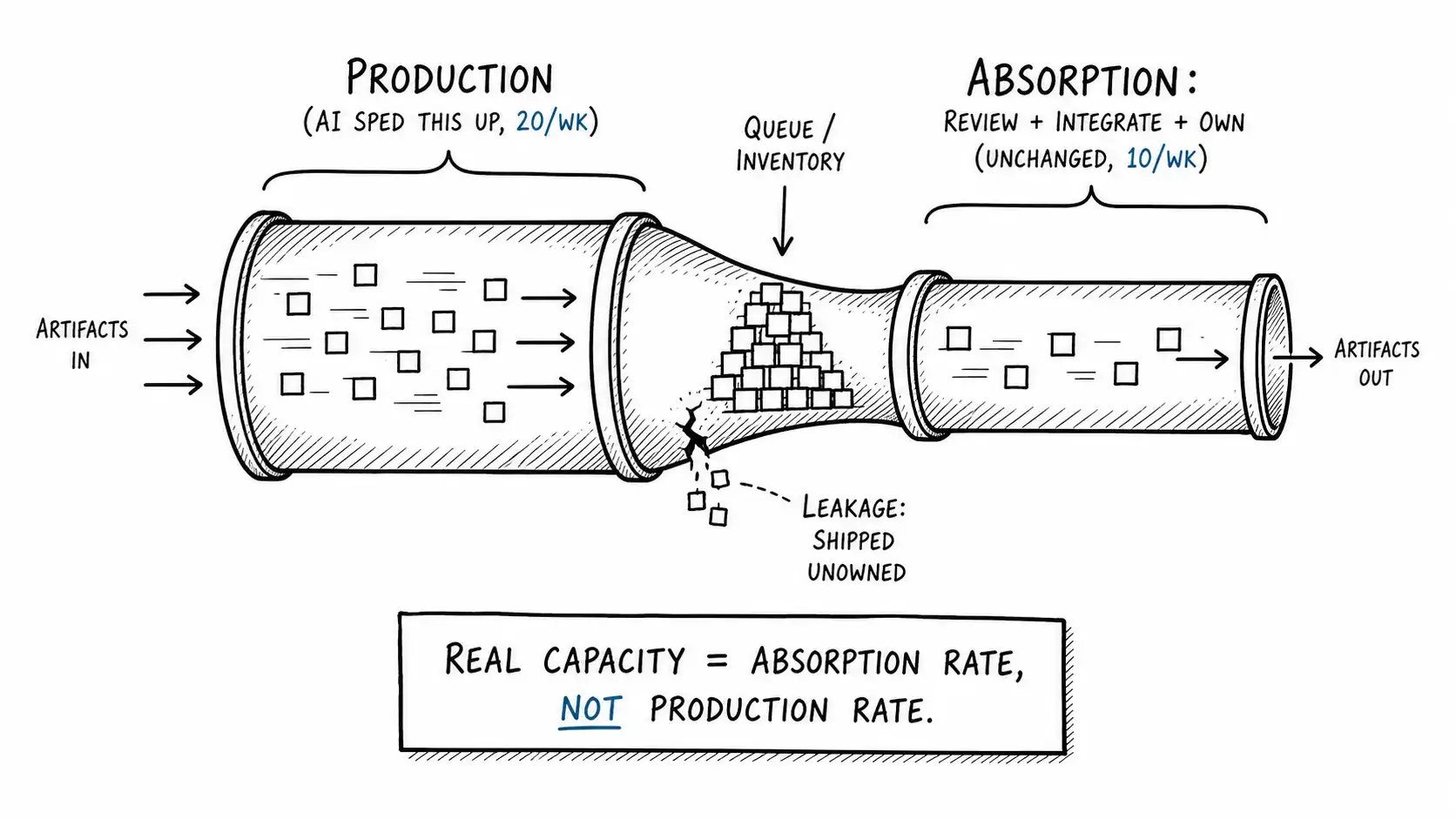
Imagine a workflow as a pipe with two stages. Stage one is production: making the artifact. Stage two is absorption: reviewing it, integrating it, owning it, and answering for it. Work only becomes value when it passes through both stages. An artifact stuck in stage two is not value. It is inventory, and inventory has a holding cost: it ages, it conflicts with other inventory, and it represents risk that has been created but not yet resolved.
Now the AI rollout arrives and roughly doubles the rate of stage one. Production throughput goes from, say, ten artifacts a week to twenty. The CFO's spreadsheet records this as a doubling of capacity, because the spreadsheet has one stage, not two. But absorption did not double. Reviewing, integrating, and owning are judgment work, and judgment is the part AI does not accelerate. So absorption stays at roughly ten a week. You are now producing twenty and absorbing ten. The other ten do not vanish. They queue.
This is the whole chapter. Productivity is a property of stage one. Capacity is a property of the slower of the two stages. When you speed up only the fast stage, you increase productivity and the queue at the same time, and you have added zero capacity. You may have subtracted it.
The queue is where the cost hides
Queueing theory is unsentimental about this. When the arrival rate at a stage approaches its service rate, waiting time does not climb linearly. It climbs toward infinity. The closer absorption-arrival gets to absorption-service, the more violently the queue and the wait blow up. Donald Reinertsen made this the spine of The Principles of Product Development Flow, where he argues that the dominant hidden cost in product organizations is the cost of queues, and that managers systematically ignore it because queues of information are invisible. You can see a warehouse full of unsold inventory. You cannot see a review queue, an integration backlog, or a pile of artifacts that shipped without anyone owning them. So you manage the visible thing, production, and let the invisible thing, absorption, silently determine your real throughput.
AI is a queue-generating machine pointed straight at the invisible stage. It floods the fast stage with output and leaves the slow stage to drown quietly.
DORA already measured this for you
This is not a thought experiment. Google's 2024 DORA report studied software delivery across thousands of respondents and found something that confused a lot of people: increasing AI adoption was associated with higher individual productivity and lower delivery throughput and stability. A 25 percent increase in AI adoption correlated with an estimated 1.5 percent decrease in delivery throughput and a 7.2 percent decrease in delivery stability.
How can more productivity mean less delivery? Because productivity is stage one and delivery is the whole pipe. DORA's own reading is that AI inflates batch size: it is now so cheap to write more code that change sets get bigger, and bigger batches move slower and break more, because they are harder to review, harder to integrate, and harder to roll back. The teams got more productive at production and less capable at delivery. The two numbers moved in opposite directions, exactly as the two-stage model predicts.
If you take one external citation from this book into your next planning meeting, take that one. It is the empirical proof that productivity and capacity are different quantities, measured at scale, by a credible source, against the grain of the hype.
The METR result is the same lesson at the individual level
The METR randomized controlled trial of 2025 is even sharper because it removes the organizational excuse. Sixteen experienced developers, working on their own mature open-source repositories, with tasks randomly assigned to allow or forbid AI tools. The developers predicted AI would make them about 24 percent faster. After the study they believed it had made them about 20 percent faster. It actually made them 19 percent slower.
Sit with the gap between the perception and the measurement. These were skilled people on their own code, and they could not feel that the tool was slowing them down. The artifacts came fast, the typing felt productive, the dopamine of generation was real. But the total time to a correct, integrated, owned change went up, because the parts AI did not help with, understanding the existing system, deciding what was actually right, fixing the plausible-but-wrong output, expanded to swallow the time the generation saved.
For our purposes the headline is not "AI is slower." That result is specific to expert developers on mature code and will not generalize everywhere. The headline is that the actors themselves systematically misjudged their own capacity, mistaking production speed for delivery speed by a margin of nearly 40 percentage points. If individuals cannot feel the difference on their own work, your organization absolutely cannot feel it on aggregate dashboards. The conflation of productivity and capacity is not a spreadsheet error you will catch by being careful. It is a perceptual error baked into how generation feels.
Where the absorbed-but-unowned work goes
There is a third category I have been circling and need to name, because it is worse than a queue. Some artifacts do not wait in the absorption queue. They skip it. They ship without being reviewed, integrated thoughtfully, or owned, because the producer was fast and confident and nobody made them stop. These are not inventory. They are liabilities in production with no name attached.
This is the difference between a backlog and a leak. A backlog is visible and annoying and recoverable: the work waits, you can see the pile, you can add capacity or cut arrival. A leak is invisible and compounding: the work shipped, looks fine, and carries an unowned defect or unexamined assumption that will surface as an incident weeks later, at which point the postmortem discovers the artifact had no real owner. AI increases both, but the leak is the one that hurts, because the queue at least keeps the risk where you can see it.
So the true accounting is three quantities, not one:
- Throughput that actually delivers value: artifacts that passed both stages and are owned. This is the only number that should count as capacity.
- Inventory: artifacts produced but stuck in absorption. Holding cost, recoverable.
- Leakage: artifacts that shipped without absorption. Unowned liabilities, compounding.
The spreadsheet reports production volume and calls it the first number. It is usually the sum of all three, and the sum is a lie, because two of the three are costs masquerading as output.
A capacity calculator you can actually run
You do not need queueing math to fix this. You need to measure absorption, because nobody does. Here is the calculation, per workflow, per week.
production_rate = artifacts generated per week
absorption_rate = artifacts fully reviewed + integrated + owned per week
(measure this; do not assume it equals production)
if production_rate <= absorption_rate:
queue is stable. AI added real capacity. Good.
if production_rate > absorption_rate:
overflow = production_rate - absorption_rate
each week, "overflow" artifacts either:
- queue (inventory, growing backlog, holding cost), or
- leak (ship unowned, future incident surface)
real_capacity = absorption_rate # NOT production_rate
hidden_risk = overflow * weeks_runningThe single most important line is real_capacity = absorption_rate. Your capacity is the rate of the slow stage, full stop. Doubling production while absorption is flat does not give you a faster team. It gives you the same capacity plus a growing pile of inventory and leakage. If you staff, plan, or commit against production rate, you are committing against a number your organization cannot actually deliver, and the gap will surface as missed dates, surprise incidents, and burned-out absorbers.
Most teams have never measured absorption_rate because before AI it was implicitly equal to production rate, so there was nothing to measure. That equality is exactly what AI broke. Start measuring the slow stage. It is your real capacity and you almost certainly do not know what it is.
The three honest moves when production outruns absorption
Once you accept that capacity equals absorption, the menu of interventions is short and clarifying. There are exactly three honest moves, and most failed rollouts are an attempt to avoid all three.
- Raise absorption. Build real review capacity, better tooling for integration, more owners. This is expensive and slow because absorption is judgment work and judgment does not scale by buying more seats. But it is sometimes the right answer, especially for high-risk workflows.
- Lower production to match. Deliberately throttle generation in workflows where absorption cannot keep up. This feels insane to a leader who just paid for the productivity tool, which is exactly why nobody does it, which is exactly why queues explode. For high-risk, low-absorption workflows, capping production is the responsible move, not a failure of nerve.
- Reduce the absorption cost per artifact. Make each artifact cheaper to own through standardization, smaller batches, better provenance, and clearer acceptance criteria, so absorption rate rises without adding people. This is usually the highest-use move and the one this book spends the most time on, because it is an operating-model change rather than a headcount change.
The dishonest fourth move, the one the spreadsheet quietly recommends, is to let the overflow leak and call the production number your capacity. That move books the productivity gain immediately and pays for it later in incidents, and because the payment is deferred and the gain is immediate, it is the default. Naming it is half of resisting it.
Why this chapter comes before the org redesign
Everything else in the book is downstream of this distinction. Seniority, the apprentice gap, span of judgment, human-in-the-loop, incident ownership: all of them are mechanisms for raising absorption or lowering the absorption cost per artifact. You cannot reason about any of them while you still believe that more production equals more capacity, because that belief tells you the problem is solved when it is just relocated.
The manager from the introduction doubled production and felt his capacity had doubled, until the queue and the incidents told him otherwise. What had actually happened was that he had doubled the arrival rate at his organization's slowest, most invisible, most human stage, and that stage had not moved an inch. His nerves were correct. They were his absorption rate, trying to tell him something his dashboards could not.
Key Takeaways
- Work is a two-stage pipe: production (making artifacts) and absorption (reviewing, integrating, owning, answering for them). Value requires both stages. AI speeds only the first.
- Capacity equals the rate of the slower stage, which is absorption. Speeding production while absorption is flat adds zero capacity and grows a queue.
- DORA 2024 measured the effect at scale: more AI adoption, more individual productivity, but lower delivery throughput and stability, largely via bigger batches. METR 2025 showed individuals misjudge their own capacity by nearly 40 points.
- The real accounting has three quantities: delivered throughput (the only true capacity), inventory (queued, recoverable), and leakage (shipped unowned, compounding liability). The spreadsheet reports their sum and calls it output.
- Measure your absorption rate per workflow; almost nobody does, because it used to equal production by default. There are only three honest responses to overflow: raise absorption, throttle production, or lower absorption cost per artifact.