The Human in the Loop Fallacy
Putting a person at the end of an automated process is not ownership. Without context, authority, time, incentive, and escalation, it is theater.

Read this alongside the Pov Vol 3 book, the AI-Native thesis, and the full book library when you want the surrounding argument. I have sat in a lot of design reviews where someone says, with visible relief, "and there's a human in the loop." It is the phrase that ends the meeting. The risk has been addressed. The AI generates, a human reviews, the human catches the problems, ship it. Everyone relaxes.
I have learned to do the opposite of relax when I hear it, because "human in the loop" is the single most over-trusted phrase in AI deployment, and it is over-trusted because it sounds like ownership while usually being its absence. Putting a human at the end of a process is trivially easy. Putting a human there who can actually own the output is expensive, structural, and rare, and the gap between the two is where most "governed" AI systems quietly fail. This chapter is about that gap, and about the five conditions that separate real ownership from a person sitting decoratively at the end of a conveyor belt.
The aviation lesson nobody applied
We have run this experiment before, at enormous cost, in aviation. Cockpit automation arrived with the promise that the pilot would supervise the automation, a human in the loop, catching any error the system made. The human-factors community spent decades documenting what actually happened, and the findings are a direct warning to anyone deploying AI with a reviewer at the end.
The foundational synthesis is Parasuraman and Riley's 1997 "Humans and Automation: Use, Misuse, Disuse, Abuse," which catalogued how human supervision of automation fails in predictable ways. People over-rely on automation that is usually right ("misuse"), they fail to monitor it effectively when it carries most of the load, and crucially, their skill at the underlying task degrades from disuse, so that when the automation finally fails and the human must take over, the human is less capable than they would have been with no automation at all. Parasuraman and Manzey's 2010 work on complacency sharpened this: monitoring of reliable automation degrades under multitask load, affects experts and novices alike, and cannot be trained away with simple practice. A human assigned to catch the rare error of a usually-correct system is, by the structure of the situation, poorly positioned to catch it.
This is not an exotic edge case. It is the default outcome of putting a human in a supervisory loop over automation that is right most of the time, which describes essentially every AI deployment. The aviation industry learned, expensively, that "there's a pilot watching" is not a safety control unless the pilot has the training, the workload margin, the authority, and the active engagement to actually intervene. We are now repeating the experiment across every knowledge-work function, mostly without having read the results.
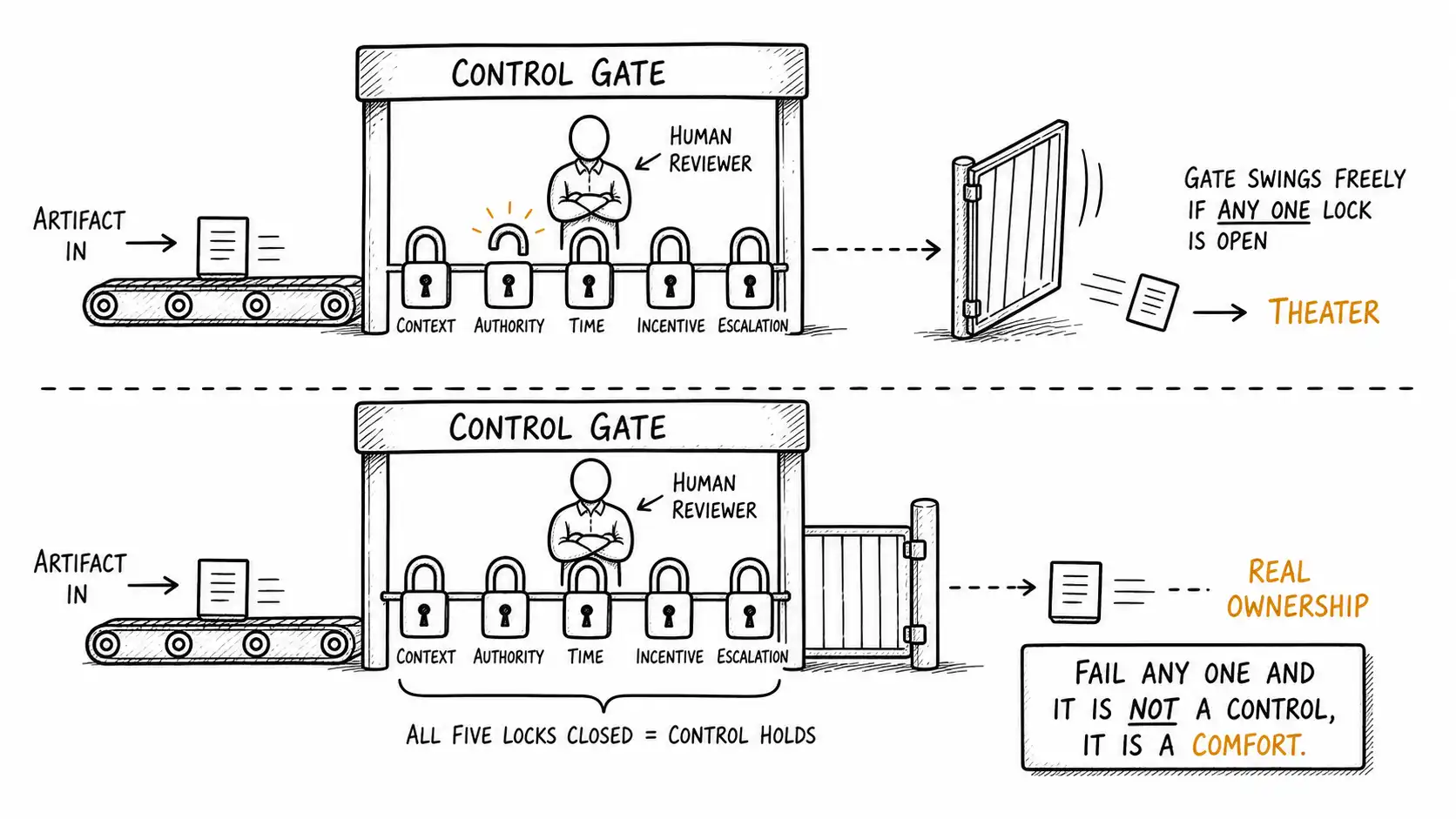
The five conditions
So when does a human in the loop constitute real ownership rather than theater? I use five tests. A review that fails any one of them is not ownership. It is a person decorating a process they cannot actually govern.
1. Context. Does the reviewer have enough understanding of the system to know whether the output is right? A reviewer who lacks the context to evaluate the output is not reviewing; they are rubber-stamping with extra steps. The junior reviewing AI code in the apprentice-gap chapter fails this test: they read the output, it looks plausible, they approve it, and they had no basis to do otherwise. Context is the prerequisite. Without it, the other four conditions do not matter, because the reviewer cannot tell good from bad in the first place.
2. Authority. Can the reviewer actually say no, and make it stick? In a lot of "human in the loop" designs, the human can flag a concern but cannot stop the process, or can stop it only by escalating to someone who will overrule them under time pressure. A reviewer who can be overridden by a deadline or a manager who "just wants it shipped" does not have the authority to own. They have the responsibility without the power, which is the worst position in any organization. Real ownership requires that the owner's "no" is binding.
3. Time. Does the reviewer have enough time to actually review, given the volume? This is where the chapters connect. If production tripled and the reviewer's time did not, then the reviewer has one-third the time per artifact they used to, which means they are skimming, which means automation bias takes over, which means they approve plausible output without genuinely evaluating it. A reviewer drowning in volume is not in the loop. They are a bottleneck pretending to be a control, waving things through to keep the queue moving. Time per artifact is the quiet killer, because it degrades silently: nobody decides to review less carefully, the volume just makes it happen.
4. Incentive. Is the reviewer rewarded for catching problems, or for throughput? In most organizations, the reviewer is measured on velocity, on keeping things moving, on not being the bottleneck. That incentive structure punishes careful review. A reviewer whose performance metric is throughput will, rationally, review fast and shallow, because catching a problem slows them down and looks like obstruction while waving things through looks like productivity. If you reward throughput and call the result ownership, you have built an incentive to not own, and people respond to incentives.
5. Escalation. When the reviewer is unsure, is there a real path to someone who can decide, with enough time to use it? Ownership is not just yes or no; it is "I don't know, and here is who does." A reviewer with no escalation path, or one so slow and costly that using it is punished, will resolve their uncertainty by approving, because approving is the path of least resistance. Real ownership requires that "I'm not sure" is a legitimate, supported, blameless move with somewhere to go.
A human in the loop is real ownership only when all five conditions hold: context to judge, authority to refuse, time to evaluate, incentive to catch, and escalation when unsure. Strip any one and you have theater that looks like governance, and theater fails exactly when you need it, during the high-stakes case, because that is when time is shortest, pressure to ship is highest, and the gap between looking-reviewed and being-owned is widest.
A scorecard for your loops
Here is the artifact. Run it against every place in your organization where you have told yourself "there's a human in the loop." Score each condition honestly, 0 to 2.
| Condition | 0 (theater) | 1 (partial) | 2 (real) |
|---|---|---|---|
| Context | Reviewer can't evaluate the output | Can evaluate some of it | Fully understands the system and what good looks like |
| Authority | Can flag but not stop | Can stop but easily overruled | "No" is binding |
| Time | Skimming due to volume | Adequate time on most items | Genuine time per artifact, volume-matched |
| Incentive | Measured on throughput | Mixed signals | Rewarded for catching problems |
| Escalation | No real path | Path exists but costly/slow | Blameless, fast, supported |
Add it up. A loop scoring below roughly 7 out of 10 is not a control, it is a comfort. The dangerous loops are the ones scoring high on the easy conditions (context, escalation) and low on the silent ones (time, incentive), because they look governed on paper and fail in practice. Most "human in the loop" deployments I have audited score a 9 on context and a 1 on time and incentive, and the people who built them are genuinely surprised when the loop lets a disaster through, because they were looking at the conditions that were satisfied.
The fallacy is an ownership fallacy
Step back to the book's thesis. The reason "human in the loop" is so seductive is that it lets you claim ownership without paying for it. You get to tell the board, the regulator, the customer, that a human is responsible, while spending nothing on the conditions that would make that human actually able to be responsible. It is ownership as a checkbox, and the checkbox is cheap precisely because it does not buy the expensive thing.
This connects directly to the human-in-the-loop fallacy as a framework in this book: review without context, authority, time, incentive, and escalation is not ownership; it is the appearance of ownership purchased at a discount, and the discount is exactly the part that would have caught the disaster. The phrase "human in the loop" describes a position in a process. Ownership describes a relationship between a person and a consequence. Putting someone in the position does not create the relationship, and confusing the two is how organizations deploy AI into high-stakes workflows while sincerely believing they have controlled the risk.
I want to be precise about what I am not saying. I am not saying human review is useless, or that you should not have humans in your loops. You should. I am saying that the phrase has become a way to stop thinking, and that the work is not in placing the human, it is in funding the five conditions that let the human actually own. Those conditions cost money and time and org-design effort. A real review loop is more expensive than a fake one by exactly the amount that makes it real. When someone proposes a human in the loop and the budget does not increase, you have not bought a control. You have bought a story to tell after the incident.
Designing a loop that actually owns
Concretely, to build a loop that passes the five tests for a high-stakes, trap-zone workflow:
- Match reviewer context to artifact complexity. Do not put a junior on payments-path review. The reviewer's judgment span must exceed the artifact's complexity. This sometimes means fewer, more senior reviewers, which costs more and is the point.
- Make the reviewer's refusal binding and budget the consequence. If a reviewer says no, it ships when they say it ships, not when the deadline says. Build the schedule expecting some refusals, so a refusal does not trigger a pressure cascade.
- Cap volume per reviewer by time, not by queue. Decide how long real review of one of these artifacts takes, multiply by the volume, and that is your reviewer capacity. If production exceeds it, you throttle production (chapter on capacity) rather than thinning review. The loop's integrity is the constraint, not a variable.
- Reward catches, count them, make them visible. Measure problems caught in review as a first-class metric. A reviewer who catches a costly defect should look more productive than one who waved everything through, not less. Invert the throughput incentive deliberately.
- Build a fast, blameless escalation path and use it openly. Make "I escalated because I wasn't sure" a story you tell approvingly in reviews, so that uncertainty resolves upward to judgment rather than downward to approval.
A loop built this way is real ownership. It is also visibly more expensive than the checkbox version, and that expense is the signal that you are buying the actual thing. If you cannot afford the real loop for a given workflow, that is important information: it means that workflow may not belong in the trap zone at all, and you should reconsider letting AI operate there, rather than deploying a fake loop and hoping.
The relief in the design review when someone says "human in the loop" is the sound of a room deciding to stop thinking about ownership. The job of anyone who has actually owned an incident is to keep the room thinking: in the loop, with what context, what authority, what time, what incentive, what escalation? The answers are the difference between a control and a comfort, and you find out which one you built at the worst possible moment if you do not find out on purpose first.
Key Takeaways
- "Human in the loop" describes a position in a process; ownership describes a relationship between a person and a consequence. Placing the human does not create the relationship.
- Aviation human-factors research established the default failure mode: humans supervising usually-correct automation over-rely on it, degrade their own skill, and are poorly positioned to catch the rare error, and this afflicts experts as much as novices.
- Real ownership requires five conditions: context to judge, authority to refuse bindingly, time to evaluate against volume, incentive to catch rather than to wave through, and a fast blameless escalation path. Fail any one and it is theater.
- The dangerous loops score high on the visible conditions and low on the silent ones (time and incentive), so they look governed on paper and fail in the high-stakes case exactly when pressure is highest.
- A real loop is more expensive than a fake one by exactly the amount that makes it real. If you cannot afford the real loop for a workflow, that is a signal the workflow may not belong in the trap zone, not a license to deploy the fake one.