Capability Waste in Production AI
You are paying for intelligence your tasks never use; here is how to measure the waste before you decide what to do about it.

Research spine: this chapter stays grounded in DistilBERT result and FrugalGPT work, then applies that evidence to the operating judgment in the book. There is a number that almost no team has and almost every team should: the fraction of the model capability they pay for that their tasks actually require. Call it the utilization of intelligence. If you buy a 64-core server and run a single-threaded process on it, your finance team will eventually notice the idle 63 cores, because servers have utilization dashboards and people who watch them. When you call a frontier model to decide whether a sentence is positive or negative, you are running a single-threaded process on a 64-core machine, every request, forever, and nobody has a dashboard.
This chapter is about building that dashboard. Not metaphorically. I am going to give you a concrete audit you can run on an existing AI feature to estimate how much capability you are buying and not using, because the frontier-model reflex is invisible until you measure it, and once you measure it the conversation in the room changes from belief to arithmetic.
What capability waste actually is
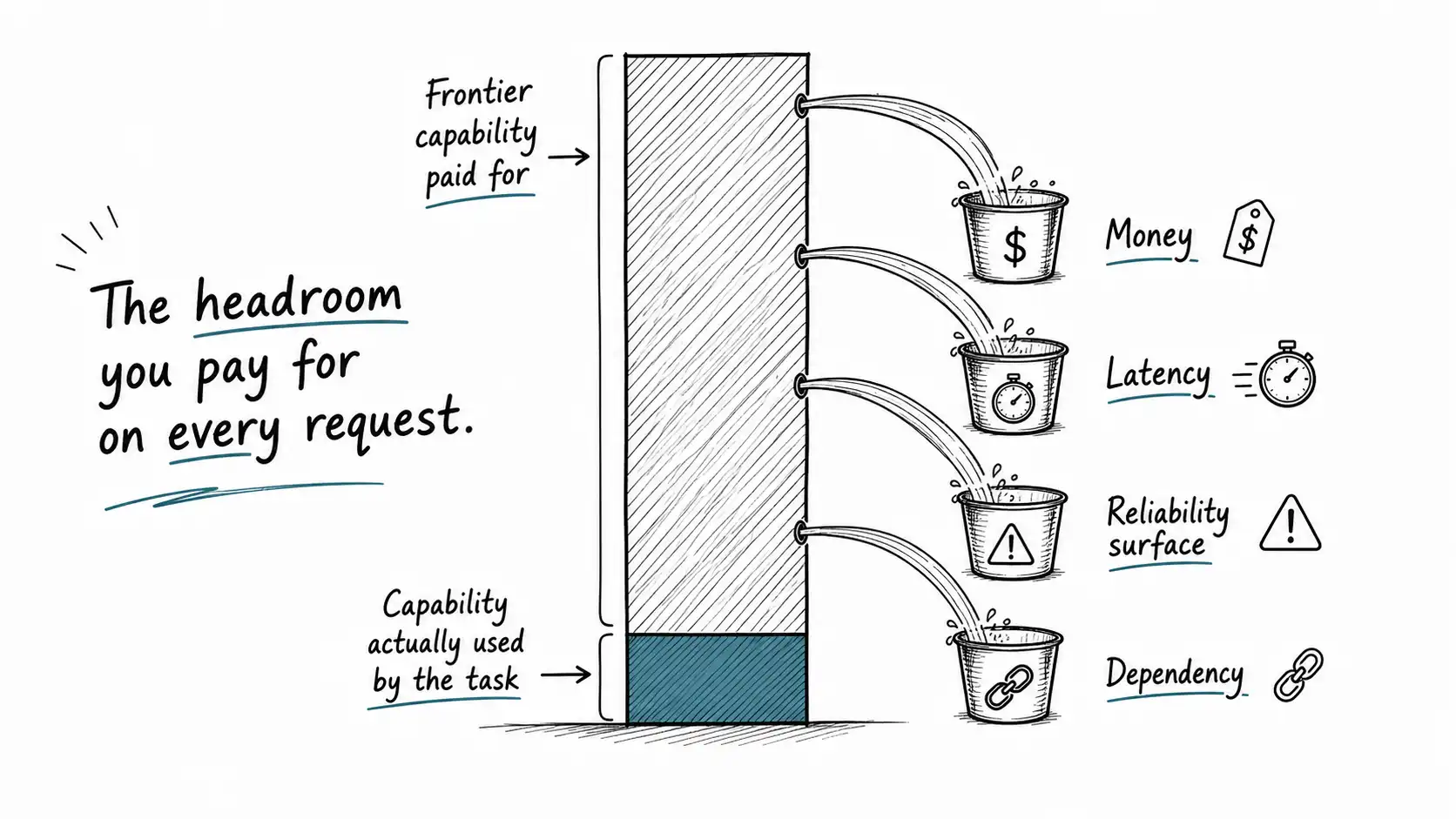
Capability waste is the gap between the difficulty of your task and the capability of the model you are using on it. A frontier model is built to handle the hardest, most open-ended, most ambiguous requests anyone might throw at it. When you point it at a task that is none of those things, you pay the full price of that headroom on every single request and capture none of the value.
The waste is not abstract - and What Small Actually Means establishes the vocabulary for measuring it. It shows up as four concrete leaks.
The first leak is money. You are paying a per-token price set by the capability of the model, on a task that a far cheaper model would handle. Multiply by volume and the gap is often the difference between a feature that is profitable and one that quietly bleeds.
The second leak is latency. Larger models are slower to generate, and many production tasks are latency-sensitive in ways the demo never surfaced. You are spending milliseconds buying intelligence the task does not need, and the user feels every one of them.
The third leak is reliability surface. A bigger, more general model has more ways to surprise you: more verbose, more prone to reinterpret a structured task as a conversation, more sensitive to prompt phrasing. Capability you are not using is still capability that can misfire. A narrow model that only knows how to emit one of nine labels cannot wander off and write you a poem about content policy.
The fourth leak is dependency. Every request to an external frontier API is a dependency on someone else's uptime, pricing, rate limits, and terms. Capability you did not need is dependency you did not need to take on.
The Capability Waste Audit
Here is the artifact. The Capability Waste Audit is a procedure you run per AI feature to estimate how much of the model you are using. It does not require new infrastructure, just a sample of real production traffic and an afternoon.
Step 1: Sample real requests. Pull a representative sample of actual production inputs to the feature, not the demo set. A few hundred is usually enough to see the shape. The demo set is biased toward the cases the model handles well; the production sample contains the long tail that decides whether a smaller model would survive.
Step 2: Characterize the task on five axes. For the sampled inputs, score the task itself, not the model:
- Output structure. Is the output a fixed label, a structured object, a number, or free-form text? Structured outputs are cheap to produce and cheap to verify.
- Input variety. Are inputs bounded and similar, or wildly varied? Bounded inputs are where small models thrive.
- Reasoning depth. Does the task require multi-step reasoning, or a single judgment? Single judgments rarely need a frontier model.
- Knowledge breadth. Does the task require broad world knowledge, or only domain-specific knowledge you could provide via context or fine-tuning?
- Ambiguity. What fraction of real inputs are genuinely ambiguous versus clearly decidable?
Step 3: Estimate the floor. Ask: what is the simplest thing that could plausibly handle the clear cases? Often it is a classifier, a rule, or a small fine-tuned model. The gap between that floor and the frontier model you are running is your capability waste, qualitatively.
Step 4: Quantify the unused headroom. Take your production sample and run it through a much smaller candidate model alongside the frontier model you use today. Measure agreement. If a small model agrees with the frontier model on, say, 92 percent of your real inputs, then you are paying frontier prices to handle the 8 percent the small model gets wrong, and the other 92 percent is pure waste that a cheaper model would have handled identically. That agreement rate is the single most useful number this audit produces, because it tells you both how much you are wasting and how much would need to escalate in a routed design.
Step 5: Compute the leaks. With the agreement rate and your real volume, you can put numbers on all four leaks: the money you would save on the agreed-upon fraction, the latency you would reclaim, the reduction in reliability surface, and the reduction in external dependency. Now the conversation is arithmetic.
A worked sketch, labeled as hypothetical to be honest about it. Suppose a support-ticket categorization feature handles 500,000 tickets a month on a frontier model. You sample 400 real tickets, characterize the task as structured output, bounded input, single judgment, domain knowledge, low ambiguity, and find a fine-tuned small classifier agrees with the frontier model on 94 percent of them. You are running a frontier model to do work a small classifier does identically 94 percent of the time. The 6 percent disagreement is where the value is, and even that probably does not all need the frontier, just review. The audit just told you that roughly 470,000 of your 500,000 monthly frontier calls are capability waste.
The Right-Sized Intelligence Ladder
The audit tells you there is waste. The next question is what to use instead, and the answer is rarely "a slightly smaller language model." It is "the lowest rung on the ladder that clears your quality bar." Here is the ladder, from cheapest and most reliable at the bottom to most capable and most expensive at the top.
- Rules. Deterministic logic, regular expressions, allowlists, denylists. If a rule handles it, a rule handles it forever, for free, with perfect explainability and zero drift. Do not be too proud to use a rule.
- Search and SQL. A lookup, a query, a database join. If the answer exists in your data, retrieving it beats generating it.
- Classical ML. Logistic regression, gradient-boosted trees, conditional random fields. Mature, fast, interpretable, and devastatingly effective on bounded tabular and text-classification tasks.
- Embeddings and reranking. Semantic search, clustering, deduplication, retrieval. The workhorse of finding and grouping.
- Small model. A small generative or instruction-following model for tasks that genuinely need flexible generation but at bounded scope.
- Fine-tuned small model. A small model adapted to your domain and task, which often closes most of the quality gap with the frontier on the specific thing you do.
- Frontier model. The most capable general model, reserved for genuinely hard, open-ended, or ambiguous requests.
- Human review. For the requests where being wrong is expensive and the machine is uncertain. The top of the ladder is a person, and a good system routes to them deliberately rather than failing silently.
The discipline is to start at the bottom and climb only as far as your quality bar forces you to. The frontier-model reflex starts at rung 7 and never looks down. Most teams could move a large fraction of their AI workload down two or three rungs and lose nothing the user would notice - which is the starting point for Making the Task Smaller.
Why the waste persists
If the waste is this measurable, why does it persist? Three reasons, all human.
First, the bill is shared and the win is local. The engineer who shipped the feature got credit for shipping. The cost shows up later on a different team's budget. The incentive structure rewards the demo and externalizes the leak.
Second, standardization feels like good architecture. "We use one model API for everything" is a clean sentence in a design review. It is also a recipe for running every task at the capability of the hardest task. Standardizing the interface is wise. Standardizing the model is expensive.
Third, measuring feels like distrust. Running the audit means admitting the original choice might have been wrong, which is socially awkward on a team that just shipped something. This is why I frame the audit as routine hygiene, like checking server utilization, rather than as a verdict on anyone's judgment. You did not do anything wrong by prototyping on the frontier. You would be doing something wrong by never checking.
What to do tomorrow
Pick your highest-volume AI feature, the one with the biggest bill or the most latency complaints, and run the Capability Waste Audit on a few hundred real requests this week. Get the agreement-rate number between your current model and one rung down the ladder. That single number will tell you more about your production economics than any vendor benchmark, because it is measured on your data, for your task, at your standard. Then decide, with arithmetic instead of belief, whether the waste is worth fixing. Often it is. Sometimes the volume is too low to bother and the frontier is genuinely the right call, which is a fine answer too, as long as you reached it by measuring rather than by reflex.
Key Takeaways
- Capability waste is the gap between your task's difficulty and your model's capability, paid in full on every request. It leaks money, latency, reliability surface, and dependency.
- The Capability Waste Audit measures it: sample real traffic, characterize the task on five axes, estimate the floor, and measure the agreement rate between your frontier model and one rung down the ladder.
- The agreement rate is the key number. If a small model agrees with your frontier model on 94 percent of real inputs, 94 percent of your frontier calls are waste and only the disagreements need escalation.
- The Right-Sized Intelligence Ladder runs from rules through search, classical ML, embeddings, small models, fine-tuned small models, frontier models, to human review. Start at the bottom and climb only when the quality bar forces you.
- The waste persists because the bill is shared while the win is local, because standardizing the model feels like good architecture, and because measuring feels like distrust. Treat the audit as routine hygiene, not a verdict.