What Small Actually Means
Smallness is not a parameter count; it is a property of cost, latency, memory, and control, and the families that have it look nothing alike.

If you ask three engineers what a "small model" is, you will get three answers and a fight. One will say it is anything under some parameter threshold, seven billion, three billion, pick your line. One will say it is anything you can run on a single consumer GPU. One will say it is anything that is not the frontier, which is a definition that defines nothing. They are all gesturing at something real and all of them are wrong, because they are measuring the model when the property that matters lives in the deployment.
Let me propose a definition that holds up in production. A model is small, for your purposes, when it fits inside your constraints with room to spare: it costs little enough per request that volume does not scare you, it returns fast enough that the product feels responsive, it fits in the memory you actually have, and it runs where you need it to run including, if required, inside your own walls. Smallness is relative to the job and the environment, not to a leaderboard. A 7-billion-parameter model is small on a server with an A100 and enormous on a phone. The number is context. The constraint is the thing.
Parameter count is the worst proxy
The instinct to rank models by parameter count is understandable and almost always misleading. Parameter count correlates loosely with capability and loosely with cost, but the correlation is loose enough that betting on it will burn you in both directions.
It misleads on capability because training quality and data quality move the frontier of what a given size can do. The whole Phi-4 technical report is an argument that a 14-billion-parameter model trained on carefully constructed synthetic and curated data can sit at the Pareto frontier of quality versus size, beating models several times larger on math and reasoning. The original Phi line made the same point at smaller sizes: a well-trained small model is not a scaled-down dumb model, it is a different point on the curve. Parameter count told you almost nothing about that.
It misleads on cost because cost is dominated by how you run the model, not just how big it is. The same model served with naive batching versus served on an engine like vLLM with PagedAttention, which reports 2 to 4 times higher throughput at the same latency by managing the key-value cache like an operating system manages memory pages, has wildly different economics for the identical weights. Quantize those weights to 4 bits and the memory footprint and bandwidth drop again. Two deployments of the same parameter count can differ in cost per request by an order of magnitude. Parameter count is the label on the box, not the price.
So I do not use parameter count as the definition. I use it as one input among several, and I weight it lightly.
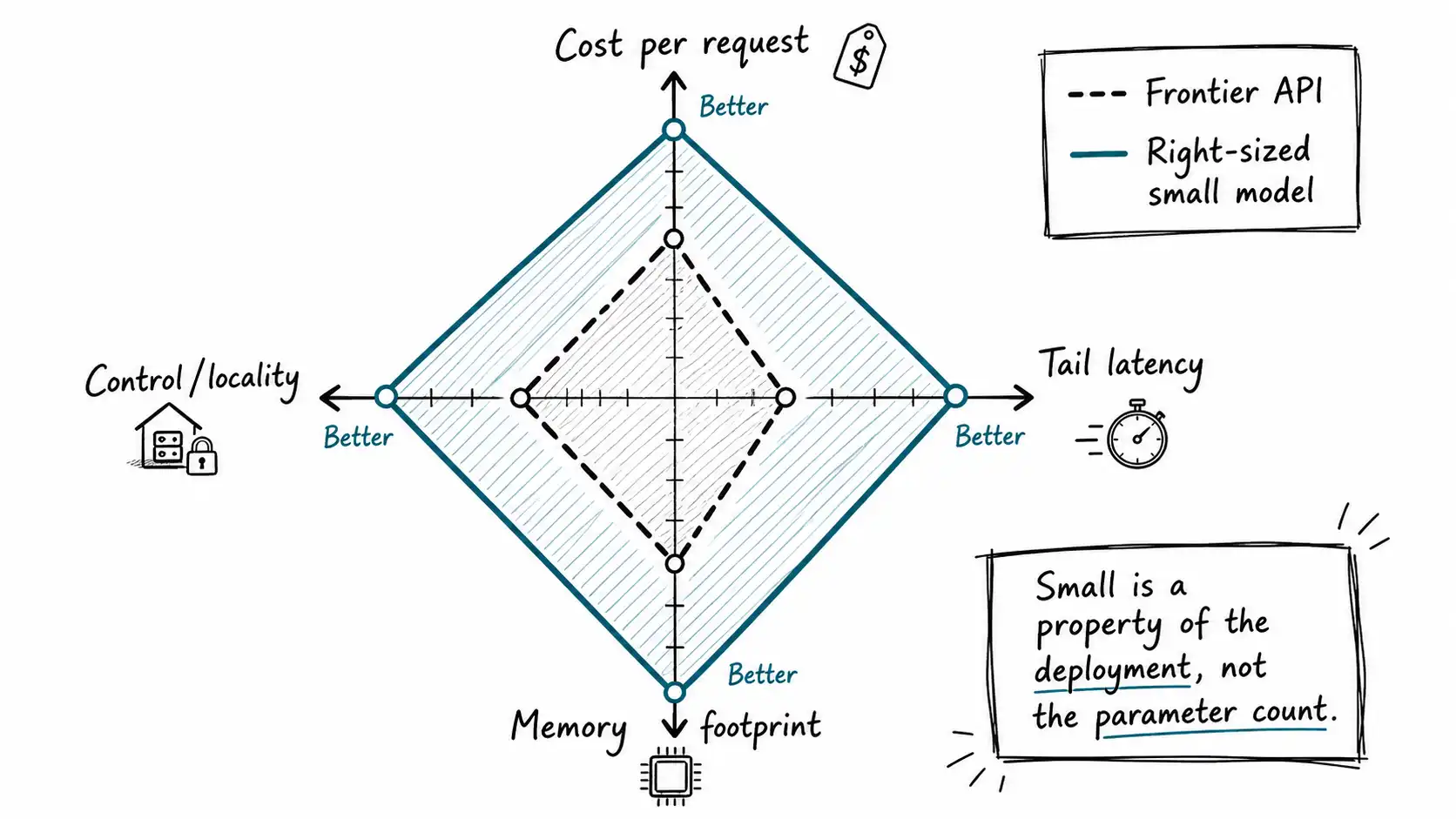
The four real dimensions of small
Here are the dimensions that actually decide whether a model is small enough to ship, the ones I make teams put numbers on before they argue about which model to use.
Cost per request. Not cost per token in the abstract, cost per request at your real input and output lengths, multiplied by your real volume, including the fixed cost of whatever you have to operate. A model is small on this axis when the monthly number does not make finance flinch.
Latency at the tail. Not the average, the tail. p95 and p99, because the average hides the requests that make users think your product is broken. A model is small on this axis when the slow requests are still fast enough for the experience you promised.
Memory footprint. How much memory the weights plus the key-value cache plus the runtime overhead consume on the hardware you have. This is the axis that decides whether the thing runs on a phone, in a browser, on a CPU, on one GPU, or only on a cluster. A model is small on this axis when it fits where you need it with headroom for concurrent requests.
Control and locality. Where the model can run and who can see the data flowing through it. A model is small on this axis when you can deploy it where your constraints require: on-device, on-premises, in your own cloud account, in a specific jurisdiction. A frontier API can be unbeatable on the first three axes and disqualified on this one by a single compliance requirement.
A model that wins on all four for your task is small for you. A model that loses on any one of them is not small enough, regardless of its parameter count, and the demo will not tell you which axis you are about to lose on. Capability Waste in Production AI gives you the audit to put a number on how far your current choices miss those axes.
Small is not a synonym for "language model"
The most expensive mistake in this whole area is assuming that the smaller version of a frontier chat model is the only kind of small. The frontier is a generative language model, so when teams downsize, they reach for a smaller generative language model. Often the right small thing is not a language model at all.
Consider the actual menu of small things that solve production tasks:
- Small language models. Generative models in the roughly 1-billion to 15-billion range, the Phi family, the smaller Llama and Mistral and Qwen and Gemma releases. Good for tasks that need generation or flexible instruction following but at bounded scope.
- Classifiers. Encoder models or even classical models that map an input to one of N labels. If your task is "which of nine policy categories," this is the natural shape, and a fine-tuned encoder will be smaller, faster, and more reliable than asking a generative model to emit a label.
- Embedding models. Models that turn text into vectors for semantic search, clustering, deduplication, and retrieval. Small, fast, and the backbone of any retrieval-augmented system.
- Rerankers. Cross-encoders that take a query and a candidate and score relevance. Small models that do enormous work in search quality, applied to a short candidate list rather than the whole corpus.
- Vision models. Detectors, classifiers, OCR, and segmentation models, many of which run comfortably on-device. A frontier multimodal model to read a receipt is the hammer-on-nail picture made literal.
- Classical ML. Logistic regression, gradient-boosted trees, conditional random fields. Decades of mature, fast, interpretable techniques that solve bounded tasks at a cost per request that rounds to zero.
The pioneering result here is old enough to be load-bearing. DistilBERT showed in 2019 that a distilled model could be 40 percent smaller and 60 percent faster while retaining 97 percent of the larger model's language understanding on GLUE. That was years before the frontier-model reflex took hold, and it already proved the core point: for a bounded task, a much smaller model gives up very little. The lesson did not change. The fashion did.
The SMALL framework
Here is the first reusable framework, and the one I reach for first in a model selection meeting. When a task is a candidate for a small system, run it through SMALL. The point is not the acronym, it is that each letter is a question that has to be answered with evidence, not vibes.
- S, Specific task. Is the task narrow and well-defined, or open-ended? Narrow tasks are where small wins. "Classify into nine categories" is specific. "Help the user with whatever they ask" is not.
- M, Measured quality. Do we have a way to measure whether a candidate model is good enough, on our data, before we ship? If you cannot measure quality, you cannot defend choosing a small model, and you will default to the frontier out of fear. Measurement is what makes the choice safe.
- A, Affordable inference. At our real volume and input sizes, does the cost per request times volume produce a number we are happy to pay, including the cost to operate whatever we run? Affordability is a function of volume, not a property of the model.
- L, Low latency. Does the task have a latency budget, and does the candidate meet it at the tail, not the average? A model that is fast on average and slow at p99 will still generate complaints.
- L, Local or control-friendly deployment. Do privacy, residency, offline, or control requirements demand that the model run somewhere a frontier API cannot? If yes, that constraint may decide the architecture before cost even enters the conversation.
SMALL is a filter, not a scorecard you total up. A task that is genuinely open-ended fails on S and you should not torture it into a small model regardless of how the other letters score. But a task that is specific, measurable, high-volume, and latency-sensitive lights up SMALL like a control panel, and those tasks are everywhere in real products: classification, extraction, routing, formatting, search, deduplication, tagging, ranking, simple structured generation. The frontier-model reflex paves over all of them with the same maximal model. SMALL is how you notice.
A worked example of the definition in action
Take the receipt-reading task I keep alluding to, because it makes the abstract concrete. A finance app needs to extract vendor, date, total, and tax from photographed receipts, millions per month, ideally fast enough that the user sees the parsed result before they put their phone away.
Run the four dimensions. Cost: at millions per month, a frontier multimodal call per receipt is a serious line item; a small on-device OCR plus a small extraction model is nearly free at the margin. Latency: on-device extraction returns before a network round-trip would even complete. Memory: modern phones run capable vision and small language models locally. Control: receipts contain financial data users may not want leaving their device, and keeping it local sidesteps an entire class of privacy work.
Run SMALL. Specific, yes, four fields. Measurable, yes, you have ground-truth receipts. Affordable, dramatically. Low latency, dramatically. Local, strongly preferred. Every signal points the same way, and a frontier multimodal model, which would absolutely ace the demo on five hand-picked receipts, is the wrong production choice on all four axes for this task.
That is what "small" means in this book. Not a number. A model that fits the constraints with room to spare, chosen from a toolbox that is wider than the frontier vendors would like you to remember.
Key Takeaways
- Smallness is a property of the deployment, not the model. A model is small when it fits your cost, latency, memory, and control constraints with room to spare. The same model can be small on a server and enormous on a phone.
- Parameter count is the worst proxy. Training quality moves capability for a given size, and serving choices move cost by an order of magnitude. Use it as a weak input, not a definition.
- The four real dimensions are cost per request at your volume, tail latency, memory footprint, and control/locality. A model that loses any one is not small enough, whatever its size.
- Small is not a synonym for "smaller language model." Classifiers, embedding models, rerankers, vision models, and classical ML are often the correct small thing, and DistilBERT proved years ago that bounded tasks lose almost nothing to a smaller model.
- The SMALL framework is a filter: Specific task, Measured quality, Affordable inference, Low latency, Local/control-friendly deployment. Specific and measurable are the gates; the rest tell you whether the win is large.