Privacy, Local Inference, and Data Residency
Sometimes the constraint that decides the whole architecture is not cost or speed but where the data is allowed to go.

A healthcare company I advised had built a clinical-note summarization feature on a frontier API, and it worked beautifully in the pilot. Then it went to the security and compliance review before general availability, and it died in that room in about fifteen minutes. The clinical notes contained protected health information. Sending that information to an external model provider, even one with a business associate agreement, created a data-flow that the compliance team was not willing to sign off on for their patient population and their jurisdiction. The feature was technically excellent and legally unshippable. No amount of quality could fix it, because the problem was not quality. The problem was that the data was not allowed to leave.
This is the axis that the frontier-model reflex ignores most completely, because the demo runs on test data nobody cares about, and the constraint only appears when real, sensitive data meets a real compliance requirement. For a large class of enterprise, healthcare, financial, and government workloads, where the data can go is not a preference, it is a hard constraint, and it can decide your entire architecture before cost or latency enters the conversation. When the data cannot leave, a small model you can run inside your own walls is not a cost optimization. It is the only model you are allowed to use.
The three forms of the constraint
The "data cannot leave" requirement shows up in three related but distinct forms, and it is worth separating them because they have different solutions.
Privacy. The data is sensitive (health records, financial details, personal communications, trade secrets) and sending it to a third party creates risk or violates policy, regardless of contracts. Even with a vendor's assurances, some organizations will not send certain data outside their control, and increasingly users expect that their most personal data stays on their own device.
Data residency. Regulation requires that certain data stay within a geographic boundary. The GDPR governs personal data of people in the EU and constrains transfers outside it. Various national laws require certain data to remain in-country. A frontier API that processes data in a different jurisdiction can violate residency requirements even if the vendor is trustworthy, because the issue is location, not trust.
Offline and air-gapped operation. Some environments have no reliable connectivity or are deliberately disconnected for security: a factory floor, a ship, a remote site, a classified network, a consumer device in airplane mode. A model that requires an API call simply does not work here. The model has to run locally because there is nothing to call.
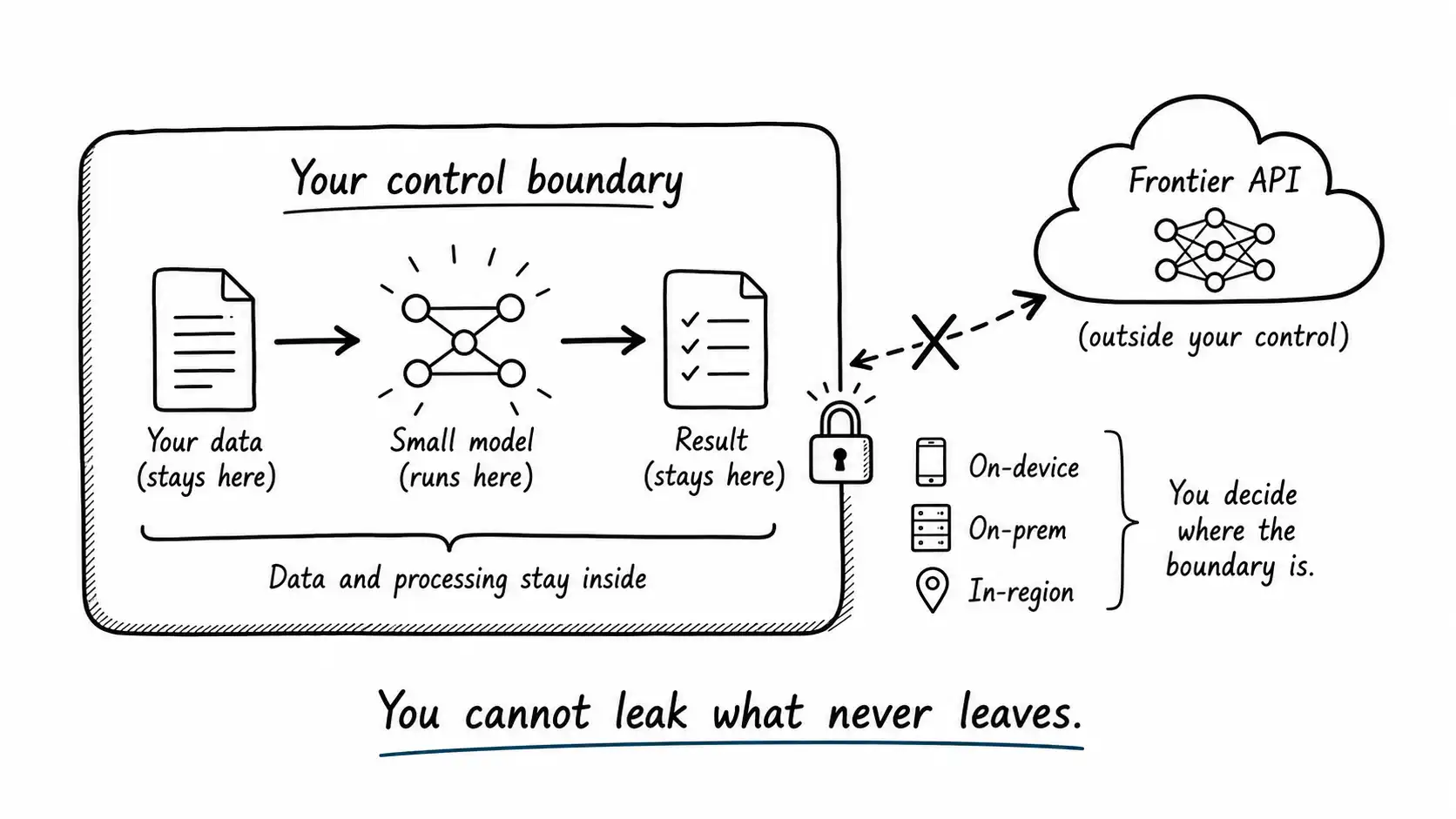
Notice that all three are independent of cost and quality. A frontier API could be cheaper and better and still be disqualified by any one of these. This is what makes the privacy axis categorically different from the others in this book: cost and latency are tradeoffs you optimize, but a hard residency or privacy constraint is a gate you pass or fail. Small, locally-runnable models are often the only thing on the right side of that gate.
On-device and edge inference
The technology to run capable models locally has matured to the point where this is a real option rather than a research demo, and that maturation is one of the most important developments for the small-model case.
On consumer devices, the platform inference stacks make local models practical. Apple's Core ML runs models on the device's neural engine, ONNX Runtime provides cross-platform on-device inference, TensorFlow Lite (LiteRT) targets mobile and embedded devices, and for the browser, WebGPU and WebNN are bringing accelerated model execution to web applications without a server round trip at all. These are not toys. They run real classifiers, real embedding models, real vision models, and increasingly real small language models, on hardware people already own.
On the server side, "local" means in your own infrastructure rather than a vendor's. A quantized small model served on your own GPUs, in your own cloud account, in a region you control, keeps the data inside your boundary while still giving you a capable model. The GGUF/llama.cpp ecosystem made this straightforward even on CPU, which matters because not every on-premises environment has GPUs.
The architectural payoffs of local inference go beyond compliance:
- The data never leaves, which collapses an entire category of privacy and residency work into a non-issue. You cannot leak what you never transmitted.
- No network round trip, which as Latency as a Product Feature showed can be the dominant latency component. Local is often faster precisely because it skips the network.
- No external dependency, so the feature works offline, survives the vendor's outages, and is immune to their rate limits and pricing changes.
- Predictable cost, because you are running your own hardware at a known cost rather than paying per token to someone else.
The hybrid pattern: keep sensitive data local, escalate the rest
Pure local inference is not always necessary, and pretending the choice is binary leads teams to either over-constrain everything or give up and send it all to the frontier. The sophisticated pattern is to split by sensitivity, not by task - a variant of the small-first cascade that routes on data-sensitivity rather than request difficulty.
The idea: process sensitive data locally with a small model, and only when you need the frontier's capability, send a redacted, abstracted, or non-sensitive version. Some concrete shapes of this:
- Local redaction, then escalate. A small local model identifies and strips personal information from the input, and only the redacted version goes to the frontier. The frontier never sees the sensitive parts. This works when the sensitive data is identifiable and removable without destroying the task.
- Local handling, selective escalation. The small local model handles the request entirely whenever it can, and escalates to the frontier only the cases it cannot handle, with explicit data-handling rules for what is allowed to leave in those cases. Most traffic stays local; only the hard, escalation-worthy minority involves the external call, and only if policy permits.
- Local feature extraction, remote reasoning. A local model turns sensitive raw data into non-sensitive features or embeddings, and the remote system reasons over those rather than the raw data. The raw data stays home; an abstraction travels.
The healthcare company from my opening rebuilt their feature on the second pattern. A small model running inside their own environment summarized the routine notes, which was the overwhelming majority, and the protected information never left. For the small fraction of genuinely complex cases, they built a careful, reviewed path with explicit de-identification before any external call, which the compliance team could actually evaluate because the data flow was now legible and bounded. The feature shipped. The version that died in the review room was not worse at summarizing. It was worse at respecting the boundary, and the boundary was non-negotiable.
The honest costs of going local
Local inference is not free, and the small-model-as-virtue crowd undersells the operational reality. Running models in your own environment means you own the operations: provisioning hardware or capacity, deploying and updating models, monitoring, scaling for peak load, and the on-call burden when it breaks at 3 a.m. A frontier API outsources all of that to the vendor, which is a real service you are paying for. When you go local, you take it back.
There is also a capability cost. The models you can run locally are smaller than the frontier, by definition, so on the genuinely hardest tasks they will be less capable. The hybrid pattern is partly a response to this: keep local what local can handle, escalate what needs more, and respect the boundary on the escalation path.
So the decision is not "local is more private therefore always local." The decision is: is there a hard privacy, residency, or offline constraint? If yes, local is not a tradeoff, it is a requirement, and you pay the operational cost because the alternative is not shipping. If no, then local is a regular cost/quality/operations tradeoff you evaluate like any other, and sometimes the frontier API's outsourced operations are worth the per-token price. The mistake is treating a hard constraint as a preference, or a preference as a hard constraint. Know which one you actually have.
What to do tomorrow
Before you design any AI feature that touches user or company data, ask the question that killed the healthcare pilot in the review room, and ask it first, not last: where is this data allowed to go? Get a real answer from whoever owns compliance, in writing, before you choose a model. If the answer is "it cannot leave our environment" or "it must stay in this jurisdiction" or "it must work offline," then your model menu is the set of things you can run locally, and you should design for that from the start rather than building on a frontier API and discovering the constraint in a review that ends your project. The constraint is cheaper to design around than to retrofit.
Key Takeaways
- Where the data can go is the axis the frontier-model reflex ignores most, and it can disqualify a better, cheaper model outright. It is a gate you pass or fail, not a tradeoff you optimize.
- The constraint comes in three forms: privacy (sensitive data should not go to third parties), residency (regulation requires a geographic boundary, as under GDPR), and offline/air-gapped operation (there is nothing to call).
- On-device and local inference is mature: Core ML, ONNX Runtime, TensorFlow Lite/LiteRT, WebGPU/WebNN on the client, and GGUF/llama.cpp plus your own GPUs on the server. The data never leaves, the network round trip disappears, and the external dependency is gone.
- The sophisticated pattern is to split by sensitivity, not task: handle sensitive data locally with a small model, and escalate only redacted, abstracted, or non-sensitive versions when frontier capability is genuinely needed.
- Local inference has real operational and capability costs you are taking back from the vendor. Pay them when the constraint is hard; treat it as a normal tradeoff when it is not. Know which you have, in writing, before you pick a model.