Adapting Small Models: Fine-Tuning and Distillation
How to teach a small model your domain cheaply, and how to compress a strong teacher into a student that ships.

A product manager once asked me why we could not just use the frontier model, since it already knew everything. The honest answer is that it knew everything except the one thing we needed: how our company does this specific task, in our specific format, with our specific edge cases. General knowledge is not the constraint in most production tasks. Domain behavior is. And domain behavior is exactly what you can teach a small model cheaply, which is how a small model goes from "almost good enough" to "better than the frontier on our task," because it learns the thing the frontier was never told - the same bounded, repeated tasks that The Workhorse Tasks: Classify, Extract, Route, Search shows are the steady state of production.
This chapter is about two ways to put that domain behavior into a small model. Fine-tuning teaches a small model by example. Distillation transfers behavior from a strong teacher into a small student. They are different tools for different situations, and the modern versions of both are cheap enough that the old objection, "we cannot afford to train models," is mostly obsolete.
Fine-tuning, and why it got cheap
Fine-tuning means continuing to train a pretrained model on examples of your specific task so it learns your format, your conventions, and your edge cases. The classic objection was cost: full fine-tuning updates every weight, which for a multi-billion-parameter model needs serious hardware and serious time. That objection died with parameter-efficient fine-tuning.
The pivotal technique is LoRA, Low-Rank Adaptation, which freezes the original model weights and trains a small number of additional low-rank matrices that adjust the model's behavior. You are not retraining the model, you are learning a small "diff" on top of it. The trained adapter is tiny, often a few megabytes, and you can keep many adapters for the same base model and swap them per task. This alone moved fine-tuning from a data-center project to something a small team can do.
QLoRA pushed it further by combining LoRA with 4-bit quantization of the frozen base weights. The QLoRA paper reported fine-tuning a 65-billion-parameter model on a single 48GB GPU while matching full 16-bit fine-tuning performance, using a 4-bit NormalFloat data type designed for the normal distribution of model weights, double quantization to shrink the quantization metadata, and paged optimizers to handle memory spikes. The practical consequence is blunt: you can fine-tune a capable small model on hardware you can rent by the hour for the price of a nice dinner. The economics of "teach a small model our task" changed completely, and most teams have not updated their assumptions.
When fine-tuning is the right move:
- The task is stable and you have, or can build, a few hundred to a few thousand good examples.
- You need the model to reliably follow your format and conventions, which prompting alone struggles to guarantee.
- You want the behavior baked in so you do not pay for long instruction prompts on every request. A fine-tuned model needs less prompting, which is itself a per-request cost saving.
- The domain has specific patterns the base model does not know but can learn from examples.
When fine-tuning is the wrong move:
- The task or categories change frequently, so the fine-tuned model is stale the moment you ship it. Prefer retrieval or prompting for fast-changing knowledge.
- You have too few examples to train on without overfitting to noise.
- The knowledge you need is factual and changing, in which case retrieval beats fine-tuning because you should not bake facts into weights you have to retrain to update.
That last point is the most common fine-tuning mistake. Teams try to fine-tune facts into a model, then have to retrain every time the facts change. Fine-tune behavior, retrieve facts. A model that has learned to write in your support voice and structure its answers your way, fed current facts via retrieval, beats a model with last quarter's facts frozen into its weights.
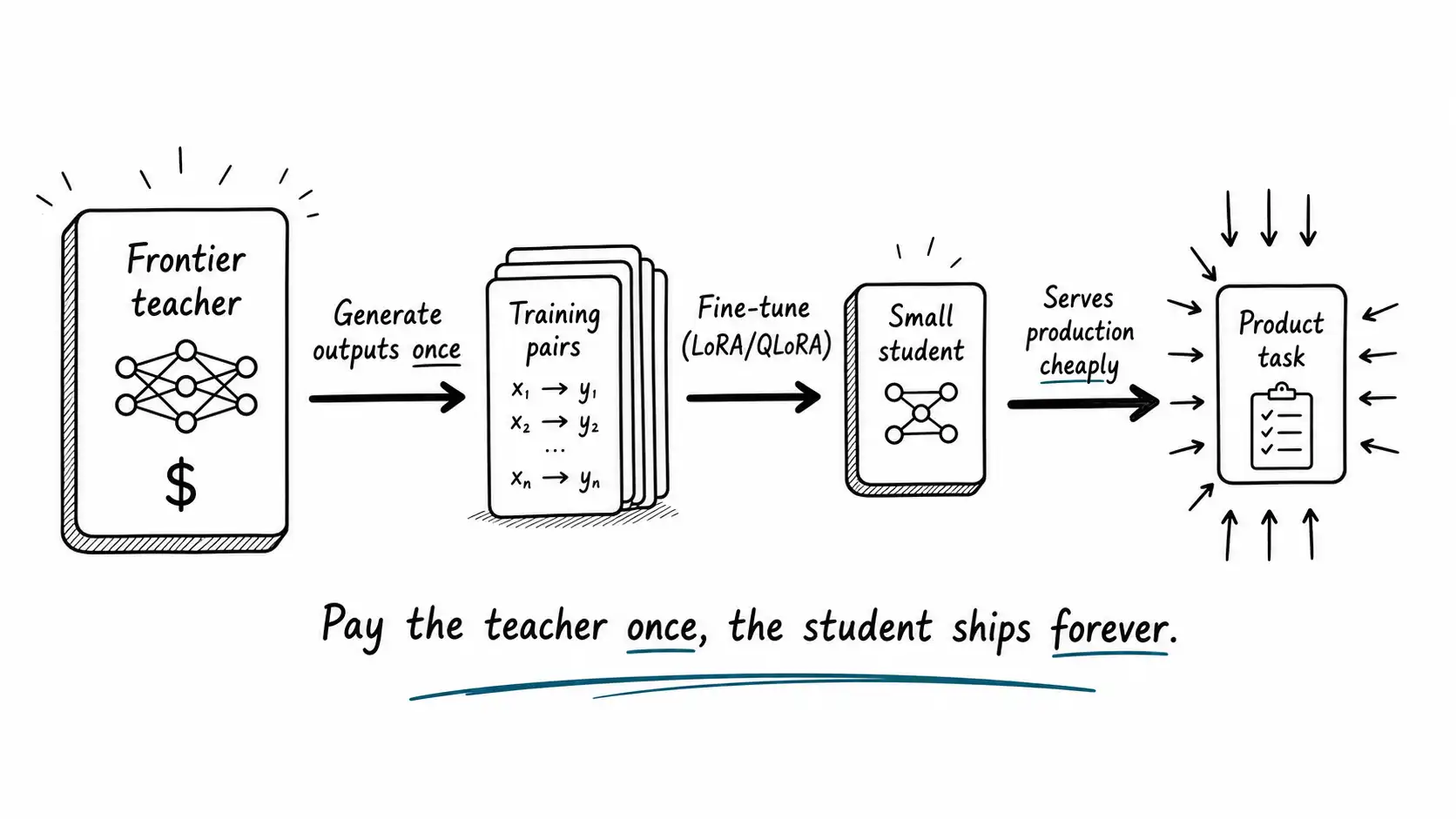
Distillation, the teacher-student transfer
Distillation is the other path, and it has a particularly elegant fit with the thesis of this book. The idea, introduced in Hinton, Vinyals, and Dean's 2015 paper, is to train a small student model to imitate a large teacher model, learning not just the teacher's final answers but the richer information in its full output distribution, the "soft targets" that encode how the teacher weighs alternatives. A student trained this way often reaches quality far beyond what it could learn from hard labels alone, because the teacher's distribution carries more information than a single correct answer.
The modern, practical version of distillation for production rarely involves the original soft-target mathematics. It involves using a strong teacher model, often a frontier model, to generate training data for a small student. You take your real inputs, run them through the frontier model to get high-quality outputs, and fine-tune a small model on those input-output pairs. The small model learns to imitate the frontier model on your specific task distribution. This is sometimes called sequence-level distillation or just "distilling from a teacher," and it is one of the most effective and underused techniques available.
This is exactly how the Phi family was partly built. The Phi-4 technical report describes strategically incorporating synthetic data, much of it generated with the help of stronger models, throughout training, and reports that Phi-4 actually surpasses its GPT-4 teacher on some STEM question-answering, which is evidence that good data generation and post-training go beyond naive imitation. You do not need to match Microsoft's research budget to use the same idea at task scale. The pattern is simple and the payoff is large.
A practical distillation pipeline for a production task:
# Step 1: Collect real production inputs (or a representative sample)
inputs = sample_production_inputs(n=5000)
# Step 2: Generate high-quality outputs with the frontier teacher
training_pairs = []
for x in inputs:
y = frontier_teacher.generate(task_prompt(x)) # expensive, but ONE TIME
if passes_quality_check(y): # filter bad teacher outputs
training_pairs.append((x, y))
# Step 3: Fine-tune the small student on the teacher's outputs (LoRA/QLoRA)
student = fine_tune(base_small_model, training_pairs)
# Step 4: Evaluate the student against the teacher on held-out inputs
agreement = evaluate_agreement(student, frontier_teacher, holdout_set)
# Ship only if agreement clears your quality barThe economics of this are the whole argument in miniature. You pay the expensive frontier model once, to generate a few thousand training examples. Then the small student handles production traffic at a fraction of the cost, forever. If you have a million requests a month, you have amortized one batch of a few thousand teacher calls over a million student calls, and the per-request cost collapses. The frontier model was the expensive teacher; the cheap student does the shipping. That is distillation working exactly as intended: the capability survives latency and cost because you moved it out of the per-request path and into a one-time training cost.
The decision: prompt, RAG, fine-tune, or distill
These techniques are not competitors so much as tools for different situations, and the most common mistake is reaching for the wrong one. Here is the decision tree I use.
| Situation | Right tool | Why |
|---|---|---|
| Behavior is hard to specify but easy to demonstrate, stable task | Fine-tune | Examples teach what instructions cannot |
| Knowledge is factual and changes often | RAG (retrieval) | Do not bake changing facts into weights |
| You can already get good outputs from a frontier model and need them cheaper at volume | Distill | Transfer the behavior to a cheap student |
| Task is one-off, low-volume, or still being defined | Prompt a capable model | Not worth the training investment yet |
| You need format guarantees | Fine-tune + constrained decoding | Bake in format, enforce it at decode |
Notice these combine. The strongest production pattern is often distill-then-retrieve: distill the behavior and reasoning style from a frontier teacher into a small student, then feed that student current facts via retrieval at request time. You get the teacher's competence on the task and current knowledge, in a small model you control. Fine-tuning handles the "how," retrieval handles the "what," and the frontier model's role shrinks to teaching once and handling the rare hard case.
The cost of adaptation, honestly
I would be selling you something if I pretended adaptation is free. It is not. Fine-tuning and distillation both create an asset you have to maintain. The fine-tuned model drifts as your inputs drift. The distilled student inherits the teacher's quality on the distribution you sampled, and if production drifts away from that distribution, the student degrades. You now own a training pipeline, an evaluation harness, and a retraining cadence. That is real ongoing engineering cost, and it is mostly people, not compute.
The right way to think about this is the same arithmetic the cost-model reasoning gives you: the one-time and ongoing cost of adaptation has to be justified by the per-request savings over your real volume. At low volume, do not adapt; prompt a capable model and spend the engineering time elsewhere. At high volume, adaptation pays for itself quickly, and the maintenance burden is the price of a margin you could not get any other way. The mistake is adapting because it is intellectually satisfying, at a volume where prompting was cheaper all-in. Adaptation is an investment, and investments need a return you have actually calculated - a calculation that Quantization and the Cost of Compression extends to the serving stack itself.
There is also a quality ceiling to respect. A small model fine-tuned or distilled for a task will, on the genuinely hard tail of that task, still fall short of the frontier. That is fine, because that is what escalation and human review are for. Adaptation makes the small model good enough on the common case; it does not make it the frontier. Expecting the latter is how teams get disappointed and abandon a perfectly good small model that was succeeding at its actual job.
What to do tomorrow
If you have a high-volume task where a frontier model already produces good outputs, you have a distillation opportunity sitting in your logs. Take a few thousand of those input-output pairs, fine-tune a small model on them with LoRA or QLoRA, and measure the student's agreement with the teacher on a held-out set. If the agreement clears your bar, you have just built a model that does most of your traffic at a fraction of the cost. If it does not clear the bar, you have learned cheaply that this task needs the frontier, which is also worth knowing. Either way you replaced a guess with a measurement, which is the whole posture this book is trying to teach.
Key Takeaways
- Domain behavior, not general knowledge, is the usual constraint in production tasks, and domain behavior is exactly what you can teach a small model cheaply.
- LoRA and QLoRA made fine-tuning affordable: QLoRA reported fine-tuning a 65B model on a single 48GB GPU at full-precision quality. The old "we cannot afford to train" objection is mostly obsolete.
- Fine-tune behavior, retrieve facts. Baking changing facts into weights forces constant retraining; fine-tuning teaches format and style while retrieval supplies current knowledge.
- Distillation transfers a strong teacher's behavior into a small student: pay the frontier teacher once to generate training data, then the cheap student ships forever. The Phi family was partly built this way.
- Adaptation is an investment with ongoing maintenance cost, justified by per-request savings at real volume, and it has a quality ceiling. Adapt at high volume, prompt at low volume, and let escalation handle the hard tail.