The Workhorse Tasks: Classify, Extract, Route, Search
The bulk of production AI is four boring jobs, and a small model or no model at all does each of them better than the frontier.

Strip away the chat interfaces and the agent demos, and most of the AI doing real work in production is doing one of four boring things: putting inputs into buckets, pulling structured data out of messy text, deciding where something should go next, and finding the relevant thing in a pile. Classification, extraction, routing, search. These are the workhorses, and they are exactly the tasks the frontier-model reflex overpays for most spectacularly, because they are bounded, repeated, measurable, and structured - exactly the properties that Making the Task Smaller exploits to shrink both the problem and the model. Every property that makes a task expensive on a frontier model is a property that makes it ideal for something smaller.
This chapter is a tour of those four jobs and the right-sized way to do each. It is the most hands-on chapter in the book, because these tasks are concrete and the right answers are knowable. If you only apply one chapter to your production system this quarter, apply this one, because these four jobs are probably 70 percent of what your AI features are actually doing.
Classification
Classification is the task of mapping an input to one of N labels. Sentiment, topic, policy category, priority, language, spam-or-not, intent. It is the most common production task and the one most absurdly over-served by frontier models.
The instinct is to prompt a large generative model: "Is this review positive, negative, or neutral? Answer with one word." It works, and it is the wrong tool. You are asking a model built to generate arbitrary text to instead generate one of three tokens, paying for the entire generative apparatus to constrain it to a three-way choice. A fine-tuned encoder classifier does the same job smaller, faster, more reliably, and at a cost per request that rounds to zero, and Adapting Small Models: Fine-Tuning and Distillation shows how to build one cheaply. The DistilBERT result, 40 percent smaller and 60 percent faster while keeping 97 percent of language understanding, was about exactly this class of task, and it has held up for years.
The decision rule for classification:
- If the categories are stable and you have labeled examples, fine-tune a small classifier. This is the gold standard: fast, cheap, reliable, and easy to monitor.
- If the categories change often or you have no labels yet, a small generative model with constrained output (force it to emit one of the valid labels) is a reasonable interim, and you collect labels as you go.
- If the input is tabular or has strong structured features, classical ML, a gradient-boosted tree or logistic regression, may beat any language model and run in microseconds.
- Reserve the frontier model for genuinely ambiguous inputs the small classifier flags as uncertain, which is a routing decision, covered later.
The reliability gain is worth dwelling on. A fine-tuned classifier with a fixed label space cannot return a label that does not exist. A generative model asked for a label can return "Positive!" with an exclamation mark, or "I'd say positive", or a paragraph explaining its reasoning, on the one request in a thousand where your prompt's grip slips. Constraining the output space is not just cheaper, it removes an entire failure mode.
Extraction
Extraction pulls structured data out of unstructured input: vendor and total from a receipt, entities from a contract, fields from an email, parameters from a natural-language command. The output is a known schema, which is the whole game.
The key move, from the previous chapter, is to constrain the output to that schema and enforce it. Schema-constrained or grammar-constrained decoding, supported by modern inference engines, lets you guarantee the model emits valid JSON matching your schema rather than hoping it does and parsing defensively. Once the output is guaranteed structured, the task is bounded enough that a small model handles it well, because the hard part of extraction is rarely deep reasoning, it is reading carefully and putting things in the right slots.
A realistic extraction pattern, in pseudocode, showing the shape rather than a specific library:
# Define the target schema once
schema = {
"vendor": "string",
"date": "date",
"total": "number",
"tax": "number",
}
def extract(document_text):
# Small fine-tuned or instruction-tuned model, constrained to the schema
result = small_model.generate(
prompt=build_extraction_prompt(document_text),
output_schema=schema, # enforced, not requested
max_tokens=128, # bounded output, bounded cost
)
# Validate against business rules, not just JSON validity
if result["total"] < result["tax"]:
return flag_for_review(document_text, reason="tax exceeds total")
return resultTwo things in that snippet do real work. The output_schema enforced at decode time means you never write defensive JSON parsing for a model that wandered off. The business-rule validation after extraction is the cheap, deterministic check that catches the model's mistakes without a second model call: tax cannot exceed total, dates cannot be in the future, totals must be positive. These rules are rung-1 logic doing quality control on rung-5 output, and they are how you make a small model's extraction trustworthy without escalating to a larger one.
Extraction also benefits enormously from input bounding. If you can locate the relevant region of a document first, with a layout model or even a regex anchor, and hand the small model only that region, the task shrinks further and accuracy rises. Reading one paragraph correctly is easier than reading ten pages and finding the right paragraph.
Routing
Routing is deciding where a request goes next: which team, which queue, which workflow, which downstream model. It is classification with consequences, and it is the connective tissue of any non-trivial AI system.
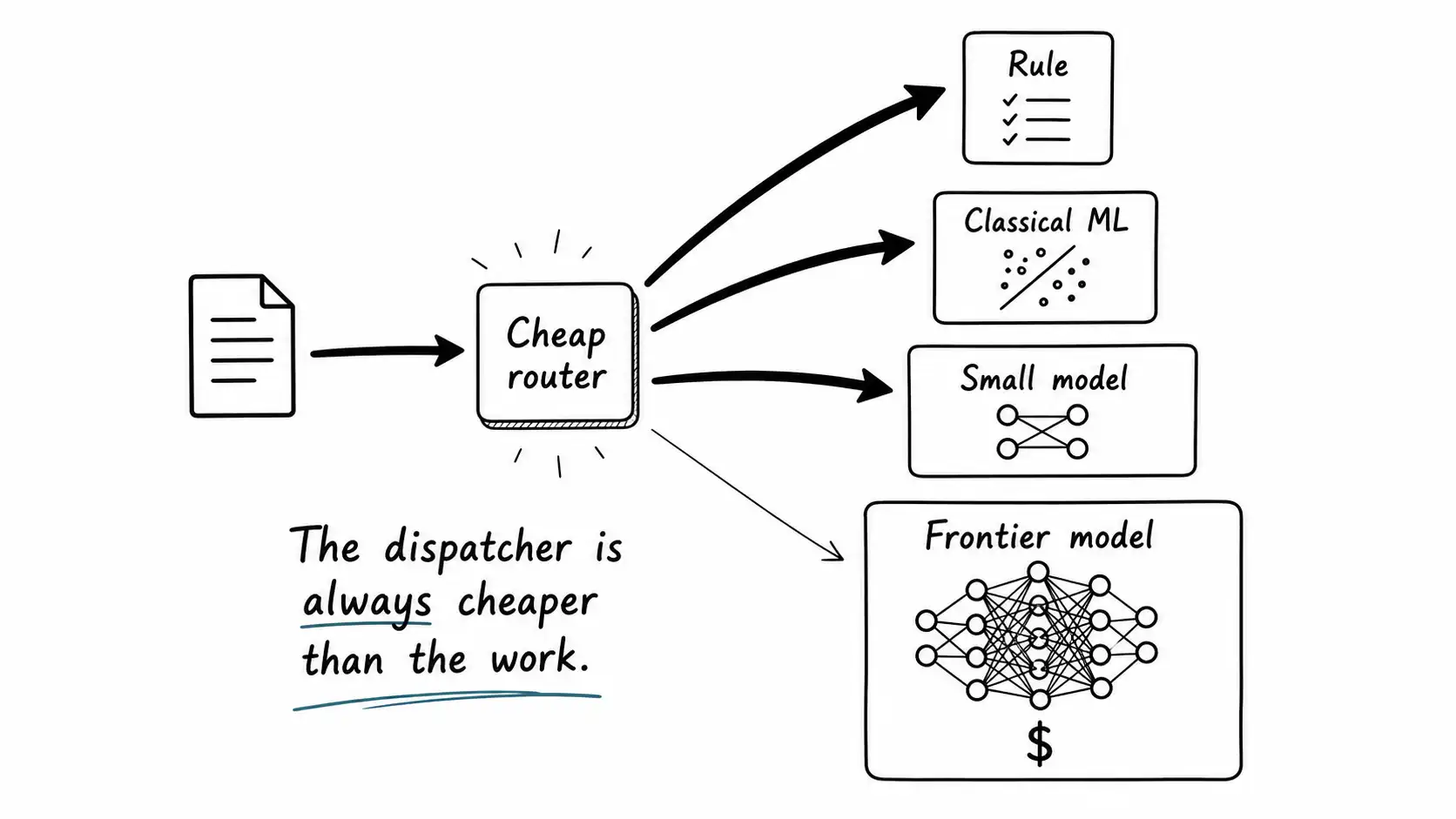
Routing deserves separate treatment because it has a property the others lack: the cost of the routing decision should be tiny relative to what it routes to. If you are using a frontier model to decide whether a request needs a frontier model, you have already lost, because you pay the expensive call to decide whether to make an expensive call. The router must be cheap, which means small. A small classifier or even a set of rules decides the route, and only the routed-to step incurs real cost.
This is the foundation of the small-first cascade that gets a full chapter later, but the principle starts here: the dispatcher is always cheaper than the work it dispatches. A good router is a small model or a rule that is right often enough, fast enough, and cheap enough that its decisions are nearly free, escalating only the genuinely hard cases upward. The FrugalGPT work formalized this as the LLM cascade and reported that learning which model to use for which query could cut inference cost by up to 98 percent while matching the best single model's performance. The router is what makes that saving possible, and the router is small by necessity.
Search
Search is finding the relevant thing in a pile: documents, products, code, support articles, prior tickets. It underpins retrieval-augmented generation, recommendations, deduplication, and any feature where the answer already exists and just needs to be found.
The frontier-model reflex here is to stuff everything into a giant context window and ask the model to find the relevant part, which is expensive, slow, and worse than the alternative. The right architecture is two small specialized models doing what they are built for:
- An embedding model turns every item in your corpus into a vector once, offline, and turns each query into a vector at request time. A nearest-neighbor search over the vectors retrieves candidates fast. Embedding models are small, cheap, and run anywhere.
- A reranker, a small cross-encoder, takes the query and each of the top candidates and scores relevance precisely. Rerankers are more expensive per comparison than embeddings, which is why you apply them only to a short candidate list, not the whole corpus. This two-stage pattern, cheap recall then precise reranking, is the standard production retrieval architecture for a reason: it puts the expensive model only where precision matters.
Neither stage needs a frontier model. A frontier model's job in a search-driven feature is to read the small set of retrieved, reranked passages and compose an answer, which is the read-and-write task it is good at, not the find-the-needle task that retrieval already solved more cheaply. When teams complain that their RAG system is slow and expensive, the cause is almost always that they skipped the retrieval architecture and are making the frontier model do the searching with a giant context, which is the most expensive possible way to do a job two small models do better.
The common thread
Look at all four jobs and the same pattern appears. Each is bounded. Each has a structured or constrained output. Each runs at volume. Each is measurable against ground truth. Each has a natural small-model or no-model solution that is faster, cheaper, and more reliable than a frontier model, with the frontier reserved for the genuinely hard subset that a cheap router identifies.
This is not a coincidence and it is not a limitation. It is the structure of production work. The open-ended, creative, ambiguous tasks that genuinely need the frontier are real but rare in the steady-state operation of most products. The steady state is classify, extract, route, search, over and over, millions of times, and that steady state is where your bill, your latency, and your reliability actually live. Win the workhorse tasks and you have won most of production. The frontier model can keep the hard cases. It was always overqualified for the rest.
What to do tomorrow
Inventory your AI features and tag each one as classify, extract, route, search, or other. I would bet most of them land in the first four. For each one currently running on a frontier model, identify the right-sized alternative from this chapter: a fine-tuned classifier, a schema-constrained small extractor, a cheap router plus selective escalation, or a two-stage retrieval pipeline. You do not have to migrate them all at once. Start with the highest-volume one, prove the agreement rate on real data, and ship the smaller version behind the same interface. Then do the next one.
Key Takeaways
- Most production AI is four boring jobs: classify, extract, route, search. Each is bounded, structured, high-volume, and measurable, which makes each ideal for a small model or no model at all.
- Classification: fine-tune a small classifier when categories are stable; it cannot emit an invalid label, which removes a failure mode that generative models keep.
- Extraction: enforce the output schema at decode time and validate with deterministic business rules. The hard part is careful reading, not reasoning, so a small model suffices.
- Routing: the dispatcher must be cheaper than the work it dispatches. A frontier model deciding whether to call a frontier model has already lost. This is the foundation of the cascade.
- Search: use a small embedding model for recall and a small reranker for precision, then let the frontier model only read the retrieved passages. Making the frontier do the searching with a giant context is the most expensive possible design.