Quantization and the Cost of Compression
How to shrink a model's footprint and bill without quietly shrinking its quality, and how to prove you did not.

The first time I watched a team quantize a model in production, they did it on a Friday, saw the memory usage drop by three quarters, declared victory, and shipped. The following Tuesday, support tickets about subtly wrong outputs started arriving, and it took two days to connect them to the quantization, because nobody had measured quality before and after. The model still worked. It was just a little worse in a way that did not show up until real users hit the inputs that lived near the edges of what the compressed weights could represent. The lesson was not "do not quantize." Quantization is one of the best tools you have. The lesson was that compression is a tradeoff you have to measure, not a free lunch you can assume.
This chapter is about making a model cheaper to run by compressing it, and about the discipline that keeps compression from quietly degrading you. Quantization is the headline technique, but it sits inside a broader story about why serving cost is mostly about memory bandwidth, and why the inference engine matters as much as the model.
Why inference is a memory problem
To understand quantization you have to understand what actually makes a model slow and expensive to run, and it is not what most people assume. For the autoregressive generation that dominates language model inference, the bottleneck is usually memory bandwidth, not raw compute. Generating each token requires reading the model's weights from memory, and for a large model those weights are large, so the GPU spends most of its time waiting for weights to arrive rather than doing arithmetic. The model is memory-bound.
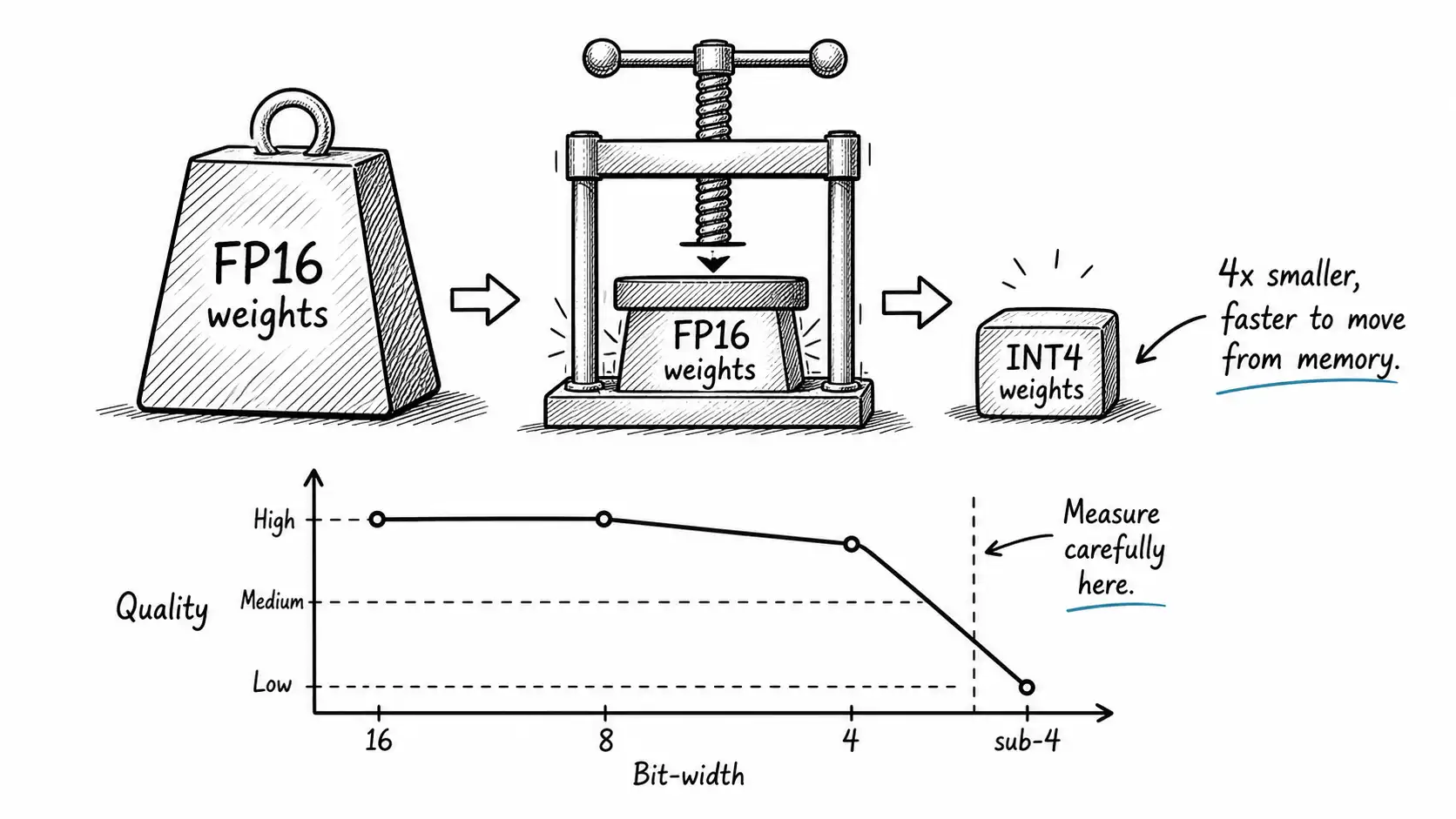
This is why quantization helps so directly. If you store the weights in 4 bits instead of 16, you have a quarter as much data to move per token, so generation speeds up and the model fits in less memory. You are not making the math faster, you are making the data smaller, and since the data movement was the bottleneck, the model runs faster and cheaper. It also fits on smaller, cheaper hardware, sometimes the difference between needing a data-center GPU and running on a consumer card or a CPU.
Quantization is the act of representing the model's numbers with fewer bits. A model trained in 16-bit precision can often be served in 8-bit or 4-bit with little quality loss, if you do it carefully. The "if you do it carefully" is the entire engineering problem, because naive rounding destroys quality and the careful methods are where the research lives.
The quantization toolkit
There are two broad families, and the distinction matters for what you actually do.
Post-training quantization takes an already-trained model and compresses it without further training. This is what most teams want, because it is cheap and fast. The art is in deciding how to round each weight to minimize the damage. Several methods are worth knowing by name:
- GPTQ quantizes weights layer by layer using approximate second-order (Hessian) information to decide how to round, minimizing the error introduced. It was the first method to push large models reliably to 4 bits while holding accuracy, and it remains a strong default for weight-only quantization, though the Hessian computation makes it slower to apply.
- AWQ, Activation-aware Weight Quantization, observes that not all weights matter equally; the ones that interact with large activations matter more. It scales the important weights before quantizing to protect them, and it is fast to apply with quality competitive with GPTQ.
- SmoothQuant targets the harder problem of quantizing activations as well as weights (W8A8) by migrating the quantization difficulty from activations, which have nasty outliers, to weights, which tolerate quantization better. It is the path to genuinely fast 8-bit inference where both weights and activations are low-precision.
A comprehensive 2024 study, "Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization, evaluated these methods across many tasks and found that well-configured quantization often preserves accuracy remarkably well, with the right choice depending on the model size, the bit width, and crucially the task. The headline I take from that body of work: 8-bit is nearly free in quality terms for most tasks, 4-bit is usually fine for many tasks but needs verification, and below 4-bit you are in territory where you must measure carefully because the losses become task-dependent and sometimes severe.
Quantization-aware training bakes the quantization into the training process so the model learns to be robust to it. It produces better low-bit models than post-training quantization but costs a training run, so it is reserved for cases where you need aggressive compression and can afford to train. For most production teams, post-training quantization is the right starting point and quantization-aware training is a later optimization if the cheaper path does not hold quality.
The practical stack
In practice, quantization rarely happens in isolation. It is one knob on an inference stack, and the stack as a whole determines your cost and latency. The pieces worth knowing:
- GGUF and llama.cpp popularized running quantized models efficiently on CPUs and consumer hardware, with a range of quantization levels you can dial. This is the backbone of much on-device and local-first inference.
- bitsandbytes provides accessible 8-bit and 4-bit quantization integrated with the common training stack, and it is what QLoRA builds on for its 4-bit base weights (the same QLoRA described in Adapting Small Models: Fine-Tuning and Distillation).
- vLLM is a serving engine whose PagedAttention manages the key-value cache like operating-system memory pages, reporting 2 to 4 times higher throughput than prior systems at the same latency - directly improving the tail-latency numbers that determine whether a feature feels fast. Throughput is cost: more requests per GPU per second is fewer GPUs per request.
- TensorRT-LLM and ONNX Runtime are production inference runtimes that combine quantization with kernel-level optimization for specific hardware, squeezing more out of the chips you have.
The point of listing these is not to recommend one. It is to make clear that "quantize the model" is shorthand for a stack decision, and that two teams running the same quantized model on different engines will see different cost and latency. When you report a model's economics, you are reporting the economics of a model-on-an-engine, not of the model alone.
A representative deployment config, showing the shape of the decisions rather than a specific tool's exact syntax:
# Inference deployment: a small model served cheaply
model:
base: small-instruct-7b
quantization:
method: awq # activation-aware weight quantization
bits: 4 # 4-bit weights
verified_against: bf16 # MUST have measured quality vs full precision
serving:
engine: vllm
max_batch_size: 64 # batching raises throughput, watch tail latency
kv_cache: paged # PagedAttention, near-zero KV waste
quality_gate:
eval_set: production_holdout_2000
metric: task_accuracy
min_acceptable: 0.94 # do not ship below this vs the bf16 baseline
drift_check: weeklyThe two lines that matter most are verified_against and quality_gate. They are not optional fields. They are the encoded version of the lesson from the opening of this chapter: you do not ship a quantized model without having measured its quality against the uncompressed baseline on your own data, and you do not stop measuring after launch.
Other compression: pruning and the diminishing returns
Quantization gets the headlines, but it has cousins. Pruning removes weights or whole structural units (neurons, attention heads, layers) that contribute little, producing a smaller, faster model. Structured pruning, which removes whole units, gives real speedups on standard hardware; unstructured pruning, which zeros individual weights, gives a sparse model that needs special hardware support to actually run faster, which is why it is less common in production. Pruning and quantization compose: you can prune then quantize.
The honest caveat across all compression is diminishing returns and stacking risk. Each technique trades a little quality for efficiency. Stack too many aggressively, prune hard then quantize to 3 bits then distill into something tiny, and the quality losses compound in ways that are hard to predict and that your demo set will not reveal. The discipline is to apply compression incrementally, measure after each step against the full-precision baseline on real data, and stop when you hit your quality floor rather than when you hit your size ambition. Compression is a series of measured tradeoffs, not a contest to see how small you can go.
When compression is the wrong move
To stay honest, compression is not always the answer, and the frontier-model reflex has a mirror-image vice: the compression reflex, shrinking everything because small is virtuous. Two cases where you should not compress.
First, if the model is already cheap enough at your volume, compression is engineering effort for no return. A small model serving low volume does not need 4-bit weights; you are optimizing a cost that does not hurt. Spend the time elsewhere.
Second, if you cannot measure quality, you cannot safely compress, because compression's whole risk is silent quality loss. The team in my opening story compressed without a quality baseline and got bitten precisely because they had no way to see the degradation. No eval, no quantization. The measurement is not overhead, it is the thing that makes the optimization safe.
What to do tomorrow
For your highest-cost served model, do a controlled quantization experiment this week. Take your full-precision model as the baseline, quantize to 8-bit and to 4-bit with a method like AWQ or GPTQ, and run all three against a held-out set of real production inputs with your actual task metric. You will almost certainly find that 8-bit costs you essentially nothing in quality while cutting memory and raising throughput, and you will learn precisely what 4-bit costs you on your task rather than guessing. Ship the most aggressive quantization that holds your quality bar, wire in the weekly drift check, and you have just cut your serving cost with a measurement instead of a hope.
Key Takeaways
- Autoregressive inference is usually memory-bandwidth bound, so quantization helps by shrinking the data moved per token, making the model faster, cheaper, and able to fit on smaller hardware.
- Post-training quantization (GPTQ, AWQ, SmoothQuant) compresses an existing model cheaply; quantization-aware training does better at low bit widths but costs a training run. Start with post-training.
- The rough rule from current research: 8-bit is nearly free in quality, 4-bit is usually fine but needs verification, sub-4-bit is task-dependent and must be measured carefully.
- "Quantize the model" is really a stack decision: the engine (vLLM, TensorRT-LLM, llama.cpp/GGUF, ONNX Runtime) and batching shape cost as much as the bit width. Report model-on-engine economics, not model alone.
- Never ship compression without a measured quality baseline and an ongoing drift check. Compression's whole risk is silent degradation, and the only defense is measurement on your own data.