Making the Task Smaller
The highest-use move is not picking a smaller model but shrinking the problem until a smaller model is obviously enough.

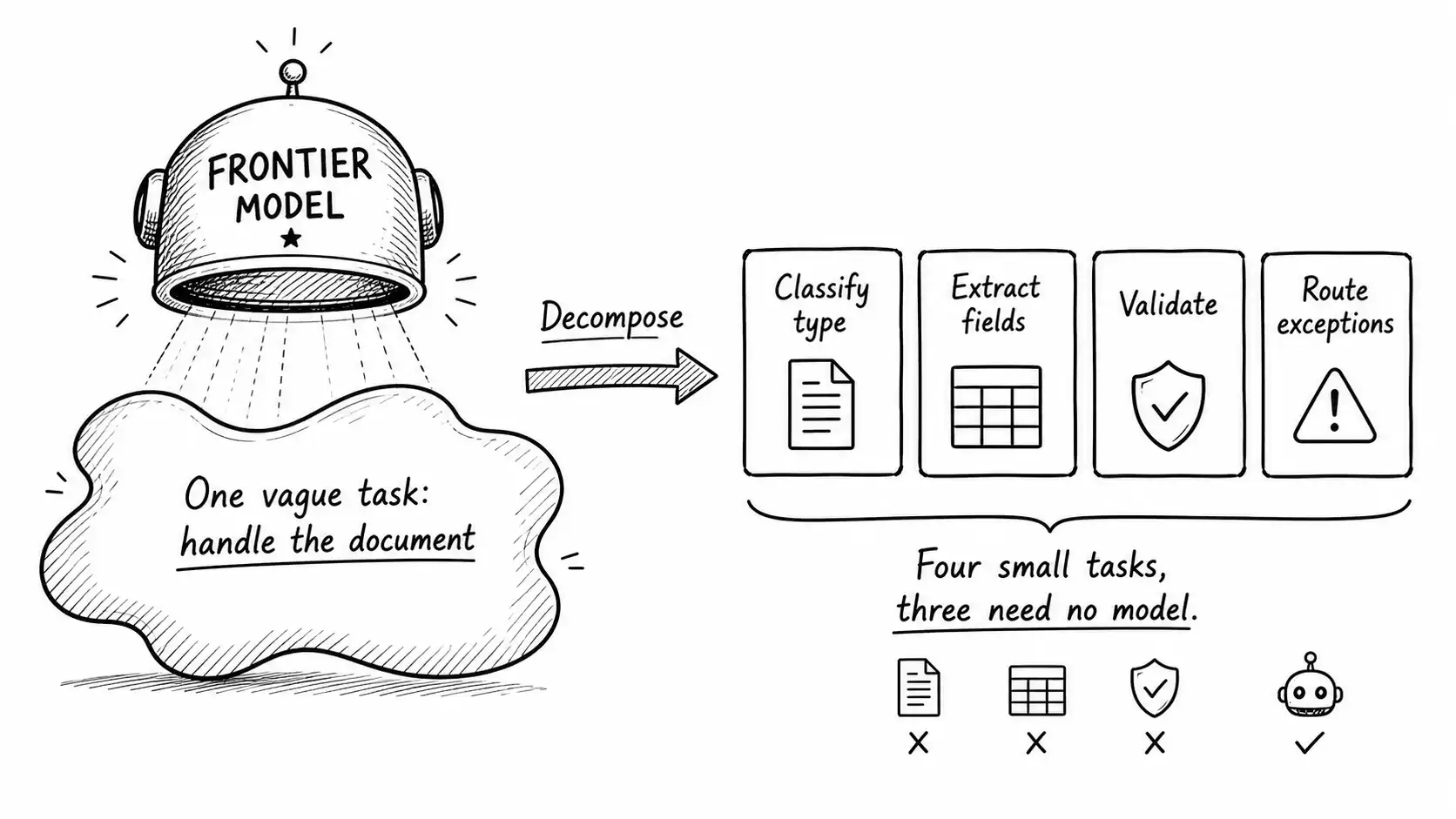
Research spine: this chapter stays grounded in DistilBERT result and FrugalGPT work, then applies that evidence to the operating judgment in the book. Before you choose a smaller model, ask a question that most teams skip: can I make the task smaller instead? This is the move with the highest use in the entire book, and it is the one nobody puts on a slide because it is unglamorous engineering rather than a model purchase. The Capability Waste Audit puts the first number on the problem; decomposition is what you do with it. A frontier model looks necessary right up until you decompose the task it was solving and discover it was four small tasks wearing a trench coat, three of which a rule could handle.
I learned this the hard way on a document-processing pipeline. The team had pointed a frontier model at incoming PDFs with the instruction "extract all relevant information." It worked in the demo, struggled in production, and cost a fortune. When we sat down and actually listed what "all relevant information" meant, it was: figure out the document type, then pull a known set of fields for that type, then validate the fields against business rules, then flag anything that looked off for review. That is not one open-ended task for a giant model. That is a classifier, an extractor, a validator, and a router - the four workhorse tasks that a small model handles better than the frontier - and only one of them, the extractor, might need a model at all.
Why task narrowing beats model shopping
A general model is general because the task it was handed was general. The frontier-model reflex and the vague-task reflex are the same disease. When you tell a model "handle the customer's request," you have guaranteed that you need a model capable of handling any request, which means the frontier, which means the bill. When you decompose "handle the customer's request" into detect intent, retrieve the relevant policy, draft a response in this format, and check it against these constraints, each piece becomes a bounded task, and bounded tasks fit on lower rungs of the intelligence ladder.
Task narrowing changes the economics before you have chosen a single model, because it changes which models are even candidates. A narrow, structured, bounded task is one that the Small Model Suitability Test passes, and the test is worth stating because it is the gate that decides whether the rest of the book applies to your problem at all.
The Small Model Suitability Test
A task is a strong candidate for a small system when it is:
- Narrow. It does one thing, not many. "Classify sentiment" is narrow. "Be helpful" is not.
- Repeated. It runs at volume. The economics of small models come from amortizing effort over many requests; a task you do twice a day is not worth optimizing.
- Measurable. You can tell whether an answer is right, ideally automatically. Without measurement you cannot prove a small model is good enough and you will default upward out of fear.
- Input-bounded. The space of inputs is constrained and predictable, not arbitrary. Receipts, support tickets, log lines, product titles: bounded. "Anything a user might type": not.
- Output-structured. The output is a label, a number, or a structured object rather than free-form prose. Structured outputs are cheap to produce, cheap to validate, and hard to wander away from.
- Latency-sensitive. Speed matters to the experience, which rewards a fast small model running close to the request.
- Cost-sensitive. Volume times per-request cost is a number someone cares about.
- Privacy-sensitive. The data benefits from staying under your control.
- Domain-specific. The knowledge required is narrow and yours, which fine-tuning or context can supply, rather than broad world knowledge only a frontier model has absorbed.
A task that hits most of these is begging to be made smaller. The trick is that task narrowing is what converts a task that fails the test into one that passes it. The original "extract all relevant information" failed on narrow, input-bounded, and output-structured. Decomposed, each sub-task passes all three.
The five narrowing moves
Task narrowing is not magic, it is a small set of repeatable moves. Here are the five I reach for, roughly in order of use.
Decompose. Break the task into a pipeline of bounded steps. This is the one I opened with, and it is the highest use because it often reveals that most of the steps are not model tasks at all. The discipline is to write out, in plain language, every distinct decision the system makes, then ask of each one: is this a rule, a lookup, a classification, or a genuine open-ended judgment? Most pipelines have exactly one or two steps in the last category.
Constrain the output. Force the model to emit a structured object rather than prose. The difference between "summarize this ticket" and "return a JSON object with category, urgency, and a one-line summary" is enormous. The structured version is bounded, validatable, cheaper to generate, and far harder for the model to drift on. A constrained output is a smaller task even on the same model, and it is often a small enough task to drop to a smaller model entirely. Grammar-constrained or schema-constrained decoding, supported by most modern inference stacks, makes this enforceable rather than hopeful.
Supply the knowledge. A frequent reason teams believe they need a frontier model is that the model needs to know something. But if the knowledge is yours, a small model with retrieval can beat a large model relying on its training. Retrieval-augmented generation turns "know everything about our product" into "read these three retrieved passages and answer," which a small model handles fine because the hard part, knowing, has been moved out of the model and into a search system. The model only has to read and write, not remember.
Bound the input. Pre-filter, normalize, and segment inputs before the model sees them. If you can route only the relevant section of a document to the extractor instead of the whole thing, the task shrinks. If you can normalize formats first, the model sees fewer variations and a smaller model suffices. Every variation you remove upstream is capability you do not have to buy downstream.
Cache the repeats. A surprising fraction of production "tasks" are the same input over and over. Caching exact and near-duplicate requests removes them from the model entirely. This is not narrowing in the strict sense, but it shrinks the volume of genuine model work, which has the same economic effect and is the cheapest optimization available.
A worked decomposition
Let me make this concrete with a realistic, labeled-hypothetical example: a B2B SaaS company routing inbound sales emails. The original design pointed a frontier model at each email with "decide what to do with this." It demoed beautifully and cost too much, the familiar story.
Here is the decomposed pipeline:
| Step | Decision | Right rung | Why |
|---|---|---|---|
| 1 | Is this spam or automated? | Rule + classical classifier | Bounded, high-volume, cheap, and spam patterns are well understood |
| 2 | Is the sender an existing customer? | SQL lookup | The answer is in the CRM; do not generate it |
| 3 | What is the intent: demo, pricing, support, partnership, other? | Fine-tuned small classifier | Five bounded labels, measurable, high volume |
| 4 | Extract company name, size signal, and any stated need | Small model with structured output | Bounded extraction into a known schema |
| 5 | Is this a high-value, ambiguous lead worth a tailored response? | Frontier model, only for the small flagged subset | Genuinely open-ended, low volume, high stakes |
| 6 | Draft the routing decision and assign | Rule on the structured fields | The fields now make the decision deterministic |
Five of the six steps sit at or below the small-model rung, and the one frontier call is reserved for a small, high-value subset where its capability actually earns its cost. The original single frontier call per email was doing all six steps at once, paying frontier prices for the spam check. The decomposition did not just save money; it made every step independently testable, debuggable, and replaceable, which is its own enormous operational win. When step 3 misbehaves, you fix the classifier. When the single giant prompt misbehaved, you had nowhere to look.
The objection and the answer
The standard objection to decomposition is that it is more code to build and maintain than one model call, and that is true. A single prompt to a frontier model is genuinely less work to ship on Friday. The decomposed pipeline is more components, more glue, more tests.
The answer is that you are trading one-time engineering cost for per-request operating cost, and per-request costs compound. At low volume the single frontier call is the right call and you should not over-engineer, which is consistent with the cost-model logic that volume is the deciding variable. At high volume, the decomposition pays for itself quickly and then keeps paying, while also giving you a system you can reason about. The mistake is not choosing the frontier call. The mistake is choosing it by default at high volume because decomposition felt like too much work, without ever doing the arithmetic on what the default costs over a year.
The deeper point is that decomposition is good engineering independent of model choice. A system made of bounded, testable, replaceable components is more maintainable, more debuggable, and more resilient than a monolith that hands everything to one opaque model. The fact that it also lets you use smaller, cheaper models is almost a bonus. You were going to want the modular system anyway. The frontier-model reflex talked you out of building it.
What to do tomorrow
Take your most expensive or most fragile AI feature and write out, in plain English, every distinct decision it makes. Be honest and granular. Then label each decision as rule, lookup, classification, extraction, or open-ended judgment. Count how many fall in the last bucket. For almost every feature I have audited, the answer is one or two, and the rest were being handled by a frontier model purely because nobody had bothered to separate them out. That list is your decomposition plan, and it is the highest-use page you will write this quarter.
Key Takeaways
- The highest-use move is making the task smaller, not picking a smaller model. A general model is general because the task was vague; decompose the task and the model can shrink.
- The Small Model Suitability Test gates everything: narrow, repeated, measurable, input-bounded, output-structured, latency-sensitive, cost-sensitive, privacy-sensitive, domain-specific. Narrowing converts failing tasks into passing ones.
- The five narrowing moves are decompose, constrain the output, supply the knowledge via retrieval, bound the input, and cache the repeats. Decomposition has the highest use because it reveals how few steps actually need a model.
- A decomposed pipeline is more code but trades one-time engineering cost for compounding per-request savings, and it gives you a system you can test, debug, and replace component by component.
- Decomposition is good engineering regardless of model choice. The modular system is the one you wanted anyway; the frontier-model reflex talked you out of building it.