Conclusion: A Sign of Maturity, Not a Lack of Ambition
Building a right-sized model portfolio, the production checklist, and why choosing the smallest sufficient system is the senior move.

Research spine: this chapter stays grounded in DistilBERT result and FrugalGPT work, then applies that evidence to the operating judgment in the book. There is a moment in an engineer's career when they stop reaching for the most powerful tool by default and start reaching for the most appropriate one. It is the same moment a chef stops using the biggest knife for every cut, a carpenter stops using the most expensive saw for every board, a developer stops importing a framework to do what ten lines would do. It looks, from the outside, like a loss of ambition. It is the opposite. It is the arrival of judgment, the point where you know the tools well enough to match them to the job instead of impressing yourself with the biggest one in the drawer. Choosing a small model where a small model fits is that moment, applied to AI. It is not settling. It is knowing what you are doing.
The frontier-model reflex feels like ambition. Reach for the most capable model, ship the most impressive demo, never be the person who chose the weaker tool. But ambition that ignores cost, latency, privacy, and reliability is not ambition, it is the absence of engineering. Anyone can call the biggest API. The skill, the thing that separates a team that ships a sustainable product from a team that ships an impressive demo and a frightening bill, is knowing the smallest system that solves the task reliably inside the constraints, and having the discipline to build it.
The portfolio, not the model
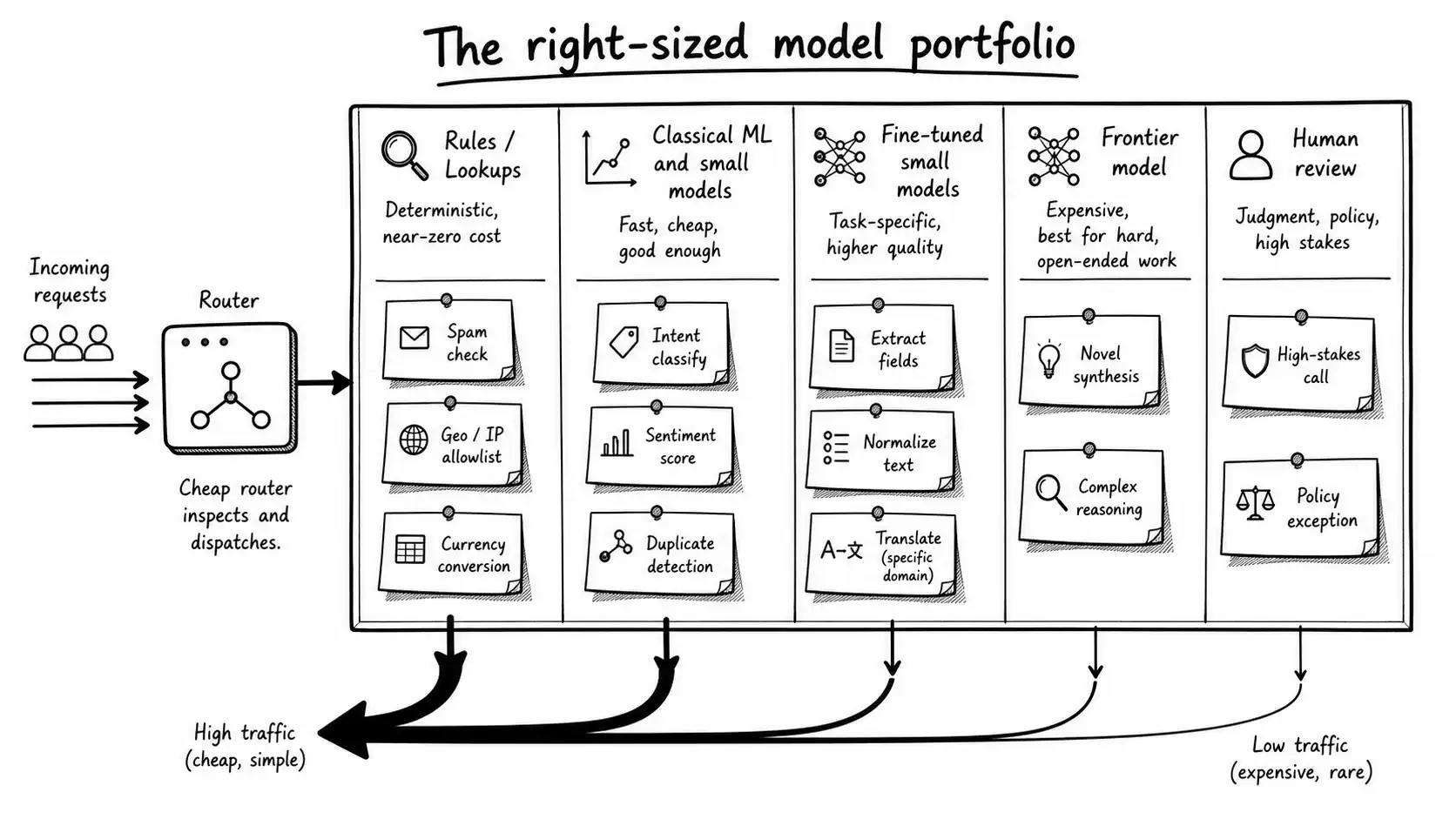
If there is one structural idea to carry out of this book, it is that you are not choosing a model, you are building a portfolio. A mature production AI system is not one model. It is a board of handlers, each matched to the work it does best, with traffic routed among them by cost and difficulty.
Picture the board. At the bottom, rules and lookups handle the deterministic cases for free. Classical ML and small fine-tuned models handle the high-volume bounded tasks cheaply and fast, inside your own walls where privacy demands it. The frontier model sits at the top, reserved for the genuinely hard, open-ended, ambiguous, low-volume work where its capability actually earns its cost, reached only through a cheap router that recognizes those cases. And above even the frontier, a human, for the decisions where being wrong is expensive and the machine is uncertain. Each handler does the work it is right for. The router and the evals are the connective tissue that keep the right work flowing to the right place.
This portfolio view dissolves the false fight the whole book has been arguing against. Small versus frontier was never the question. The question was always: for this specific request, at this volume, with these constraints, what is the smallest sufficient handler? Answer that request by request, with measurement, and you have a system that is cheaper, faster, more private, and more reliable than the one the frontier-model reflex would have built, without being any less capable on the work that actually needs capability.
The Small Model Production Checklist
Here is the artifact to take to your next design review, the operational summary of everything in this book. Run a candidate AI feature through it before you commit to a model.
Task definition
- Have we decomposed the task into bounded steps, and identified which steps need a model at all?
- For each model step, does it pass the Small Model Suitability Test (narrow, repeated, measurable, input-bounded, output-structured)?
- Have we run the Small Model Suitability Test's SMALL filter: Specific, Measured, Affordable, Low latency, Local/control-friendly?
Measurement
- Do we have an eval set drawn from real production inputs, including the long tail, with trusted held-out labels?
- Have we defined what "correct" means, the quality threshold, and the cost of each error type?
- Have we measured candidate models on accuracy, error types, p99 latency, cost per request, and agreement with our frontier baseline?
Economics
- Have we run the Capability Waste Audit on any frontier-model feature, and do we know the agreement rate one rung down the ladder?
- At our real volume, does the per-request cost times volume justify any engineering investment in a smaller solution?
- Have we costed the operations honestly, including the people, not just the compute?
Latency
- Have we written a latency budget from the experience backward, with allocations by component?
- Are we measuring p99, not the average, and does the worst-case path through any cascade fit the budget?
Privacy and control
- Do we know, in writing, where this data is allowed to go (privacy, residency, offline)?
- If there is a hard constraint, is our model menu restricted to what we can run locally?
Architecture
- If we use a cascade, have we tuned the escalation threshold against a quality-versus-cost curve and measured the tier-hit distribution?
- Do we have verifiers, calibrated confidence, an escalation path, and a human-review route for the cases the small model should not decide?
Operations
- Do we have drift monitoring to catch silent degradation as inputs move away from the training distribution? (The failure modes that make this essential are catalogued in When Small Models Are Wrong.)
- Do we have a quality gate that blocks shipping any model, quantized or otherwise, below the measured baseline?
- Do we have a retraining and re-evaluation cadence, and a plan to re-run the economics when frontier pricing changes?
If you can check these boxes, you have made the model decision on evidence, and you can defend it in any room, against either reflex.
What changed since the demo
Come back to where the book started, with the team that won the moderation demo on a Friday and lost the margin by Tuesday. What they lacked was not capability, they had too much of that. What they lacked was the discipline to ask the four questions the demo never asks: what does this cost per request at our volume, what is the latency at p95, where does the data go, and what happens on the inputs we did not test.
Those four questions are the whole book compressed into a habit. Ask them every time, before the demo becomes an architecture, and the frontier-model reflex never gets to make the decision for you. You will sometimes still choose the frontier, and that will be the right call, made for reasons you can defend rather than by default. More often you will find a smaller system that fits the constraints with room to spare, and you will ship something sustainable instead of something impressive-then-expensive.
The recurring motif of this book has been a single sentence: capability is only valuable after it survives latency, cost, privacy, and reliability. The frontier model has the capability. Whether that capability survives contact with your production constraints is a separate question, and it is the only question that matters once the demo is over. A model that cannot survive your latency budget, your cost model, your privacy posture, or your reliability target is not a capability you have. It is a liability that demos well.
The senior move
I will end where the prompt asked me to, with the claim that small models are a sign of engineering maturity, not a lack of ambition, because I believe it and because the industry's incentives push hard against it. Vendors want you to use the biggest model, because the biggest model bills the most. The demo culture rewards capability you can show in a room. The path of least resistance is to standardize on one maximal API and never look down the ladder. All of that pressure points toward the frontier-model reflex, which is exactly why resisting it is the senior move, the one that takes judgment and earns its keep.
The engineers I respect most are not the ones who can wire up the most powerful model. That is the easy part now; the API is three lines. The ones I respect are the ones who can look at a task, decompose it, measure it, find the smallest system that solves it reliably inside the constraints, and ship something that is still profitable and fast and private at a million requests a day. That is harder, less glamorous, and far more valuable. It is also, not coincidentally, what good engineering has always looked like in every other discipline: the right tool for the job, chosen by someone who understood the job.
Build the portfolio. Run the checklist. Ask the four questions before the demo turns into an architecture. And the next time someone in a room says "this is basically solved" after a clean demo on the biggest model, be the person who asks what it costs, how fast it is, where the data goes, and what happens on the inputs nobody tested. That person is not the skeptic slowing things down. That person is the engineer keeping the product alive.
Key Takeaways
- You are not choosing a model, you are building a portfolio: rules and lookups, classical ML and small models, fine-tuned small models, the frontier for the hard tail, and humans above it, with routing and evals as connective tissue.
- The Small Model Production Checklist turns the book into a design-review artifact spanning task definition, measurement, economics, latency, privacy, architecture, and operations.
- The four questions the demo never asks: cost per request at volume, p95 latency, where the data goes, and what happens on untested inputs. Asking them before the demo becomes an architecture defeats the frontier-model reflex.
- Capability is only valuable after it survives latency, cost, privacy, and reliability. A model that cannot survive your constraints is a liability that demos well, not a capability you have.
- Choosing the smallest sufficient system is the senior move. It takes the judgment the demo culture and vendor incentives push against, and it is what good engineering has always looked like: the right tool, chosen by someone who understood the job.