Routing: Small First, Large When Needed
The mature architecture is not one model but a cascade that handles the easy majority cheaply and escalates only what earns it.

The false choice that wastes the most money in production AI is "small model or frontier model." Teams treat it as a single, permanent decision: pick the small one and accept worse quality on hard cases, or pick the frontier and accept the cost and latency on every case. Both options are wrong because the premise is wrong. You do not have to pick one model for all requests. You can pick the right model per request, and since most requests are easy and a few are hard, the right architecture handles the easy majority with something cheap and escalates only the hard minority to something expensive. This is the cascade, and it is the closest thing this book has to a universal recommendation.
The intuition is the same one any well-run support organization already uses. Tier-one support handles the common cases quickly and cheaply. They escalate to tier two only what they cannot resolve, and tier two escalates to engineering only what they cannot resolve. Nobody routes every support ticket directly to a senior engineer, because it would be slow, expensive, and a waste of the engineer. A model cascade is exactly this, applied to inference: cheap models are tier one, the frontier is the senior engineer, and the art is in the escalation decision.
The research foundation
This is not a clever hack, it is an established result with a clear research lineage. FrugalGPT by Chen, Zaharia, and Zou formalized the LLM cascade and demonstrated that learning which model to use for which query could reduce inference cost by up to 98 percent while matching the performance of the best single model. Read that number again: a 98 percent cost reduction at matched quality is not an optimization, it is a different cost structure entirely. The reason it works is the reason this book exists: most queries are easy, easy queries do not need an expensive model, and a system that recognizes easy queries and handles them cheaply captures almost all the savings while losing almost none of the quality.
The FrugalGPT paper laid out three families of cost-reduction strategy, all of which fit the cascade: prompt adaptation (use shorter or cheaper prompts when possible), LLM approximation (use a cheaper model or a cache when it suffices), and LLM cascade (try cheap first, escalate on low confidence). The cascade is the one with the most use in practice, and the rest of this chapter is about building one well, because the difference between a cascade that captures the 98 percent and one that captures nothing is entirely in the escalation logic.
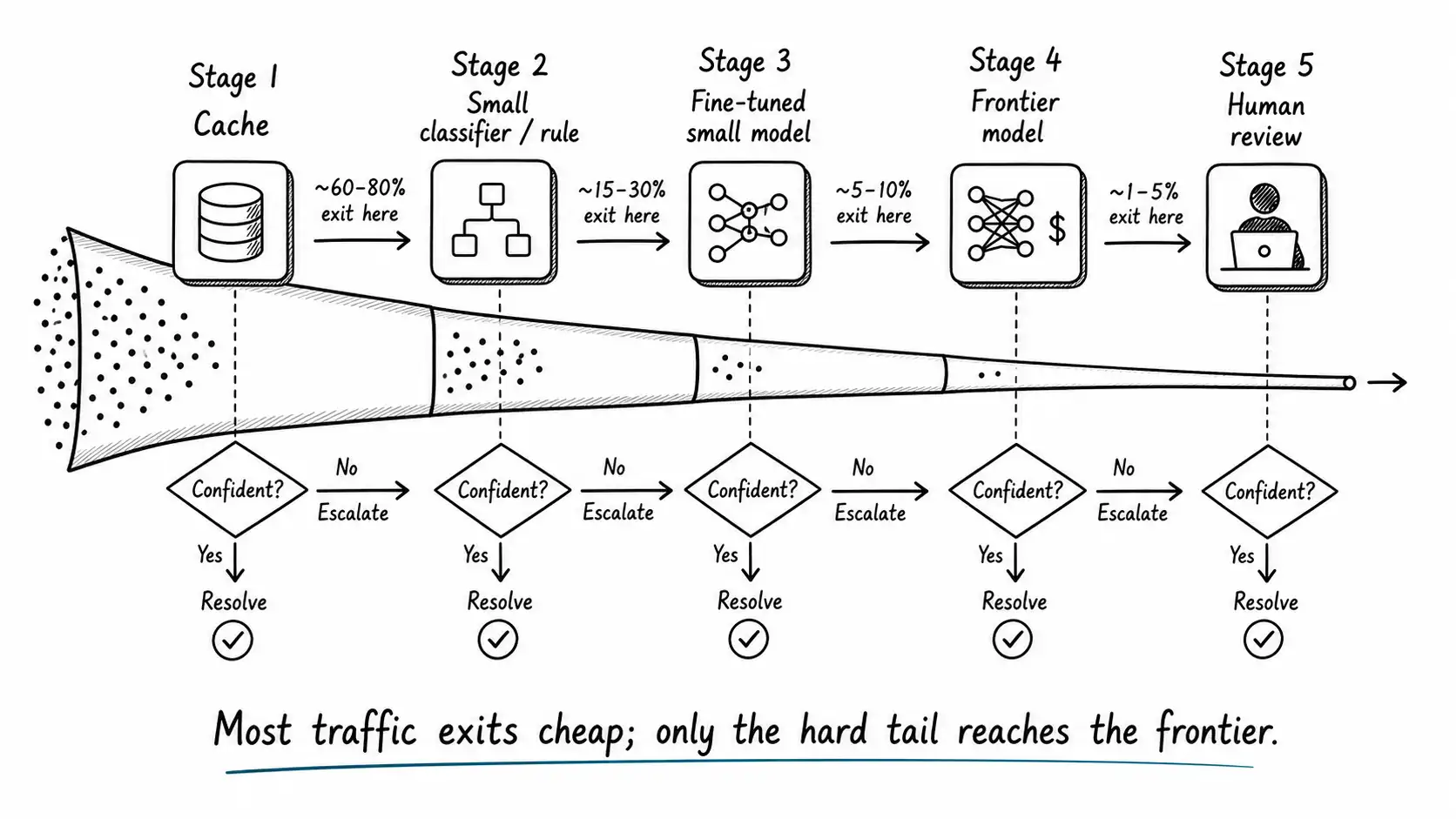
The anatomy of a cascade
A small-first cascade has three parts, and each has to be right or the whole thing degrades.
The tiers. An ordered sequence of handlers from cheapest to most capable, drawn from the Right-Sized Intelligence Ladder. A typical cascade might be: a cache, then a rule or small classifier, then a fine-tuned small model, then a frontier model, then a human. Not every cascade needs every tier; the point is an ordering by cost where each tier is meaningfully cheaper than the next.
The escalation decision. At each tier, a decision about whether this tier's answer is good enough or whether to escalate - a question that Proving Good Enough With Evals teaches you to answer with measurement rather than guessing. This is the hard part and the part that determines whether the cascade works. Escalate too eagerly and everything ends up at the frontier and you saved nothing. Escalate too reluctantly and you ship wrong answers from a tier that should have deferred. The escalation decision is where the engineering judgment lives.
The cost accounting. A clear-eyed model of what each tier costs and how often each tier is hit, so you know whether the cascade is actually saving money. A cascade where 80 percent of traffic still reaches the frontier because the escalation logic is too cautious is more expensive than just calling the frontier directly, because you paid for the cheap tiers and the expensive one. Measure the tier-hit distribution or you are flying blind.
The escalation decision, in detail
How does a tier decide whether to escalate? There are several mechanisms, and the right cascade usually combines them.
Confidence-based escalation. The cheap model produces a confidence signal, and below a threshold it escalates. For a classifier this is the probability of the top label; for a generative model it can be a calibrated uncertainty estimate or the model's own self-assessment. This is the most direct mechanism, but it depends on the confidence signal being well-calibrated, which is not automatic. A model that is confidently wrong is the enemy of confidence-based escalation, so you have to verify the calibration on real data before you trust the threshold.
Verifier-based escalation. A cheap check validates the cheap model's output, and escalates if the check fails. The business-rule validation from the extraction chapter is exactly this: if the extracted total is less than the tax, the answer is wrong regardless of the model's confidence, so escalate. Verifiers are powerful because they catch confident errors that confidence-based escalation misses, and they are often cheap deterministic rules rather than models.
Difficulty-based routing. A cheap upfront router predicts how hard the request is and routes directly to the appropriate tier without trying the cheap tiers first. This avoids the cost of cheap attempts that are obviously going to fail, at the cost of needing a good difficulty predictor. It is the right move when the cheap tiers are not free and you can reliably spot hard requests early.
Agreement-based escalation. Run two cheap models; if they agree, trust the answer; if they disagree, escalate. Disagreement among cheap models is a strong signal of a hard or ambiguous case. This costs two cheap calls but can be far cheaper than a frontier call and catches genuine ambiguity well.
A cascade in pseudocode, combining a verifier and a confidence threshold, showing the shape:
def handle(request):
# Tier 0: cache
if cached:= cache.get(request):
return cached
# Tier 1: cheap small model
answer, confidence = small_model.predict(request)
if confidence >= CONF_THRESHOLD and verifier.passes(request, answer):
cache.put(request, answer)
return answer
# Tier 2: frontier model, only for the hard/uncertain minority
answer = frontier_model.generate(request)
if not verifier.passes(request, answer):
return route_to_human(request, answer) # Tier 3
cache.put(request, answer)
return answerTwo design choices in that snippet matter. The verifier runs at both tiers, because a confident small-model answer that fails a hard rule should still escalate, and a frontier answer that fails the rule should go to a human rather than ship. And the cache is populated by both tiers, so an expensive frontier answer for a hard input is reused for free if that input recurs, which is how a cascade gets cheaper over time as it learns the hard cases.
Tuning the escalation threshold
The escalation threshold is the single knob that determines the cascade's economics and quality, and it is a genuine tradeoff you tune with data, not a value you guess. Lower the threshold (escalate more readily) and quality rises while cost rises, because more traffic reaches the frontier. Raise it (escalate less) and cost falls while quality falls, because the cheap tier handles more, including some it gets wrong.
The right way to set it is empirical. Take a labeled evaluation set, run the cascade at a range of thresholds, and plot quality against cost. You get a curve, and you choose the point on the curve that meets your quality bar at the lowest cost, or the point that fits your cost budget at the highest quality. This curve is the operational form of the Margin-Quality Frontier, the framework that says quality, cost, latency, and operational risk trade off along a frontier and your job is to choose a point on it deliberately rather than landing somewhere by accident. The frontier-model reflex chooses the maximum-quality, maximum-cost corner by default. A tuned cascade lets you choose any point on the curve, including the ones with almost the same quality at a fraction of the cost, which is usually where you want to live.
The key insight from the shape of the curve is that it is rarely linear. Because most traffic is easy, you can usually capture most of the quality at a small fraction of the cost, and the curve bends sharply: the last few percent of quality costs most of the money, because it comes from escalating the genuinely hard tail to the frontier. Knowing where the bend is, for your task, is worth more than any benchmark, and you can only find it by measuring on your own data.
When cascades go wrong
Cascades are not free, and they fail in characteristic ways worth naming so you can avoid them.
Escalation that does not save. If your escalation logic sends most traffic to the frontier anyway, you have built a more complex, more expensive version of just calling the frontier. Measure the tier-hit distribution. If the frontier tier is handling more than a modest fraction, your cheap tiers are not pulling their weight and the cascade is not earning its complexity.
Compounding latency. A cascade that tries each tier in sequence adds latency at every escalation. For a request that ends up at the frontier, the user waited for the cheap attempts first. For latency-sensitive features, prefer difficulty-based routing that goes straight to the right tier, or run the cheap tier with a tight timeout. The latency budget from the previous chapter has to account for the worst-case path through the cascade, not just the common path.
Confident wrong answers. Confidence-based escalation fails silently when the cheap model is confidently wrong, which is exactly the case you most need to catch. This is why verifiers matter: an independent check catches errors that the model's own confidence will not. Never rely on confidence alone for high-stakes decisions.
Maintenance surface. A cascade is more moving parts than a single model call: more tiers, more thresholds, more monitoring. This is real operational cost, and at low volume it is not worth it. The cascade earns its complexity at high volume where the cost savings are large, which is consistent with the recurring theme that volume is the variable that decides whether sophistication pays. Data residency and privacy constraints add a further consideration: some tiers may need to run locally regardless of volume.
What to do tomorrow
Take your highest-volume frontier-model feature and build the simplest possible two-tier cascade: a cheap tier (a fine-tuned small model or even a rule) with a verifier, escalating to your current frontier model. Run it against a labeled set at several escalation thresholds, plot quality versus cost, and find the threshold that holds your quality bar. Then look at the tier-hit distribution on real traffic. If the cheap tier is handling the majority at acceptable quality, you have just changed the cost structure of that feature, and you can keep tightening the threshold as you trust the cheap tier more. The frontier model is still there for the hard tail. It is just no longer paying to do the easy work it was always overqualified for.
Key Takeaways
- "Small or large" is a false choice. The mature architecture is a cascade: cheap tiers handle the easy majority and escalate only the hard minority to the frontier, with a human at the top for high-stakes uncertainty.
- FrugalGPT demonstrated up to 98 percent inference cost reduction at matched quality with learned cascades. The savings come from the fact that most queries are easy and easy queries do not need an expensive model.
- A cascade has three parts: ordered tiers by cost, the escalation decision, and honest cost accounting. The escalation decision is the hard part and determines whether the cascade saves anything.
- Escalate using confidence thresholds, independent verifiers, difficulty-based routing, or model agreement, and usually combine them. Verifiers catch the confident-wrong errors that confidence alone misses.
- The escalation threshold is the knob on the Margin-Quality Frontier. Tune it empirically against a quality-versus-cost curve; because most traffic is easy, you can usually capture most of the quality at a fraction of the cost.