Eight Playbooks
This chapter turns eight playbooks into a concrete operating problem for the guardrails book.

Key Takeaways
- Eight Playbooks treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
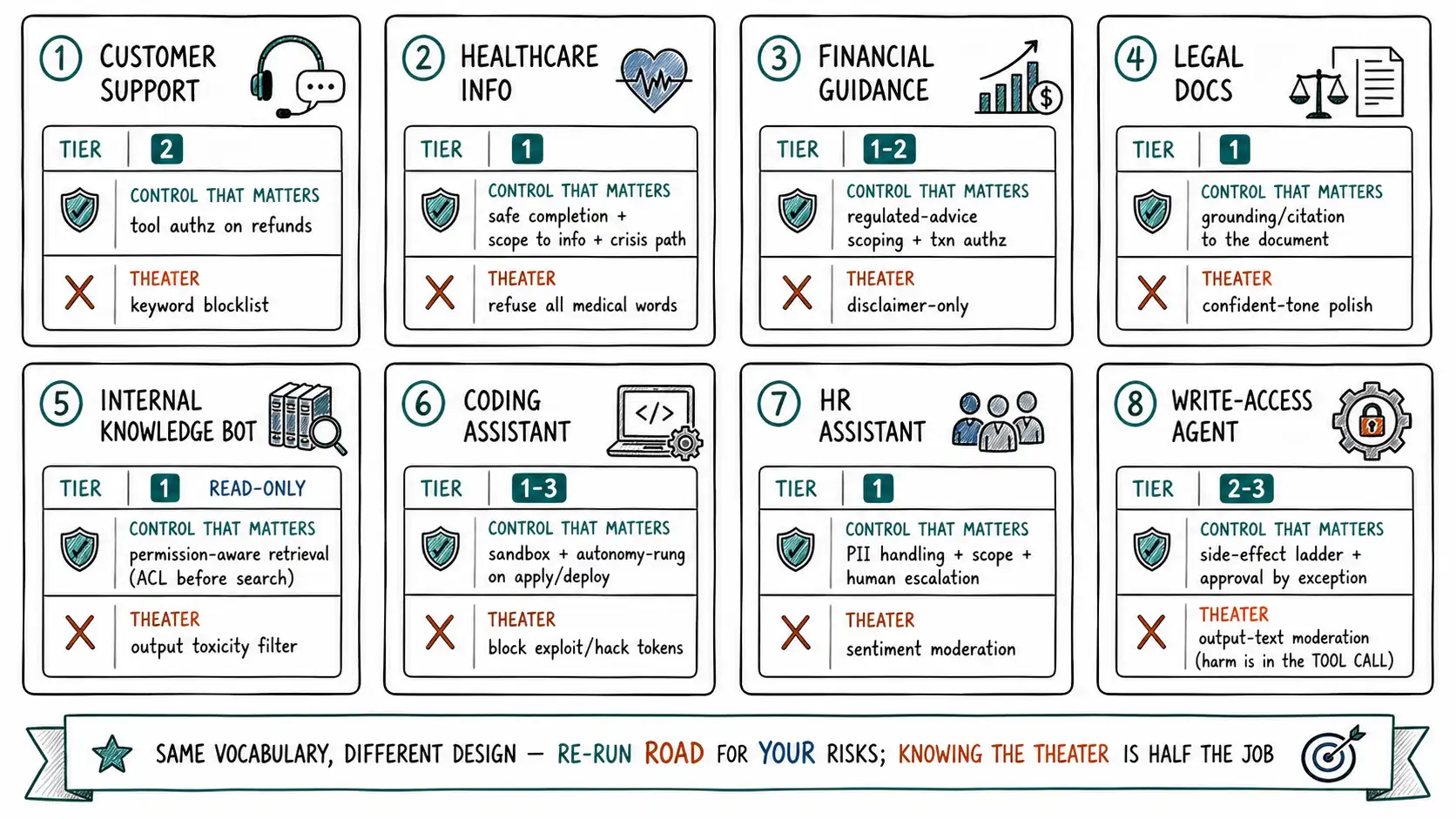
**Working claim: ** The same control vocabulary, tiers, dispositions, the boundary, the side-effect ladder, produces very different guardrail designs for different products, and the fastest way to design a wall by accident is to copy another product's controls without re-running ROAD for your own risks. Each playbook below also names the controls that are theater for that product, because knowing what not to build is half of staying useful.
How to read a playbook
Each playbook below follows the same five-part shape, applied to a different product: the risk profile (which of the five concerns dominate and the system's tier), the controls that matter (placed at boundary operations), the theater (controls that feel safe but reduce no real risk for this product, often imported from a different product's threat model), the eval and monitoring signals that matter most, and the escalation path for the cases the system should not decide. The point is not to memorize eight designs; it is to see how the same vocabulary lands differently when the risks differ, so you can run the same analysis for the product you actually have.
A compact map first, then the detail:
| Product | System tier | Dominant concern | The control that matters most | The classic theater |
|---|---|---|---|---|
| Customer support | 2 | Security + product policy | Tool authorization on refunds/account actions | Keyword input blocklist |
| Healthcare information | 1 | Safety + compliance | Safe completion + scope-to-information + escalation | Refusing all medical words |
| Financial guidance | 1-2 | Compliance + security | Regulated-advice scoping + transaction authz | Disclaimer-only "guardrail" |
| Legal document assistant | 1 | Reliability + compliance | Grounding/citation to the actual document | Confident-tone polish |
| Internal knowledge bot | 1 | Security (data) | Permission-aware retrieval (tenant/ACL) | Output toxicity filter |
| Coding assistant | 1-3 | Security + reliability | Sandbox + autonomy rung control on apply/deploy | Blocking "exploit"/"hack" tokens |
| HR assistant | 1 | Compliance + privacy | PII handling + scope + human escalation | Generic sentiment moderation |
| Write-access agent (CRM/tickets) | 2-3 | Security | Side-effect ladder + approval by exception | Output-text moderation |
1. Customer support assistant
**Risk profile. ** Tier 2 (it can take reversible actions on the user's own account). Dominant concerns: security (acting against owner intent, the refund attack) and product policy (tone, scope). Safety is minor; most support content is benign.
**Controls that matter. ** Intent classification that routes "dispute a charge" to the answer path, not a refusal (op 3). Deterministic authorization on every account action, the requester must own the account (op 12). Refund as request_refund with a hard amount cap and approval above a threshold (ops 10-13, Ch. 10/11). Tool-result and retrieval wrapping so injected instructions in a forwarded document cannot trigger actions (Ch. 7).
**Theater. ** A keyword input blocklist (refuses legitimate billing questions, the introduction's overblock). A heavier output toxicity filter than the content warrants. A long "you must never" system prompt standing in for the authorization check it cannot perform.
**Evals & monitoring. ** Benign near-boundary set heavy on billing/dispute phrasing; adversarial set heavy on injected-document refund attempts. Monitor refund denial reasons, overblock rate on billing categories, and refund-amount anomalies.
**Escalation. ** Disputes the system cannot resolve, suspected fraud, and any refund above the auto-limit route to a human agent with full context.
2. Healthcare information assistant
**Risk profile. ** Tier 1 (advisory; the user relies on information for a health decision). Dominant concerns: safety (harmful or wrong health information) and compliance (it must not practice medicine; jurisdictional rules apply). It takes no actions.
**Controls that matter. ** Scope-to-information: the system provides general, sourced health information and explicitly does not diagnose or prescribe for the individual (op 9/11, degrade-safe). Grounding/citation to authoritative sources so claims are supported (Ch. 8 evidence sieve). Safe completion for risky questions: answer the general part, decline the personalized clinical judgment, point to a clinician (Ch. 9). A robust crisis path for self-harm and emergency indicators (escalation, never a bare refusal).
**Theater. ** Refusing any message containing a medical term (the keyword tax; refuses the nurse and the worried parent). A disclaimer alone treated as a safety control (a disclaimer is necessary for compliance framing but does not make wrong information safe).
**Evals & monitoring. ** Benign set of legitimate clinical and caregiver questions; adversarial set of attempts to extract dangerous specifics (dosages to overdose, self-harm methods). Monitor refusal rate on legitimate medical categories and crisis-path invocation.
**Escalation. ** Emergency and crisis indicators to appropriate resources/handoff; anything that crosses from information into individual clinical advice declines to that boundary and refers out.
3. Financial guidance assistant
**Risk profile. ** Tier 1-2 (advisory, possibly transactional if it touches accounts). Dominant concerns: compliance (regulated financial advice has licensing and disclosure rules) and security (account actions).
**Controls that matter. ** A regulated-advice classifier that distinguishes general education ("how does a Roth IRA work") from personalized recommendation ("should I buy this stock"), degrading the latter to education-plus-disclosure or escalation (Ch. 4 policy, op 9/11). Deterministic authorization and transaction limits on any account-touching action (Ch. 10/11). Full audit with policy version, because compliance is about provable process (Ch. 2).
**Theater. ** A blanket disclaimer treated as the guardrail. Blocking the word "invest" or "stock" (refuses the educational questions the product exists to answer).
**Evals & monitoring. ** Benign education set; adversarial set probing for personalized-recommendation extraction. Monitor regulated-advice classification rate, disclosure-attachment rate, and transaction authz denials.
**Escalation. ** Personalized advice requests beyond the product's licensed scope route to a licensed human; large or unusual transactions to approval.
4. Legal document assistant
**Risk profile. ** Tier 1 (advisory; users rely on it to understand or draft documents). Dominant concerns: reliability (a fabricated clause or citation is the core failure) and compliance (unauthorized practice of law in some contexts).
**Controls that matter. ** Grounding to the actual document, every claim about "what the contract says" must cite the clause it came from, and unsupported claims are degraded, not asserted (Ch. 8 evidence sieve, the single most important control here). Scope-to-information vs. legal advice (degrade-safe). Retrieval firewall, since documents are the corpus and may be attacker-supplied (Ch. 7).
**Theater. ** Polishing the output to sound more confident and authoritative (this makes a reliability failure more dangerous, not less). Toxicity moderation (legal text is rarely toxic; the risk is fabrication).
**Evals & monitoring. ** A set measuring citation accuracy and fabrication rate against ground-truth documents; adversarial set of documents with injected instructions and misleading clauses. Monitor unsupported-claim rate and citation-mismatch rate.
**Escalation. ** Anything requiring legal judgment beyond document analysis refers to a qualified professional.
5. Internal knowledge bot
**Risk profile. ** Tier 1, read-only. Dominant concern: security, specifically data confidentiality, the bot can read internal documents across teams, and the central risk is surfacing data a user is not permitted to see (LLM02).
**Controls that matter. ** Permission-aware retrieval with tenant and document-level ACLs enforced before search (Ch. 7), this is 80% of the design. Leakage sieve on output as a backstop (Ch. 8). Retrieval audit with excluded_count monitoring to catch ACL misconfiguration and probing.
**Theater. ** An output toxicity filter (internal docs are rarely toxic; the risk is confidentiality, not offense). Input keyword blocking. A heavy refusal layer (the bot's job is to be helpful within permission; refusal is rarely the right control here, scoping retrieval is).
**Evals & monitoring. ** A set that checks a user only ever retrieves what their role permits (cross-permission tests); adversarial set attempting to retrieve restricted documents through clever phrasing. Monitor excluded-chunk rate and any leakage-sieve hits (which should be near zero if retrieval is correct).
**Escalation. ** Requests for documents outside the user's permission are declined with a clear boundary message and, if the user believes they should have access, routed to an access-request workflow, not a dead-end refusal.
6. Coding assistant
**Risk profile. ** Tier 1 to 3 depending on capability: proposing code is tier 1; running code is tier 2; deploying or modifying infrastructure is tier 3. Dominant concerns: security (code execution, secret handling) and reliability (wrong code).
**Controls that matter. ** Sandboxing for any code execution, isolated environment, no production credentials, network and filesystem limits (the execution analog of least privilege). The autonomy-rung decision (Ch. 11): propose-only is rung 1, apply-with-review is rung 2, autonomous deploy is rung 3 and needs approval gates. Secret-scanning on both the code the assistant reads and the output it produces.
**Theater. ** Blocking tokens like "exploit, " "hack, " "kill, " "payload" (refuses legitimate security and systems work, the canonical keyword-tax victim). Refusing to discuss vulnerabilities (refuses the defenders who are the main users).
**Evals & monitoring. ** Benign set of legitimate security/systems questions; adversarial set of attempts to get the assistant to write malware or exfiltrate secrets, plus sandbox-escape attempts. Monitor sandbox resource anomalies and any privileged action attempts.
**Escalation. ** Deploy and infrastructure-change actions require human approval; ambiguous high-impact operations escalate rather than auto-applying.
7. HR assistant
**Risk profile. ** Tier 1. Dominant concerns: compliance and privacy (it handles employee personal and sensitive data; employment law applies) plus fairness.
**Controls that matter. ** PII handling end to end, redaction at input, leakage sieve at output, careful logging (Ch. 6/8/13). Scope and permission: an employee sees their own data, a manager sees their team's, HR sees more, enforced as authorization (op 12). Safe, careful handling of sensitive disclosures (harassment, mental health) with a human escalation path that does not auto-process the report.
**Theater. ** Generic sentiment moderation that flags emotional-but-legitimate messages. A toxicity filter standing in for the actual control, which is permission and PII handling.
**Evals & monitoring. ** Cross-permission tests (a manager cannot pull another team's records); a benign set of sensitive-but-legitimate disclosures that must be handled with care, not refused. Monitor PII-leak-sieve hits and permission denials.
**Escalation. ** Harassment, safety, and legal-sensitive disclosures route to a human with appropriate confidentiality; the system facilitates, it does not adjudicate.
8. Write-access agent (CRM, tickets)
**Risk profile. ** Tier 2-3 (it modifies external systems and may message customers). Dominant concern: security and excessive agency (LLM06), this is the agent the introduction's refund attack generalizes to.
**Controls that matter. ** The full tool stack: least-privilege capability manifest, deterministic authorization, argument validation, and the side-effect ladder (Ch. 10/11). Customer-facing messages staged with a review/cancel window (turning rung 3 into rung 2). Tool-result wrapping against second-order injection. Approval by exception for high-value or anomalous actions.
**Theater. ** Output-text moderation (the harm is in the tool call, not the prose, the precise mistake from the introduction). A system prompt asking the model to "only act when appropriate."
**Evals & monitoring. ** Adversarial set of injected instructions (direct and via retrieved/tool content) attempting unauthorized writes; benign set ensuring routine legitimate actions are not over-gated. Monitor tool-call denial reasons, approval-queue health (Ch. 11 rubber-stamp risk), and outbound-action anomalies.
**Escalation. ** Irreversible or high-value actions, and any action the policy engine flags as anomalous, route to human approval with full context and consequence shown.
Chapter summary
The same control vocabulary produces different guardrail designs for different products, and copying another product's controls without re-running ROAD for your own risks is the fastest way to build a wall by accident, so each playbook names not just the controls that matter but the theater for that product, the controls that feel safe but reduce no real risk and are usually imported from a different threat model. Customer support (tier 2, security) lives or dies on tool authorization for refunds and account actions, not the keyword blocklist that overblocks billing questions. Healthcare information (tier 1, safety/compliance) needs safe completion, scope-to-information, and a crisis path, not refusal of every medical word. Financial guidance (compliance/security) needs regulated-advice scoping and transaction authorization with audit, not a blanket disclaimer. Legal documents (reliability/compliance) need grounding and citation to the actual document, while confident-tone polish makes the reliability failure worse. Internal knowledge bot (security/data) is mostly permission-aware retrieval with ACLs enforced before search, not an output toxicity filter. Coding assistant (security/reliability) needs sandboxing and the autonomy-rung decision on apply/deploy, not blocking of "exploit"/"hack" tokens that refuses the defenders who are its users. HR assistant (compliance/privacy) needs end-to-end PII handling, permission scoping, and careful human escalation for sensitive disclosures, not generic sentiment moderation. Write-access agent (security/excessive agency) needs the full tool stack and side-effect ladder with approval by exception, while output-text moderation is exactly the introduction's mistake because the harm is in the tool call. Across all eight, the lesson is to run the same analysis, tier, dominant concern, control at the right operation, named theater, eval and monitoring signals, escalation path, for the product you actually have.