Monitoring and the Bypass Incident
> **Working claim: ** Guardrails decay in production even when the code does not change, because users, attackers, content, and policy all drift around a fixed control.

Key Takeaways
- Monitoring and the Bypass Incident treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** Guardrails decay in production even when the code does not change, because users, attackers, content, and policy all drift around a fixed control. A guardrail program that cannot see its own behavior in production is operating on the memory of a passing eval, and the day a control is bypassed, the only thing that limits the damage is whether you can detect it, scope it, and respond before the next thousand requests.
Why a passing eval expires
The eval suite from Chapter 12 measures the system against a fixed snapshot of inputs. Production is not fixed. Four kinds of drift erode a guardrail's behavior even when not a single line of its code changes, and a monitoring program exists to make each of them visible.
**User drift. ** The population of users and the way they phrase requests shifts over time, new use cases, new vocabulary, new locales. A control tuned to last quarter's request distribution overblocks this quarter's, because the benign requests near the boundary have moved. The overblock rate that passed the eval in March is a different number in September.
**Attacker drift. ** Adversaries adapt. A bypass technique that did not exist when you built your adversarial set will exist eventually, and the first sign of it is usually in production telemetry, a cluster of unusual inputs, a spike in a particular injection signal, not in your test suite. Attacker drift is the reason the adversarial eval set must be fed from production (Chapter 12), and monitoring is the feed.
**Content drift. ** For retrieval systems, the corpus changes: documents are added, edited, poisoned. The indirect-injection content sitting in a wiki page (Chapter 7) was placed by someone, at some time, and the only way to catch it before it acts is to monitor the retrieval layer for injection-shaped content entering context.
**Policy drift. ** The policy changes (Chapter 4), and a control still enforcing the old version is the stale-policy failure from Chapter 1. Monitoring must tie behavior to policy version so you can see when a control is enforcing a rule the business has moved past.
The NIST AI RMF Manage function is built around this reality: risk management is continuous, not a launch-gate event, because the system's risk posture changes after deployment. Monitoring is how Manage becomes real.
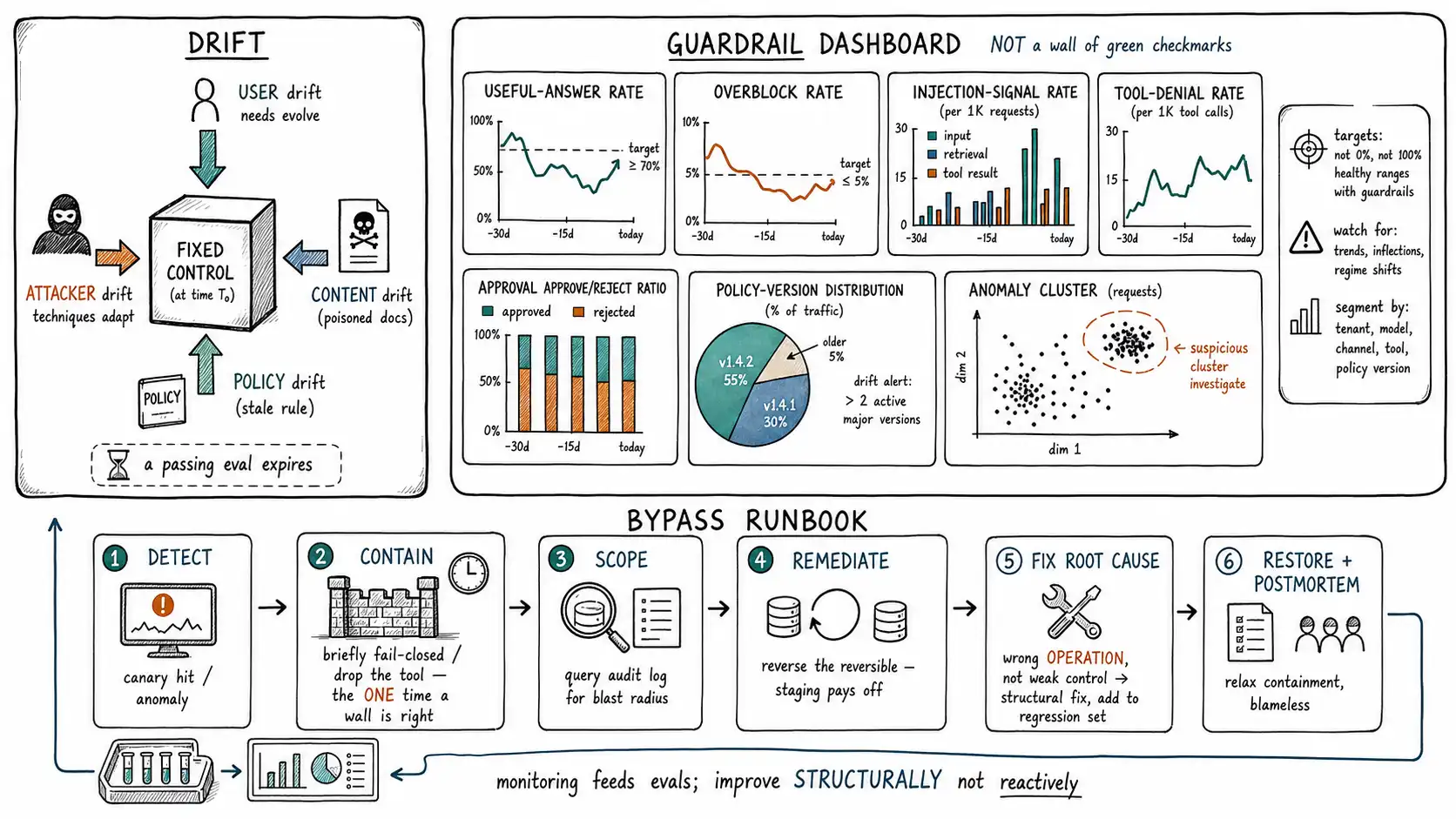
What to monitor: the guardrail dashboard
The dashboard for a guardrail program is not a wall of green checkmarks (that was the theater from the introduction). It is the small set of numbers that, watched over time, reveal both failure directions and the early signs of an attack. Each metric maps to a failure mode from Chapter 1.
| Metric | What it reveals | Failure mode |
|---|---|---|
| Useful-answer rate | Fraction of sessions that got a real answer | Overall product health |
| Overblock / false-refusal rate | Legitimate requests refused | Overblock (the churn cost) |
| Refusal rate by category | Which categories are over-refusing | Overblock, localized |
| Injection-signal rate (input + retrieval + tool result) | Attempted attacks across all vectors | Bypass attempts |
| Tool-call denial rate & reasons | Authorization/constraint denials | Underblock attempts, misconfiguration |
| Approval-queue volume & approve/reject ratio | Whether the human gate is meaningful | Rubber-stamp risk (Ch. 11) |
| Escalation rate | Cases routed to humans | Tier/policy calibration |
| Policy version distribution | Which policy version served responses | Stale policy |
| Anomaly clusters | Unusual input/output/action patterns | Bypass, drift |
The schema that backs the dashboard must capture enough to reconstruct a decision after the fact, because when an incident happens, the question is always "what exactly did the system see and decide, for which user, under which policy?"
CREATE TABLE guardrail_event (
event_id TEXT PRIMARY KEY,
request_id TEXT NOT NULL,
principal TEXT NOT NULL, -- who (for scoping an incident's blast radius)
tenant_id TEXT NOT NULL,
operation INT NOT NULL, -- boundary op 1..17 (Ch.3) where the control ran
control_id TEXT NOT NULL, -- which guardrail
disposition TEXT NOT NULL, -- allow|log|redact|degrade|approve|refuse|escalate
reason_class TEXT, -- category, NOT raw content (privacy)
injection_flags JSONB, -- detector findings (input/retrieval/tool result)
tool_call JSONB, -- {name, arg_hashes, authz_result} if a tool was involved
policy_version TEXT NOT NULL, -- ties the decision to its governing policy (Ch.4)
model_version TEXT NOT NULL,
severity TEXT,
created_at TIMESTAMPTZ NOT NULL
);Two design choices protect the program. reason_class and argument hashes rather than raw content keep the monitoring layer from becoming a new PII leak, a monitoring system that logs everything in the clear is a compliance incident waiting to happen (the Chapter 6 lesson applied to telemetry). And policy_version on every event is what lets you answer the regulator's and the postmortem's first question without guessing.
Detecting the bypass
A bypass is the incident this chapter is really about: a control that was supposed to intervene did not, and an attacker (or a bug) got a harmful result through. The hardest property of a bypass is that, by definition, the control did not flag it, so you cannot detect it by watching the control's own alerts. You detect it by watching for the consequences and the patterns the control missed.
- **Outcome monitoring. ** Watch the downstream effects, not just the model's decisions. A spike in refunds, an unusual volume of outbound messages, a cluster of permission grants, these are visible at the side-effect layer even when the guardrail that should have caught them stayed silent. This is why the tool-call audit log (Chapter 10) and the side-effect controls (Chapter 11) double as detection: a bypassed text filter is invisible, but the unauthorized action it enabled is visible at the tool boundary.
- **Anomaly detection on inputs and sessions. ** A single bypass attempt looks normal; a campaign does not. Many sessions converging on the same unusual phrasing, a single principal probing variations, a sudden rise in injection-signal-but-allowed events, these patterns are detectable in aggregate even when each instance passed.
- **Canary and honeytoken checks. ** Plant detectable markers, a fake record that should never be retrieved, a tool argument that should never appear, and alert if they ever surface, which proves a boundary was crossed.
- **Sampled human review. ** A small, continuous sample of production interactions reviewed by humans catches the qualitative failures that no metric names yet, the new attack class, the subtly-wrong-but-confident answer, the overblock pattern the benign set did not anticipate.
The bypass runbook
When detection fires, or when a customer report, a researcher disclosure, or an audit reveals a bypass, you need a pre-written runbook, because the worst time to design an incident response is during the incident. The runbook for a guardrail bypass has a specific shape, because the failure has a specific structure: a control at a known operation let through something it should have caught, possibly at scale, possibly still ongoing.
RUNBOOK: AI Guardrail Bypass
1. DETECT & DECLARE
- Trigger: outcome anomaly, canary hit, injection-signal cluster, report, or audit finding.
- Declare severity from blast radius: how many requests, what side effects, reversible?
- Page the on-call owner of the affected control (every control has a named owner - Ch.4).
2. CONTAIN (stop the bleeding before understanding it fully)
- Identify the operation (Ch.3 boundary) and control that was bypassed.
- Apply the BLUNTEST safe action at that operation temporarily: tighten the threshold,
disable the affected tool (drop its capability from the manifest - Ch.10),
force approval on the affected action class (raise its side-effect rung - Ch.11),
or fail-closed the affected path. Accept temporary overblocking to stop active harm.
- Note: containment is the ONE time the wall is the right move - briefly, deliberately, logged.
3. SCOPE (who/what was affected)
- Query guardrail_event + tool audit for the bypass signature since first occurrence.
- List affected principals, tenants, and any irreversible side effects (the rung-3 actions).
- Determine reversibility: which effects can be rolled back (Ch.11 staging/soft-delete pays off here).
4. REMEDIATE
- Reverse what is reversible (refunds, soft-deletes, staged actions).
- For irreversible effects: notify affected parties, follow compliance obligations.
- Rotate any credentials/secrets the bypass may have exposed.
5. FIX THE ROOT CAUSE (not just the instance)
- Add the exact bypass to the regression set (Ch.12) - it must never recur silently.
- Ask: was the control at the right OPERATION? (Most bypasses are wrong-operation, not weak-control.)
- Prefer a STRUCTURAL fix (deterministic authz, least privilege, lower rung) over a
detection patch (a new keyword), because detection patches overfit.
6. RESTORE & POSTMORTEM
- Relax the temporary containment once the structural fix is verified by eval.
- Blameless postmortem: timeline, detection latency, blast radius, why the eval missed it,
what monitoring would have caught it sooner. Feed all of it back into the suite and dashboard.Two parts carry the chapter's argument. Containment is the one place a wall is correct, temporarily fail-closed or disable a capability to stop active harm, accepting deliberate overblocking for a short, logged window, then climbing back down once the structural fix lands. This is the disciplined use of the wall, not the reflexive one. And the root-cause step encodes the book's deepest lesson: most bypasses are not weak controls; they are controls at the wrong operation, the text filter that never saw the tool call, the input check that could not see the retrieved document. The fix is almost never "make the classifier stricter"; it is "put a deterministic control at the operation where the harm actually lands, " which is the entire thesis of the boundary map and ROAD.
Continuous improvement without paranoia
The loop closes: monitoring feeds the eval suite (new attacks become regression and adversarial cases), the eval suite gates releases, releases change production, and monitoring watches the result. Run this loop and the guardrail program improves continuously instead of decaying. The discipline that keeps it sane, and connects back to Chapter 12's overfitting warning, is to improve structurally rather than reactively. Every incident tempts a narrow patch (block this phrase, this domain, this pattern); accumulate enough narrow patches and you have rebuilt the nine-hundred-line prompt as a thousand brittle rules, with the overblocking and unmaintainability that implies. The mature response to most incidents is to ask whether a structural control, a deterministic check, a tighter capability manifest, a lower side-effect rung, a better-placed gate, would have prevented the whole class, and to prefer that over the patch. Guardrails that improve this way get more precise (lower on both error rates) over time; guardrails that improve reactively get more restrictive (higher overblock) and no safer against the next novel attack. The honest end state is not a system that cannot be bypassed, that system does not exist, but a system whose bypasses are rare, observable within one cycle, scoped quickly, mostly reversible, and never repeated.
Chapter summary
Guardrails decay in production without any code change because four kinds of drift move around a fixed control: user drift (the benign requests near the boundary shift, raising overblock), attacker drift (new bypass techniques appear in telemetry before they appear in your test suite), content drift (the retrieval corpus is edited and poisoned), and policy drift (a control enforces a version the business has moved past). The NIST AI RMF Manage function exists for this: risk management is continuous, and monitoring is how it becomes real. The guardrail dashboard is not a wall of green checkmarks but the small set of numbers that reveal both failure directions and early attack signs, useful-answer rate, overblock and per-category refusal rates, injection-signal rates across input/retrieval/tool vectors, tool-denial rate, approval approve/reject ratio, escalation rate, policy-version distribution, anomaly clusters, backed by an event schema that can reconstruct any decision after the fact while logging reason classes and argument hashes rather than raw content so monitoring does not become a new PII leak. A bypass is hard to detect because the control did not flag it, so you watch consequences and patterns instead: outcome monitoring at the side-effect layer (the bypassed text filter is invisible but the unauthorized action it enabled is visible), session anomaly detection, canaries and honeytokens, and sampled human review. The pre-written bypass runbook, detect, contain, scope, remediate, fix root cause, restore and postmortem, encodes two lessons: containment is the one place a wall is correct (briefly, deliberately fail-closed to stop active harm, then climb back down), and most bypasses are not weak controls but controls at the wrong operation, so the fix is structural placement, not a stricter classifier. Closing the loop, monitoring feeds evals, evals gate releases, releases change production, makes guardrails more precise over time if you improve structurally, or merely more restrictive and no safer if you improve reactively; the honest end state is bypasses that are rare, observable within a cycle, scoped fast, mostly reversible, and never repeated.