Five Words That Get Confused
> **Working claim: ** "Safety" is used as a catch-all for five different concerns, safety, security, compliance, reliability, and product policy, that have different owners, different threat models, different controls, and different acceptable failure rates.

Key Takeaways
- Five Words That Get Confused treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** "Safety" is used as a catch-all for five different concerns, safety, security, compliance, reliability, and product policy, that have different owners, different threat models, different controls, and different acceptable failure rates. A guardrail program that does not separate them will protect against the wrong thing while believing it is covered.
A meeting where everyone agreed and nobody understood
A composited but familiar scene. A launch review for an AI feature. The legal lead says "we need to make sure it's safe before we ship." The security engineer nods and says "agreed, safety is non-negotiable." The product manager says "totally, safety first." Everyone in the room agrees, the meeting feels productive, and the feature ships on schedule. Three weeks later there is an incident, and in the postmortem it emerges that legal meant we cannot give financial advice without a disclaimer and a regulated-advice carve-out, security meant the model must not be promptable into leaking other tenants' data, and the product manager meant the assistant should not be rude or go off-brand. Three completely different concerns, three completely different sets of controls, all collapsed into one word that let everyone agree without agreeing on anything.
This is the most expensive ambiguity in the field, and it is purely linguistic."Safety" in AI product work routinely means at least five distinct things, and they pull in different directions. Until a team can say which one it is talking about at any given moment, it cannot decide who owns the control, what the threat model is, what failure rate is acceptable, or whether a given guardrail is even relevant. This chapter is a vocabulary, and the vocabulary is load-bearing, because the rest of the book places controls: and you cannot place a control until you know which concern it serves.
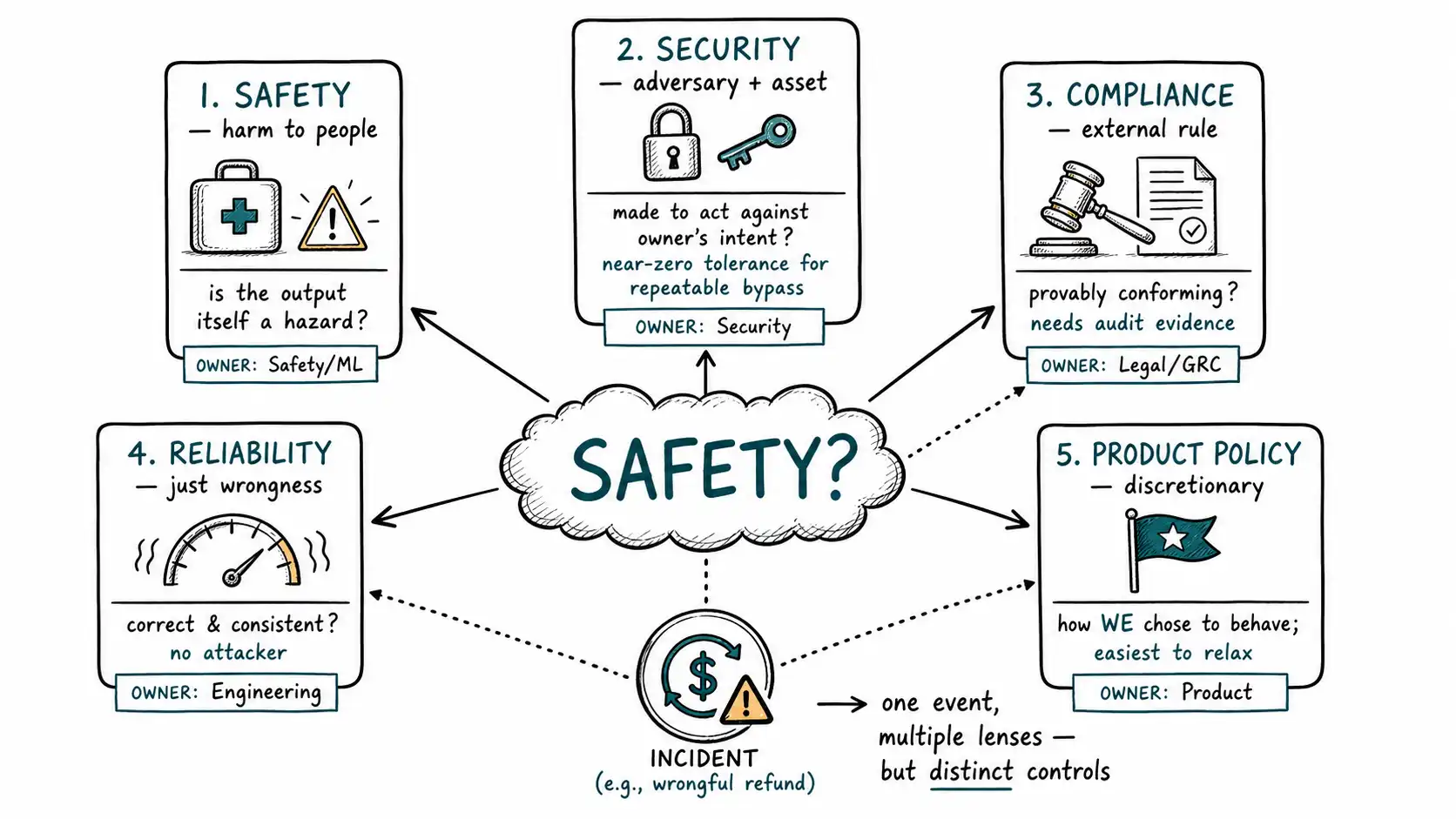
The five concerns
Safety
Safety is about preventing the system from causing or enabling harm to people, including the user, third parties, and society. The harm might be physical (dangerous medical or chemical instructions), psychological (content that worsens a mental-health crisis), or societal (assistance with weapons, large-scale fraud, child exploitation material). The defining feature of safety is that the content or capability of the output itself is the hazard, regardless of who asked or whether the data was handled correctly. A model that flawlessly protects every tenant's data and perfectly follows brand voice while walking a user through synthesizing a nerve agent has a catastrophic safety failure and zero security, compliance, or policy failure.
Safety is the concern that model providers invest in most directly through alignment training, and it is the one where trained refusal does real work. But it is also the concern most prone to overblocking, because the categories are broad and the cost of a miss is severe, so the temptation to over-refuse is strongest here. The threat model spans both ordinary misuse and determined adversaries.
Security
Security is about preventing an adversary from making the system do something the system's owner did not intend, accessing data they should not, executing actions they should not, exfiltrating secrets, escalating privilege, or turning the AI into a confused deputy that wields the application's credentials on the attacker's behalf. The defining feature is an adversary and an asset: there is data or capability the system is supposed to protect, and someone is trying to get at it. Prompt injection, sensitive-information disclosure, improper output handling, and excessive agency, the bulk of the OWASP Top 10 for LLM Applications, are security concerns, not safety concerns in the harm-to-people sense. The refund attack in the introduction was a security failure: the system did something its owner did not intend, on behalf of an attacker.
Security has a different acceptable failure rate than safety. For safety, a small residual rate of refusing a harmful request that slips through is bad but bounded. For security, a single reliable bypass that an attacker can repeat at scale is a breach. Security controls must therefore lean deterministic, authorization checks, allow-lists, argument validation, rather than probabilistic classifiers, because an adversary will find and exploit the gap in a probabilistic control on purpose.
Compliance
Compliance is about conforming to external rules with legal or contractual force: data-protection law, sector regulation (financial advice, medical devices, lending decisions), accessibility requirements, contractual commitments to enterprise customers, and emerging AI-specific regulation. The defining feature is that the rule comes from outside the company and carries consequences (fines, liability, loss of certification) for violating it, independent of whether any user was harmed. A system can be perfectly safe, perfectly secure, and still be non-compliant, for example, by processing personal data without a lawful basis, or by giving regulated financial advice without the required disclosures and licensing.
Compliance controls are often about evidence and process as much as behavior: not just "don't do the prohibited thing" but "be able to prove, with records, what the system did and why, and that a human reviewed the high-stakes decision." This is where the audit trail stops being a debugging convenience and becomes a legal artifact. The NIST AI RMF is not itself law, but its Govern/Map/Measure/Manage structure is increasingly used as the scaffolding regulators and auditors expect a serious AI program to demonstrate.
Reliability
Reliability is about the system doing what it is supposed to do, correctly and consistently, in the absence of any adversary. Hallucination, incorrect calculations, malformed structured output that breaks a downstream parser, inconsistent answers to the same question, latency spikes, and silent degradation when a dependency fails, these are reliability failures. The defining feature is that there is no attacker and no harmful intent; the system is simply wrong or unstable. A financial assistant that invents a number is a reliability failure (the number is wrong) that can become a safety or compliance failure (a user acts on it; a regulator notices), which is exactly why reliability belongs in a guardrails book even though it is not "safety" in the narrow sense.
Reliability controls are validators, schema enforcement, evidence checks, fallbacks, and circuit breakers. They have the most generous acceptable failure rate of the five, some wrongness is inherent to probabilistic systems, but the cost of a reliability failure escalates sharply when the wrong output feeds a high-stakes decision or an automated action.
Product policy
Product policy is the company's own chosen rules about what the product should and should not do, beyond what safety, security, compliance, or reliability strictly require. Brand voice, scope ("we answer questions about our product, not general trivia"), competitor mentions, tone in sensitive situations, which topics are in or out of bounds for business reasons rather than legal ones. The defining feature is that the rule is discretionary, the company could choose differently, and it is owned by product, not by legal or security. An assistant that helpfully recommends a competitor's product has no safety, security, compliance, or reliability failure; it has a product-policy failure.
Product policy is where overblocking does the most quiet damage, because product-policy rules are the easiest to over-write ("never discuss anything related to X") and the hardest to notice when they refuse legitimate use, since by definition they are about discretionary scope.
Why the distinction is not pedantic
The five concerns differ on every axis that matters for placing a control.
| Concern | Threat model | Defining question | Acceptable failure rate | Primary owner | Control style |
|---|---|---|---|---|---|
| Safety | Misuse + adversary | Could the output harm a person? | Low; severe misses are catastrophic | Safety / ML | Trained refusal + classifiers + safe completion |
| Security | Adversary + asset | Can someone make it act against the owner's intent? | Near-zero for repeatable bypass | Security | Deterministic: authz, allow-lists, validation |
| Compliance | External rule | Are we provably conforming to law/contract? | Defined by the rule; often zero tolerance | Legal / GRC | Process, evidence, human-in-loop, audit |
| Reliability | None (just wrongness) | Is it correct and consistent? | Highest, but escalates with stakes | Engineering / ML | Validators, schema, fallbacks, evals |
| Product policy | None (discretionary) | Does it match how we chose to behave? | Business decision | Product | Prompt, policy classifier, scope routing |
Read across a row and the design implications fall out. A security control cannot be a probabilistic classifier alone, because the adversary will defeat it on purpose, so the refund boundary needs a deterministic authorization check, not a sentiment score. A compliance control is incomplete without an audit record, because conformance must be provable, so "the model usually adds the disclaimer" is not a compliance control; "every regulated-advice response is logged with the disclaimer attached and the regulated-advice classifier's decision recorded" is. A reliability control tolerates a higher miss rate than a security control but must escalate its strictness as the downstream stakes rise. A product-policy control should be the easiest to relax, because its failures are discretionary and its overblocking is pure self-inflicted friction.
Collapsing these into one word "safety" produces predictable, specific mistakes. Teams apply safety's broad probabilistic refusal to a security problem and get a moderation classifier where they needed an authorization check, the refund attack. They apply product policy's discretionary blocklist to a reliability problem and refuse legitimate questions instead of validating answers. They treat compliance as a behavior to train rather than a process to evidence, and have no audit trail when the regulator asks. The five-word vocabulary is the antidote: before adding any guardrail, say which of the five concerns it serves, and the right control style, owner, and acceptable failure rate come with it.
Concerns overlap; controls should not be confused
A single incident can touch several concerns. The injected refund is primarily a security failure (acted against owner intent), but it is also a reliability failure (the model trusted untrusted text) and potentially a compliance failure (unauthorized financial transaction, missing audit). That overlap is real and is not an argument for collapsing the words, it is an argument for keeping them because one event needs to be analyzed through each lens to design the full set of controls. The security lens gives you the authorization check; the reliability lens gives you the instruction-vs-data separation; the compliance lens gives you the audit record and approval gate. One word would have given you one control and a false sense of coverage.
A useful discipline: for every guardrail in your system, tag it with the concern it primarily serves and any it secondarily supports. When you later audit coverage, you can ask the question the launch meeting failed to ask, which concerns have controls, and which have only a word? A row of the failure matrix with no control behind it is not covered; it is hoped for.
Chapter summary
"Safety" is overloaded, and the overload is the most expensive ambiguity in AI product work because it lets a room agree without agreeing. Separate five concerns. Safety prevents harm to people; the output's content or capability is the hazard; trained refusal helps but overblocking is the chronic risk. Security prevents an adversary from making the system act against its owner's intent; it has an asset and an attacker, near-zero tolerance for a repeatable bypass, and demands deterministic controls (authorization, allow-lists, validation) rather than probabilistic classifiers, most of the OWASP LLM Top 10 lives here, including the refund attack. Compliance conforms to external legal or contractual rules; it is as much about provable process and audit evidence as about behavior. Reliability is correctness and consistency in the absence of any adversary, hallucination, malformed output, instability, with the most generous failure budget, escalating with stakes. Product policy is the company's discretionary choices about scope, voice, and brand; its failures are self-inflicted and its overblocking is pure friction. The five differ on threat model, defining question, acceptable failure rate, owner, and control style, so collapsing them produces specific mistakes: a moderation classifier where an authorization check was needed, a trained behavior where an audit record was needed, a blocklist where a validator was needed. A single incident can touch several concerns; that is a reason to analyze it through each lens, not to merge the words. Tag every guardrail with the concern it serves, then audit coverage by asking which concerns have controls and which have only a word.