Output Controls
> **Working claim: ** A model output can be perfectly fluent, perfectly safe-sounding, and still be invalid, wrong shape for the consumer, leaking data, unsupported by evidence, or valid JSON that violates policy.

Key Takeaways
- Output Controls treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** A model output can be perfectly fluent, perfectly safe-sounding, and still be invalid, wrong shape for the consumer, leaking data, unsupported by evidence, or valid JSON that violates policy. Output controls are a chain of independent sieves (schema, policy, evidence, leakage), and the most common mistake is checking the prose for toxicity while the real defect is structural.
Valid JSON, invalid answer
A composited failure that catches careful teams. A support assistant returned structured responses: a JSON object with the answer, a confidence, and an action field telling the application what to do next (show_answer, escalate, offer_refund). The team validated the output for toxicity with a moderation classifier and shipped. In production, the model occasionally returned {"answer": "...", "confidence": 0.9, "action": "offer_refund"} for questions that had nothing to do with refunds, a hallucinated action field, perfectly polite, perfectly well-formed JSON, that the application dutifully executed by offering a refund the customer had not asked for and was not owed. The toxicity classifier saw nothing wrong, because nothing was toxic. The output was valid as text and as JSON and invalid as policy and as evidence. The control they had was aimed at the one defect the output did not have.
This is the output-side version of the wall mistake: a single sieve (toxicity) at a single point, when the output can fail in several independent ways that the sieve cannot see. OWASP LLM05 Improper Output Handling is precisely this class of risk, treating model output as trustworthy and well-formed when it is neither. Output controls must therefore be a chain of independent checks, each catching a different failure mode, and the consuming application must treat the model's output as untrusted input to itself, not as a command to obey.
Make the shape enforceable, not hoped-for
The first and cheapest output control is to stop asking the model for free text when you need structure, and to enforce the structure rather than parse-and-pray. If the application acts on an action field, that field must come from a constrained set, and the output must be guaranteed to match a schema before any code reads it. Modern model APIs support structured outputs that constrain generation to a supplied JSON schema, which eliminates the "the model returned almost-JSON" class of failure at the source. But schema-conformant is not the same as policy-conformant, the refund hallucination above was schema-conformant, so structured output is the floor, not the ceiling.
Design the schema so that invalid policy states are unrepresentable where possible, and detectable where not. The action enum should not include offer_refund for a system where refunds require a separate authorized path; if refunds are a possibility, the schema should require the supporting fields (the entitlement, the amount, the order) so that a refund action without its justification is structurally invalid and caught by validation.
from pydantic import BaseModel, Field, model_validator
from typing import Literal, Optional
class SupportResponse(BaseModel):
answer: str
confidence: float = Field(ge=0.0, le=1.0)
action: Literal["show_answer", "escalate", "request_refund"]
# If (and only if) action is request_refund, these MUST be present and consistent.
refund_order_id: Optional[str] = None
refund_amount_cents: Optional[int] = Field(default=None, ge=0)
cited_evidence_ids: list[str] = Field(default_factory=list)
@model_validator(mode="after")
def refund_requires_justification(self):
if self.action == "request_refund":
if not self.refund_order_id or self.refund_amount_cents is None:
raise ValueError("request_refund requires order_id and amount")
if not self.cited_evidence_ids:
raise ValueError("request_refund must cite the policy/evidence basis")
return selfNote the deliberate naming: the action is request_refund, not offer_refund or issue_refund. The output layer can at most request a refund; whether it happens is the tool-authorization layer's decision (Chapter 10). This is a small but important discipline, the output schema should describe what the model wants to happen, and a later, deterministic control decides whether it happens. An output that conflates the two (a model field that directly executes) is the refund attack's structural ancestor.
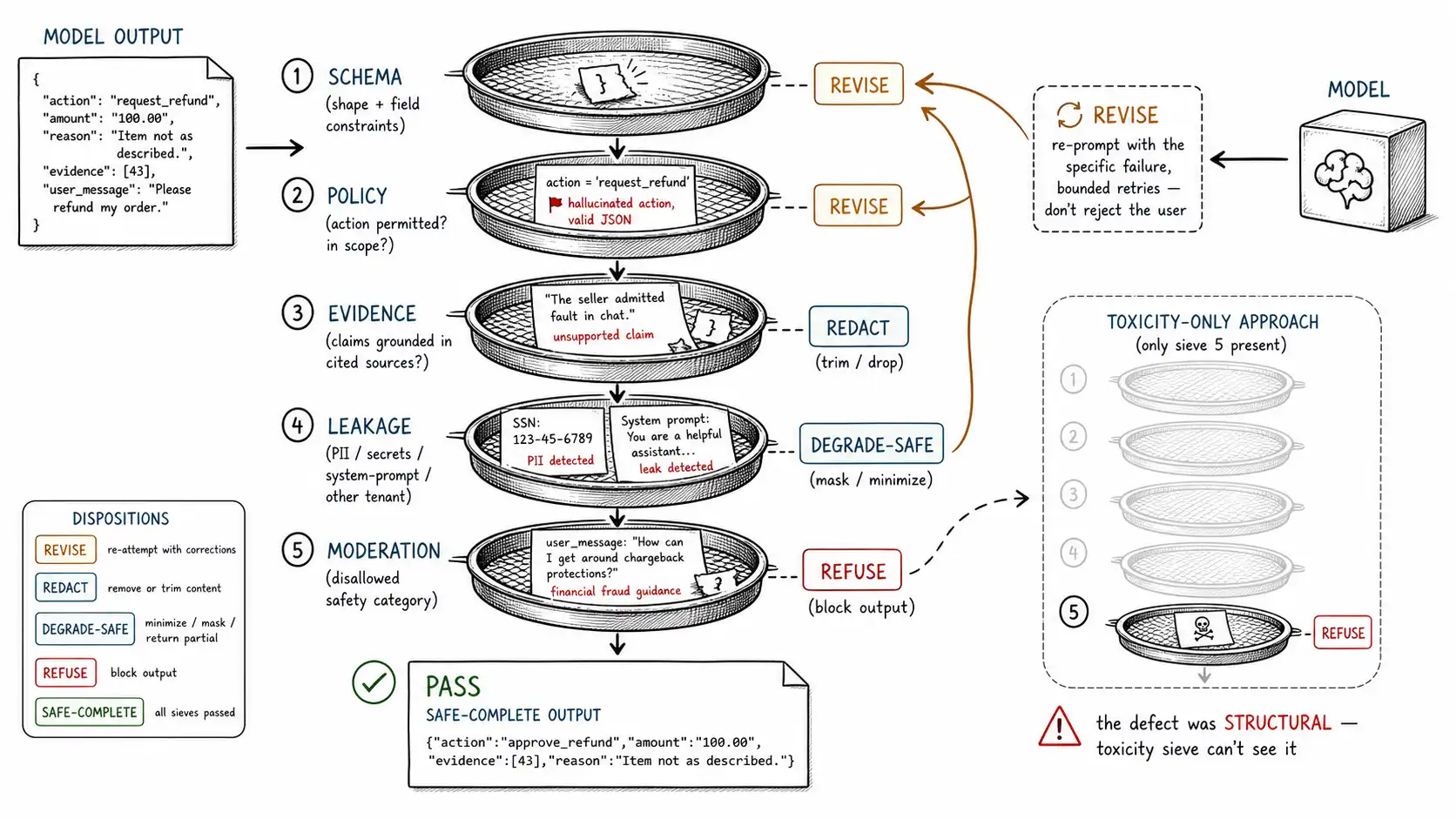
The sieve chain
Past the schema, output controls form a chain. Each sieve is independent, runs in a deliberate order, and produces a disposition from Chapter 4, pass, redact, revise, refuse, escalate. The order matters because cheap deterministic checks should run before expensive probabilistic ones, and because a structural failure should short-circuit before you spend a moderation call.
| Sieve | Checks | Failure disposition |
|---|---|---|
| 1. Schema | Output matches the required structure and field constraints | Revise (re-prompt) or refuse if repeated |
| 2. Policy | Field values are permissible (action allowed, no out-of-scope content) | Revise / refuse / escalate |
| 3. Evidence | Claims are supported by the cited evidence (grounding/citation check) | Redact unsupported claims / degrade-safe |
| 4. Leakage | No PII, secrets, system-prompt, or other-tenant data in the output | Redact / refuse |
| 5. Moderation | Content is not in a disallowed safety category | Safe-complete / refuse |
def validate_output(raw, ctx) -> OutputDecision:
# Sieve 1: schema (cheap, deterministic, short-circuits).
try:
resp = SupportResponse.model_validate_json(raw)
except ValidationError as e:
return OutputDecision.revise(reason="schema", detail=str(e)) # bounded retries
# Sieve 2: policy - schema-valid is not policy-valid.
if not policy.action_permitted(resp.action, ctx):
return OutputDecision.revise_or_refuse(reason="action_not_permitted")
# Sieve 3: evidence - are the claims grounded in what was retrieved?
grounding = check_grounding(resp.answer, resp.cited_evidence_ids, ctx.evidence)
if grounding.unsupported_claims:
return OutputDecision.degrade_safe(strip=grounding.unsupported_claims)
# Sieve 4: leakage - PII / secrets / system prompt / cross-tenant.
leak = scan_for_leakage(resp.answer, ctx)
if leak.found:
return OutputDecision.redact(leak.spans) if leak.redactable \
else OutputDecision.refuse(reason="unredactable_leak")
# Sieve 5: moderation (most expensive; last).
mod = moderate_output(resp.answer)
if mod.disallowed:
return OutputDecision.safe_complete(category=mod.category)
return OutputDecision.pass_(resp)The chain structure is the lesson. The team in the opening story had only sieve 5. Sieve 1 would have nothing to say about the hallucinated refund (it was valid JSON), but sieve 2 (policy: is request_refund permitted for this intent?) and the schema's refund_requires_justification validator would both have caught it. The defect was structural and policy-level, and only a chain that checks structure and policy independently of toxicity catches it. Tools like Guardrails AI validators and NeMo Guardrails are essentially frameworks for composing exactly this kind of sieve chain; the engineering value is in choosing the right sieves and dispositions for your risks, not in any one framework.
Evidence and leakage: the two sieves teams skip
Sieves 1, 2, and 5 are intuitive. The two that get skipped, evidence and leakage, are the ones that matter most for reliability and compliance respectively.
The evidence sieve addresses misinformation (LLM09): the model states something the retrieved evidence does not support, confidently. The defensible control is a grounding check, verify that the answer's factual claims are entailed by the cited evidence, and redact or degrade the unsupported portions rather than passing them through. This is hard to do perfectly (it is itself a model-based judgment with error rates), so the disposition matters: an unsupported claim is usually degraded (the answer is trimmed to what evidence supports, with a note) rather than refused, keeping the road usable. The evidence sieve is also where citation requirements get enforced: if policy says regulated answers must cite their source, an answer that asserts without citing fails here. The grounding-check discipline connects to the broader reliability literature; faithfulness to retrieved evidence is the property being enforced.
The leakage sieve addresses sensitive information disclosure (LLM02) on the way out, the dual of the input PII lane (Chapter 6). The model can leak in several ways: echoing PII it correctly retrieved but should not surface in this context, regurgitating its system prompt (system-prompt leakage is its own OWASP category, LLM07), or, the multitenant nightmare, including data from another tenant that slipped into context past the retrieval firewall. The leakage scan is the last line before the response reaches the user, and its disposition is usually redact (mask the leaked span, keep the rest) with refuse reserved for unredactable leaks. The leakage sieve is also why output controls and the retrieval firewall are complementary: the firewall stops most cross-tenant data from entering context; the leakage sieve catches what slips through before it reaches a user, and logs it as a high-severity signal.
Revise, don't just reject
A theme across the sieve chain is the disposition, and the chapter's thesis lives in one verb: revise. When the schema fails or the policy check fails, the first move is not to refuse the user, it is to re-prompt the model with the specific failure and a bounded number of retries, because most output failures are the model getting the shape slightly wrong, not the model being adversarial. A schema validation error becomes a corrective instruction ("your action field must be one of [...], and request_refund requires order_id and amount"); the model usually fixes it on the next pass. Only after bounded retries fail does the disposition escalate to degrade-safe or refuse.
This matters for the road-usable thesis because naive output guarding refuses the user whenever the model stumbles, converting a recoverable formatting error into an abandoned session. A revise loop keeps the model honest about shape and policy while keeping the user moving. The cost is bounded latency and token spend (cap the retries; a model that cannot produce a valid response in three tries should escalate, not loop forever), and the benefit is that the common case, a slightly-off output, is repaired invisibly rather than punished visibly.
Chapter summary
A model output can be fluent and safe-sounding yet invalid in ways a toxicity check cannot see: wrong shape for the consumer, an action it should not request, claims the evidence does not support, or leaked data, the improper-output-handling class (OWASP LLM05). The opening failure, a hallucinated offer_refund field in valid JSON, shows the wall mistake at the output boundary: one sieve aimed at the one defect the output did not have. Make structure enforceable rather than hoped-for using constrained/structured outputs, and design schemas so invalid policy states are unrepresentable or at least detectable, including requiring justification fields so a refund request without its basis is structurally invalid; name actions as requests the model makes, leaving the decision to a later deterministic control. Past the schema, run a chain of independent sieves in cheap-to-expensive order: schema, policy (schema-valid is not policy-valid), evidence/grounding (LLM09 misinformation, redact or degrade unsupported claims, enforce citations), leakage (LLM02/LLM07, PII, secrets, system prompt, cross-tenant data, the dual of the input PII lane and complement to the retrieval firewall), and finally moderation. Frameworks like Guardrails AI and NeMo Guardrails compose this chain; the value is choosing the right sieves and dispositions. The two skipped sieves, evidence and leakage, are the ones that most protect reliability and compliance. And the load-bearing disposition is revise: re-prompt the model with the specific failure for a bounded number of retries before escalating to degrade-safe or refuse, so the common case of a slightly-off output is repaired invisibly instead of punishing the user with a refusal.