The Side-Effect Ladder
> **Working claim: ** The right amount of autonomy for an agent is a function of one thing: how hard it is to undo what it does. Read actions can run freely; irreversible actions need a human.

Key Takeaways
- The Side-Effect Ladder treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** The right amount of autonomy for an agent is a function of one thing: how hard it is to undo what it does. Read actions can run freely; irreversible actions need a human. The engineering job is to climb the side-effect ladder deliberately, turning irreversible actions into reversible ones with dry-runs, staging, limits, and approval gates: so the agent stays useful without becoming dangerous.
Reversibility is the real risk axis
Chapter 10 gave every tool a side-effect classification, read, draft, write, irreversible, and promised that this classification, not the scariness of the tool's name, would drive how much scrutiny each call gets. This chapter cashes that promise. The organizing insight is that the danger of an agent action is not really about the action's category (money, data, communication) but about its reversibility: how hard, costly, or impossible it is to undo if the agent gets it wrong.
A read action, looking up an order, querying a balance, is trivially reversible because it changes nothing; the worst case is showing the wrong information, which the next read corrects. A draft action, composing a reply, proposing a record change, is reversible because a human or a later step reviews it before it takes effect; nothing has happened yet. A write action, issuing a small refund, updating a status, has a real effect but a bounded, recoverable one; you can reverse the refund, revert the status. An irreversible action, deleting data without backup, sending a message to a customer, transferring large funds, deploying code, granting permissions, cannot be cleanly undone; once it happens, you are doing damage control, not correction.
This gives a clean rule for autonomy: **an agent may act alone in proportion to how easily its action can be undone. ** Read freely. Draft freely (a draft is not an act). Write within limits and with logging. Never take an irreversible action without a gate, a human approval, a strong deterministic check, or a transformation that makes it reversible. The NIST AI RMF frames the human-oversight requirement around exactly this kind of risk-proportionality: the higher the stakes and the harder the recovery, the more the Manage function requires human involvement. The side-effect ladder is that principle made operational.
| Rung | Side effect | Reversibility | Default autonomy | Controls |
|---|---|---|---|---|
| 0 | Read | Total (nothing changes) | Full | Authorization, rate limit, log |
| 1 | Draft / recommend | Total (nothing committed) | Full | Authorization, log; human/next-step reviews before effect |
| 2 | Write, bounded | High (can be reversed) | Within limits | Authz, argument validation, transaction limits, log, alert on anomaly |
| 3 | Irreversible / high-blast-radius | Low or none | None alone | Dry-run, staging, hard limits, human approval, audit, rollback plan |
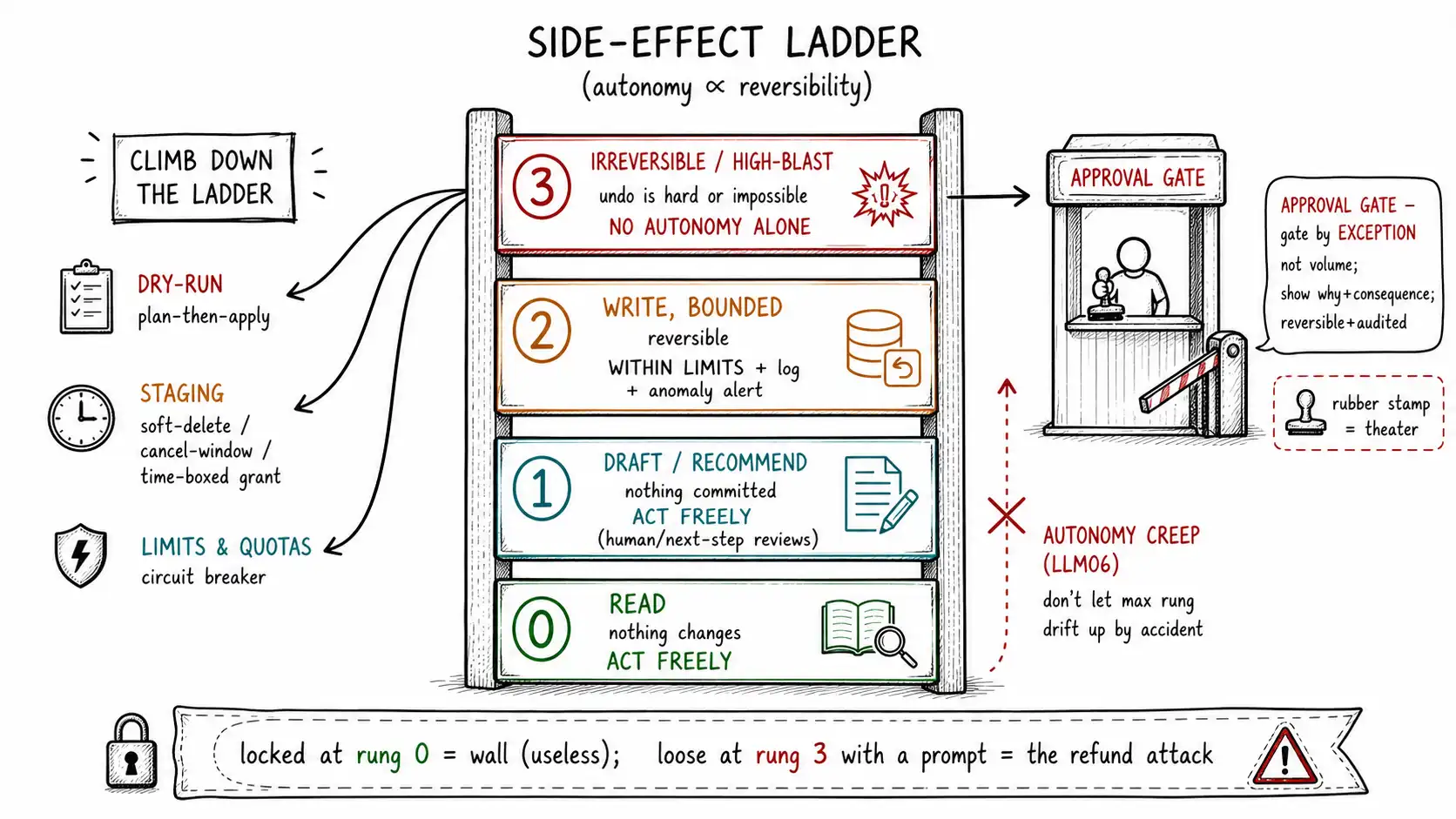
Climbing down the ladder: turning irreversible into reversible
The most valuable move in agent design is not deciding which actions to forbid, it is re-engineering irreversible actions into reversible ones, so that more of the agent's work can be done autonomously without risk. This is climbing down the ladder: moving an action from rung 3 to rung 2 or 1 by changing how it executes, not what it does.
**Dry-run / plan-then-apply. ** Before an agent executes a batch of writes, have it produce the full plan, the exact set of changes, without applying them. A human or a deterministic check reviews the plan; only then does it apply. This converts "the agent deleted the wrong records" into "the agent proposed deleting the wrong records, and the review caught it." Infrastructure tooling has used plan-then-apply for years; agents need it more, because their planner is probabilistic.
**Staging and soft effects. ** Make the effect reversible by default. Instead of sending the email, queue it for five minutes with a cancel window. Instead of deleting the record, soft-delete it (mark revoked, purge later) so it can be restored. Instead of a hard permission grant, grant a time-boxed one that expires. Each of these turns an irreversible rung-3 action into a recoverable rung-2 one, which means the agent can do it with less ceremony and still be safe.
**Limits and quotas. ** A bounded write is far safer than an unbounded one. Per-action limits (no single refund over $200), per-session limits (no more than 5 refunds per conversation), per-principal daily limits, and global circuit breakers (halt all refunds if the rate spikes, likely an attack or a bug) all cap the blast radius. Limits are deterministic and live outside the model (Chapter 10), so no amount of model reasoning or injection can exceed them.
def apply_side_effect_controls(call: ToolCall, tool: Tool, ctx) -> ExecutionPlan:
rung = tool.side_effect_rung # 0 read, 1 draft, 2 write, 3 irreversible
if rung <= 1:
return ExecutionPlan.execute(call, log=True) # read/draft: act freely
# rung 2+: enforce limits BEFORE anything commits.
for limit in tool.limits: # per-action, per-session, per-day
if limit.exceeded_by(call, ctx):
return ExecutionPlan.escalate(call, reason=f"limit:{limit.id}")
if ctx.circuit_breaker.tripped(tool): # global anomaly halt
return ExecutionPlan.halt(call, reason="circuit_breaker")
if rung == 3:
# Never auto-commit irreversible. Try to climb DOWN the ladder first.
if tool.supports_dry_run:
return ExecutionPlan.dry_run_then_review(call) # 3 -> reviewed plan
if tool.supports_staging:
return ExecutionPlan.stage_with_cancel_window(call) # 3 -> 2 (reversible)
return ExecutionPlan.require_human_approval(call, route=ctx.approval_route(tool))
# rung 2: bounded write, within limits -> execute with full audit + anomaly alert.
return ExecutionPlan.execute(call, log=True, audit=True, anomaly_check=True)Approval gates that do not become rubber stamps
When an action genuinely needs a human (rung 3, no way down the ladder), the approval gate is the control, and approval gates fail in a specific, predictable way: they become rubber stamps. A human asked to approve fifty agent actions an hour, each presented as a terse "Approve refund? [Y/N], " will approve everything within a day, because the cognitive load of genuine review at that volume is unsustainable and the base rate of legitimate actions is high. A rubber-stamp approval gate is theater (Chapter 12's term): it looks like human oversight and provides none.
Designing an approval gate that stays meaningful is its own craft:
- **Give the approver the context to decide, not just the decision. ** Show what the agent is about to do, why (the evidence and reasoning), what is anomalous about it, and what the consequence of approving is."Approve refund of $480 to ORD-12345, flagged because amount is 4x this customer's average and the request originated from text in a forwarded document" is reviewable."Approve? [Y/N]" is not.
- **Gate by exception, not by volume. ** Do not send every write to a human; send the anomalous ones. The limits and the policy engine auto-approve the routine, high-confidence, within-bounds actions, and escalate only the ones that are unusual, high-value, or low-confidence. This keeps the human's queue small enough that each item gets real attention, which is the only way the gate stays honest.
- **Make approval auditable and reversible. ** Record who approved, when, on what evidence (compliance, Chapter 2). And where possible, make even the approved action staged or reversible, so an approval given under time pressure is not the last line of defense.
def build_approval_request(call, ctx) -> ApprovalRequest:
return ApprovalRequest(
action_summary=human_readable(call),
why=ctx.reasoning_trace_redacted(), # evidence, not raw chain-of-thought
anomaly_reasons=ctx.anomaly_signals(call), # WHY this one needs eyes
consequence=estimate_consequence(call), # "irreversible: funds leave the account"
recommended_default="reject" if ctx.anomaly_signals(call) else "review",
# gate by exception: routine in-bounds actions never reach here
)The system-level decision: how autonomous should this agent be?
Above individual actions sits the design decision the side-effect ladder is really for: how much autonomy should this agent have at all? The answer is the highest rung the agent is allowed to reach without a human, and it should be set deliberately, per agent, from the system's risk tier (Chapter 5), not allowed to drift upward because autonomy demos well.
A coding assistant that proposes diffs is a rung-1 agent (it drafts; a human merges); giving it autonomous deploy is climbing to rung 3 and changes its entire risk profile. A support agent that answers questions and drafts replies is rung 0-1; letting it issue refunds without limits is rung 2-3. An internal data agent that reads and summarizes is rung 0; letting it write to source systems is a different and more dangerous product. The single most common excessive-agency mistake (LLM06) is autonomy creep: an agent shipped at rung 1 quietly accrues rung-2 and rung-3 capabilities because each addition seemed convenient, until it can take irreversible actions nobody designed controls for. The defense is to make the agent's maximum autonomous rung an explicit, reviewed property, in the manifest, in the policy, on the dashboard, so that raising it is a decision with an owner and a control review, not an accident of feature creep.
The thesis of the book lands hard at this boundary. An agent locked to rung 0 is a wall, safe and nearly useless. An agent let loose at rung 3 with only a prompt for a guardrail is the refund attack and worse. The useful agent climbs the ladder deliberately: it does rung-0 and rung-1 work freely (which is most of the work), does bounded rung-2 work within hard limits, and converts as much rung-3 work as it can into reversible form through dry-runs and staging, reserving genuine human approval for the irreducible remainder of irreversible, high-blast-radius actions. That is an agent that reaches its destination while staying on the road.
Chapter summary
The real risk axis for agent actions is reversibility, not category: a read changes nothing, a draft commits nothing, a bounded write is recoverable, and an irreversible action cannot be cleanly undone, so an agent may act alone in proportion to how easily its action can be undone (the NIST AI RMF human-oversight principle made operational). The side-effect ladder has four rungs, read (full autonomy), draft (full autonomy, reviewed before effect), bounded write (within hard limits, logged, anomaly-alerted), and irreversible (no autonomy alone). The most valuable move is climbing down the ladder, re-engineering irreversible actions into reversible ones so more work can be autonomous safely: dry-run / plan-then-apply converts "deleted the wrong records" into "proposed deleting them, and review caught it"; staging and soft effects (queued email with a cancel window, soft-delete, time-boxed grants) turn rung-3 actions into recoverable rung-2 ones; and deterministic limits and circuit breakers cap blast radius outside the model where no reasoning or injection can exceed them. When a human gate is genuinely required, design it not to become a rubber stamp: give the approver context and consequence, gate by exception (auto-approve the routine, escalate only the anomalous) so the queue stays small enough for real attention, and keep approvals auditable and the approved action reversible. Above individual actions, set each agent's maximum autonomous rung explicitly from its risk tier and defend against autonomy creep, the most common excessive-agency mistake (LLM06), by making any increase a reviewed decision with an owner. The useful agent does rung-0/1 work freely, bounded rung-2 work within limits, converts what rung-3 work it can into reversible form, and reserves human approval for the irreducible remainder.