The System Boundary and the ROAD Framework
> **Working claim: ** You cannot place a guardrail until you can draw the system boundary and name every operation inside it where a risk can occur.

Key Takeaways
- The System Boundary and the ROAD Framework treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** You cannot place a guardrail until you can draw the system boundary and name every operation inside it where a risk can occur. Most guardrail failures are not weak controls: they are controls placed at the wrong operation, or operations with no control at all. ROAD is the procedure for matching a control to the operation that needs it.
The map most teams never draw
Ask a team to draw their AI system and you usually get three boxes: user, model, response. Maybe a database off to the side. This drawing is why guardrails get placed wrong. It shows two boundaries, user-to-model and model-to-user, so the team puts a control at each, an input filter and an output filter, and considers the system covered. The drawing is not wrong so much as catastrophically incomplete. Between "user" and "response" there are at least a dozen distinct operations, each one a place where information transforms, authority is granted, or a side effect occurs. A risk lives at an operation, and a control that is not at that operation cannot reduce that risk.
Here is the boundary drawn honestly, as the sequence of operations a single request passes through in a tool-using, retrieval-backed AI product:
THE SYSTEM BOUNDARY (where guardrails can sit)
[1] USER INPUT ──► [2] AUTH / TENANT ──► [3] INTENT + INPUT MODERATION
│ │
▼ ▼
[4] RETRIEVAL REQUEST ──► [5] PERMISSION FILTER ──► [6] SEARCH / FETCH
│ │
▼ ▼
[7] CONTEXT ASSEMBLY (instructions vs. untrusted evidence)
│
▼
[8] MODEL INFERENCE ──► [9] OUTPUT: TEXT ──┐
│ ├──► [11] OUTPUT VALIDATION
▼ │ (schema, policy, evidence)
[10] OUTPUT: TOOL CALL(S) ────────────────────┘
│
▼
[12] TOOL AUTHORIZATION + ARGUMENT VALIDATION
│
▼
[13] TOOL EXECUTION (side effects on downstream systems)
│
▼
[14] RESULT VALIDATION ──► [15] RESPONSE TO USER
│
▼
[16] LOGGING / MEMORY WRITE / TELEMETRY [17] HUMAN ESCALATION (out-of-band)Seventeen operations, and the naive three-box drawing covered exactly two of them (3 and 11). Notice where the introduction's two failures actually lived. The overblock was at operation 3, input moderation firing on the wrong signal. The refund attack flowed through operation 7 (the injected instruction entered context assembly as if it were trusted), survived operation 9/11 (the output text was clean), and landed at operations 10, 12, and 13 (the tool call, its missing authorization, its execution). The output filter at 11 could not have caught it no matter how good it was, because the harm never passed through 11. This is the single most important reason to draw the full boundary: *it shows you the operations where you have no control at all. *
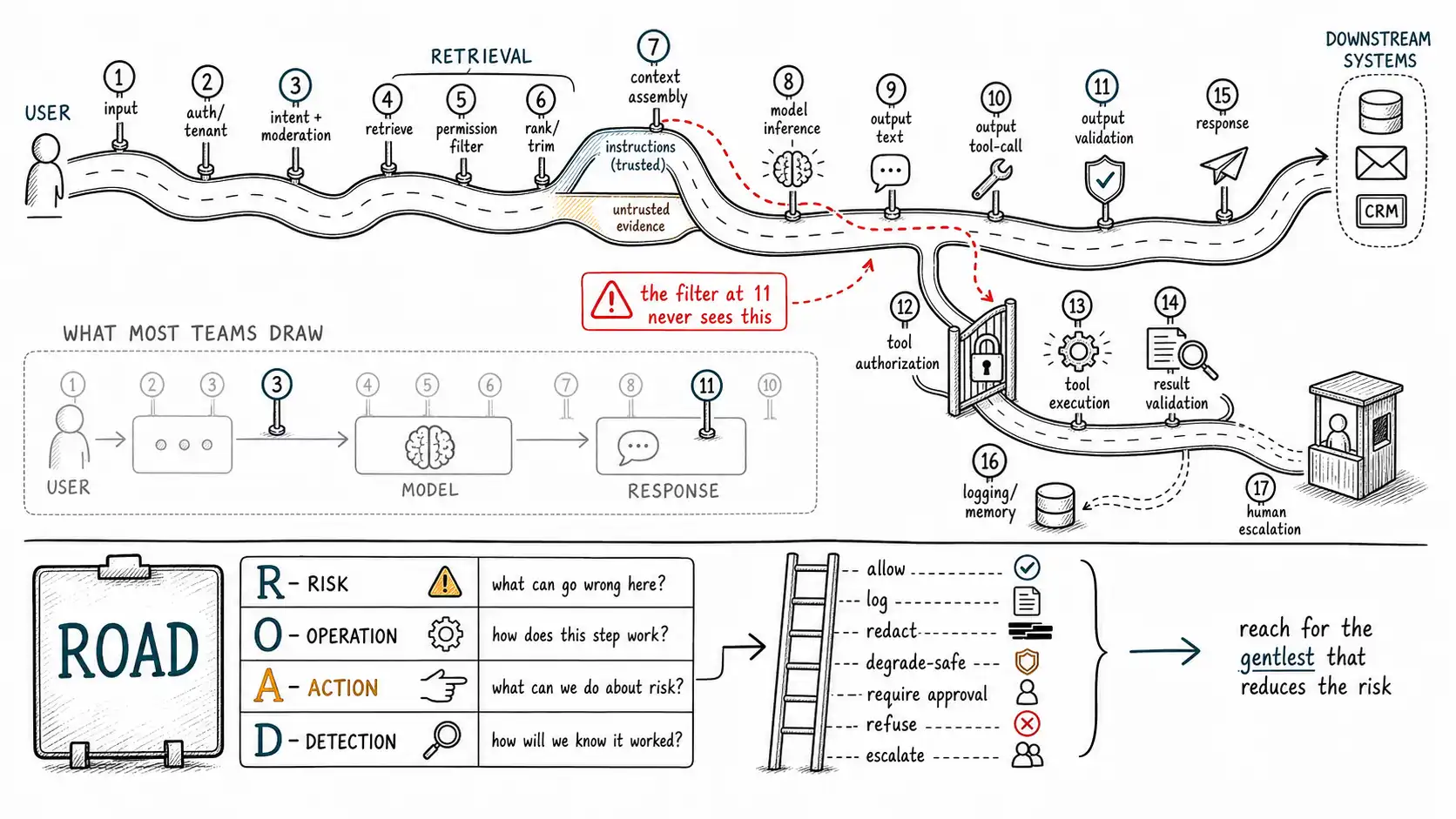
Every operation is a potential control point: and a potential gap
Walk the boundary and name what can go wrong at each operation, mapped to the OWASP LLM Top 10 where it applies.
| # | Operation | Representative risk | OWASP / concern |
|---|---|---|---|
| 1 | User input | Malicious or malformed payload | LLM01 Prompt Injection |
| 2 | Auth / tenant | Wrong identity, cross-tenant access | Security |
| 3 | Intent + input moderation | Overblock; jailbreak slips through | Safety / LLM01 |
| 4-6 | Retrieval | Unauthorized documents fetched | LLM02, LLM08 |
| 5 | Permission filter | Tenant A reads tenant B's chunks | LLM02 Sensitive Info Disclosure |
| 7 | Context assembly | Untrusted retrieved text treated as instruction | LLM01 (indirect) |
| 8 | Model inference | Trained refusal jailbroken | Safety |
| 9 | Output text | Toxic, leaking, or fabricated content | LLM09 Misinformation, LLM02 |
| 10 | Output tool call | Model requests an unauthorized action | LLM06 Excessive Agency |
| 11 | Output validation | Malformed JSON breaks downstream | LLM05 Improper Output Handling |
| 12 | Tool authorization | Action allowed beyond user's right | LLM06 |
| 13 | Tool execution | Irreversible side effect, no rollback | LLM06 |
| 14 | Result validation | Tool returns poisoned data into context | LLM01 (second-order) |
| 15 | Response | Policy-violating content reaches user | Safety / Policy |
| 16 | Logging / memory | PII written to logs; poisoned memory | LLM02, LLM04 |
| 17 | Human escalation | No path for the case the system should not decide | Compliance / reliability |
The point of the table is not that you need seventeen controls. Most products do not exercise every operation, a read-only knowledge bot has no tool execution, so operations 10-14 collapse. The point is that you must know which operations your system has before you can decide which need controls, and you must place each control at the operation where its risk lives, not at the operation that is convenient to instrument.
ROAD: matching the control to the operation
The boundary tells you where operations are. ROAD tells you, for any risk you are worried about, which operation owns it and what to put there. It is four questions, and the discipline is to answer them in order and refuse to skip to "Action" before you have nailed "Risk" and "Operation", because skipping is how you get a control at the wrong place.
**R: Risk. ** Name the specific harm or failure, concretely enough that you could write a test for it."Unsafe output" fails this test; you cannot write a test for it."The assistant issues a refund the requesting user is not entitled to" passes; you can write that test. The discipline of naming the risk concretely is also the discipline that reveals which of the five concerns (Chapter 2) it is, and therefore what kind of control is even appropriate.
**O: Operation. ** Locate where in the boundary the risk actually occurs. This is the step teams skip, and it is the step that determines everything. The refund risk does not occur at input (the request may be perfectly polite) or at output text (the prose is clean); it occurs at operations 10, 12, 13, the tool call, its authorization, its execution. Get the operation wrong and every later step is wasted: a brilliant control at the wrong operation reduces no risk.
**A: Action. ** Decide what the control does when risk is detected at that operation. The available actions form a ladder from least to most disruptive, and the central thesis of this book is to reach for the gentlest action that actually reduces the risk:
- **Allow: ** let it through (the default for safe input; the goal is to keep this the common case).
- **Log: ** allow but record for monitoring and later analysis.
- **Redact / transform: ** modify the artifact to remove the risky element while preserving the useful part (strip the PII, keep the answer).
- **Degrade-safe: ** return a reduced but still useful response (answer the general question, decline the specific dangerous detail).
- **Require approval: ** hold the action for a human or a stronger check before it commits.
- **Refuse: ** decline entirely (the last resort, not the first reflex).
- **Escalate: ** route the whole case to a human or a different system.
A wall only knows the two ends of this ladder: allow or refuse. A guardrail uses the middle. Most of the overblocking in real products is the reflex of jumping to "refuse" when "redact, " "degrade-safe, " or "require approval" would have reduced the risk while keeping the road usable.
**D: Detection. ** Define how you know the control fired, whether it worked, and whether it was bypassed. A control with no detection is unfalsifiable, you cannot tell a working guardrail from a placebo. Detection has three parts: a signal the control emits when it fires (logged with enough context to reconstruct the decision), a metric aggregating those signals (overblock rate, intervention rate, bypass attempts), and an audit record sufficient for compliance and incident reconstruction. If you cannot say how you would detect that this control failed, you have not finished designing it.
Run ROAD as a structured artifact, not a vibe:
# ROAD record for one guardrail
guardrail: refund_authorization
risk:
description: "Assistant issues a refund the requesting user is not entitled to"
concern: security # also: compliance (audit), reliability (trusts untrusted text)
severity: high # irreversible-ish financial side effect
operation:
boundary_step: [10, 12, 13] # tool call -> authorization -> execution
not_at: [3, 11] # NOT solvable at input or output-text moderation
action:
primary: require_approval # above threshold -> human
rules:
- "amount <= verified_entitlement AND amount <= auto_limit -> allow + log"
- "amount > auto_limit -> require_approval"
- "user not verified as order owner -> refuse + log"
ladder_position: require_approval # deliberately not 'refuse' for the common case
detection:
signal: "every refund tool call logs {user_id, order_id, amount, entitlement, decision}"
metrics: [auto_approved_rate, human_approval_rate, refused_rate, dispute_rate]
audit: "immutable record retained per finance policy"
bypass_test: "redteam/refund_injection_suite.yaml must pass in CI"Notice what this record makes impossible. You cannot claim this risk is "handled by the output filter, " because the record names the operation as the tool boundary, not output text. You cannot claim it is handled because "the model is instructed not to, " because the action is a deterministic authorization rule, not a prompt. And you cannot claim it works without evidence, because the detection block names the exact signal, metrics, and bypass test. ROAD turns "we have guardrails" into a falsifiable, reviewable, testable claim, which is the whole difference between engineering and theater.
The boundary is also a budget
Every control costs something: latency, money, engineering maintenance, and, the cost teams forget, overblocking risk and false-confidence risk. You cannot afford a maximal control at all seventeen operations, and you should not want to. ROAD applied across the boundary is therefore also a prioritization: place strong controls where the risk is severe and the operation is the true owner (the tool boundary for an agent with write access), lighter controls where the risk is mild (logging at output for a read-only bot), and no control where the operation does not exist or carries no meaningful risk. The NIST AI RMF frames this as risk management, not risk elimination: you allocate finite control budget against a mapped set of risks, accept some residual, and make the residual observable. A team that tries to control everything ends up with the overblocking product and an unmaintainable tangle of redundant filters; a team that controls nothing past the three-box drawing ships the refund attack. The boundary map plus ROAD is how you spend the budget on the operations that actually carry risk.
This chapter closes Movement I. We have the failure set (Chapter 1), the vocabulary of concerns (Chapter 2), and now the boundary and the procedure for placing controls (Chapter 3). Everything that follows is ROAD applied to one operation at a time: policy (the rules a control enforces), input, retrieval, output, and tools, then how to test, monitor, and operate the whole assembly.
Chapter summary
The three-box drawing, user, model, response, is why guardrails get placed wrong; it shows two boundaries and hides the dozen-plus operations between them. Drawn honestly, a tool-using retrieval product passes through seventeen operations: input, auth/tenant, intent+moderation, retrieval request, permission filter, search, context assembly, inference, output text, output tool call, output validation, tool authorization, tool execution, result validation, response, logging/memory, and human escalation. A risk lives at an operation, and a control not at that operation cannot reduce that risk, which is why the introduction's refund attack (operations 10/12/13) was untouchable by an output filter at operation 11. Each operation maps to representative risks and OWASP categories, but the product only needs controls at the operations it actually has. ROAD matches control to operation in four ordered questions: Risk named concretely enough to test (which also reveals the concern), Operation located in the boundary (the step teams skip and the one that determines everything), Action chosen from a ladder, allow, log, redact/transform, degrade-safe, require approval, refuse, escalate, reaching for the gentlest that reduces the risk rather than reflexively refusing, and Detection specifying the signal, metrics, and audit record without which a control is unfalsifiable. Recorded as a structured artifact, a ROAD entry makes false claims of coverage impossible. Because every control costs latency, money, maintenance, and overblocking risk, ROAD across the boundary is also a budget: strong controls where risk is severe and the operation truly owns it, light controls where risk is mild, none where the operation does not exist, risk management, not risk elimination.