Refusal Is the Last Resort
> **Working claim: ** A bare refusal is the bluntest action a guardrail has, and reaching for it first is what makes products feel like walls.

Key Takeaways
- Refusal Is the Last Resort treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** A bare refusal is the bluntest action a guardrail has, and reaching for it first is what makes products feel like walls. The skill is safe completion, answering the safe part of a risky request, transforming rather than blocking, and explaining the boundary without leaking the policy that defines it.
The refusal reflex
The action ladder from Chapter 3 ran from allow to escalate, with refuse near the bottom, not at the top, not the default, the last resort. Yet refusal is the action most teams reach for first, because it is the easiest to implement (return a canned message), the easiest to defend in a review ("we blocked it"), and the most legible on a dashboard. The result is the wall: a product that, the moment it detects anything near a boundary, stops the user cold with "I can't help with that."
The refusal reflex is expensive in a way that does not show up where teams look. Recall the asymmetry from Chapter 1: refusals are paid for in invisible churn. But there is a second cost that is specific to bad refusals. A refusal that is wrong (the harmless billing question) teaches the user the product is unreliable, so they stop using it for the things it can do. A refusal that is cold (the grieving user) is not just unhelpful but actively harmful in the situations that most need care. And a refusal that over-explains leaks the policy ("I can't help because that matches our fraud-pattern P-17") hands an attacker a map of exactly what to avoid saying. Refusal is not a safe default; it is a high-cost action that should be reserved for the cases where any fulfillment is the harm.
The alternative is the central craft of this chapter: most "risky" requests are not all-or-nothing. They have a safe part and a risky part, and the guardrail's job is to deliver the safe part while declining the risky part, to complete safely rather than refuse entirely.
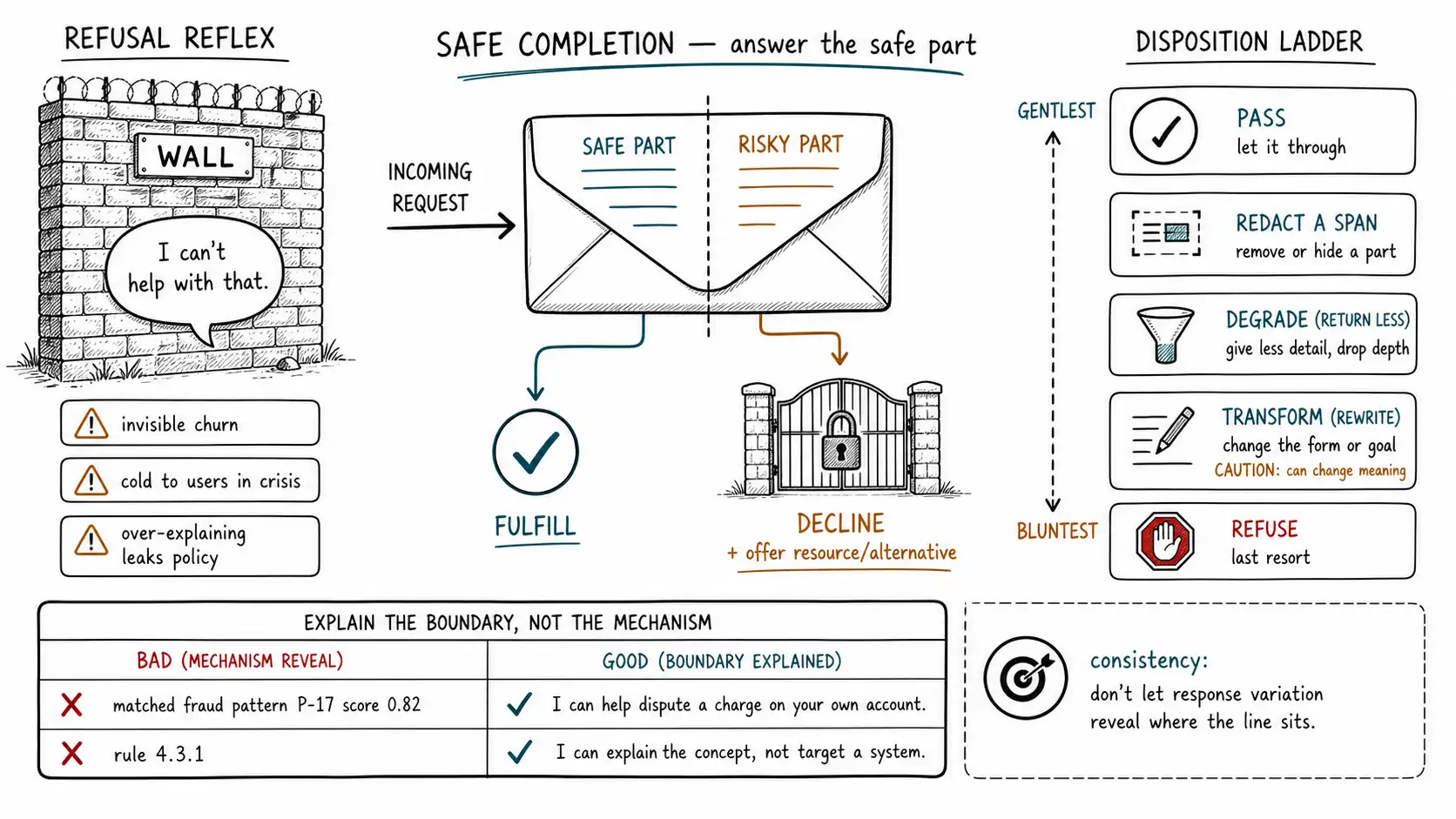
Safe completion: answer the safe part
Safe completion is the disposition where the system fulfills as much of the request as it safely can, declining only the specific risky element. It is the practical expression of the "keep the road usable" thesis at the output boundary, and it is what separates a guardrail from a wall.
Consider the canonical hard cases and how safe completion handles each:
- **The medical dosage question. ** "What's the maximum safe dose of acetaminophen?" A wall refuses ("I can't give medical advice"). Safe completion provides the widely-published general information, frames it as general and not personalized medical advice, notes the serious risk of overdose, and points to a clinician or poison-control resource for the individual case. The user gets real help with the informational part; the system declines to be the user's personal physician.
- **The security research question. ** "How does this class of vulnerability work?" A wall refuses ("I can't help with hacking"). Safe completion explains the concept at the level any security textbook would, declines to produce a working weaponized exploit against a specific target, and stays useful to the legitimate defender who is the overwhelmingly likely asker.
- **The grieving user. ** A wall returns a cold refusal template. Safe completion (here, escalation-flavored) responds with empathy, does not pretend to be a therapist, and surfaces crisis resources, the safe-completion-plus-resources disposition the policy in Chapter 4 specified.
- **The partial-PII request. ** "Show me everyone's salary" from a user authorized to see only their team. A wall refuses the whole request. Safe completion returns the authorized subset (the team's salaries the user may see) and clearly notes that the broader request was scoped down by permissions, useful answer, enforced boundary.
The unifying move is decomposition: separate what is safe to fulfill from what is not, fulfill the former, decline the latter with a useful pointer. This is harder than a canned refusal, it requires the system to understand the request well enough to split it, but it is the difference between a product users trust and a product users route around.
def respond(request, ctx) -> Response:
risk = assess_risk(request, ctx) # tier + intent + policy disposition (Ch.4/5)
if risk.disposition == "allowed":
return answer(request, ctx)
if risk.disposition == "disallowed":
# Even here: safe-complete, do not stonewall. Decline the act, stay human.
return safe_completion(
decline=risk.specific_risky_element,
offer=risk.safe_alternative_or_resource, # never an empty "I can't help"
explanation_level="boundary_only", # see policy-leak section below
)
if risk.disposition == "restricted":
# The core skill: fulfill the safe part, scope down the rest.
safe_part, declined_part = decompose(request, risk)
return safe_completion(
fulfill=answer(safe_part, ctx),
decline=declined_part,
offer=risk.safe_alternative_or_resource,)
if risk.disposition == "escalated":
return escalate_with_care(request, ctx, resources=risk.resources)
# Refusal is the genuine last resort: any fulfillment is the harm.
return minimal_safe_refusal(reason_class=risk.reason_class)The function reads as a ladder deliberately: every branch above the last tries to give the user something useful, and only the final branch is a bare refusal, and even it is "minimal safe, " not a lecture.
Transformation over blocking
Closely related to safe completion is transformation: when the output has a fixable defect, modify it rather than block it. This is the output-side complement to the revise and redact dispositions from Chapter 8. If the model's answer contains an unsupported claim, strip the claim and return the supported remainder. If it contains a piece of PII the user is not entitled to, mask that span and return the rest. If it is slightly off-tone for a sensitive situation, soften it. Transformation keeps the useful content while removing the risky element, which is almost always better for the user than discarding the whole response.
Transformation has a real risk that must be named: **rewriting can change meaning or introduce errors. ** A system that aggressively rewrites model outputs can turn a correct answer into a subtly wrong one, or sand off a caveat the user needed. So transformation is governed by two rules. First, transform minimally, remove or mask the specific risky span, do not regenerate the whole answer to "make it safe, " because regeneration is a new generation with new failure modes. Second, transformation that could change factual meaning (as opposed to redaction, which removes) should be flagged or avoided on high-stakes content; it is safer to degrade (return less) than to rewrite (return something different that the model did not actually produce). The hierarchy, gentlest to bluntest: pass → redact a span → degrade (return less) → transform (rewrite, with caution) → refuse.
Explaining the boundary without leaking the policy
The hardest part of a good refusal or safe completion is the explanation, because two pressures pull against each other. Users deserve to understand why the system declined, both for usability (so they can rephrase a legitimate request) and increasingly for compliance (some regimes expect meaningful explanation of automated decisions). But a detailed explanation of why is a detailed explanation of how to get around it, every specific reason you give an attacker is a rule they now know to avoid triggering.
The resolution is **explain the boundary, not the mechanism. ** Tell the user the category of limit they hit and what they can do, without disclosing the policy internals, the classifier scores, or the specific trigger.
| Bad (leaks policy) | Good (explains boundary) |
|---|---|
| "Blocked: your message matched fraud pattern P-17 with score 0.82." | "I can help you dispute a charge on your own account, let me walk you through that." |
| "I can't discuss this because rule 4.3.1 prohibits security topics." | "I can explain how this kind of issue works in general; I can't help target a specific system." |
| "Refused: self-harm classifier triggered." | A warm, human response with crisis resources, no mention of classification. |
The good column does three things at once: it is honest about the boundary, it redirects the user toward the legitimate path that is available (keeping the road usable), and it reveals nothing an attacker can use to tune their next attempt. This is also where consistency matters: an attacker probing your boundaries learns the most from differences in your responses, so safe-completion messages for a given category should be stable and not reveal, through their variation, exactly where the line sits.
Refusal still has a place: and a quality bar
None of this means never refuse. Some requests have no safe part: assistance with mass-casualty weapons, child sexual abuse material, a request whose only purpose is harm. For these, refusal is correct, and trained model refusal, shaped by approaches like Constitutional AI and reinforced by the system's policy layer, is doing the right thing. The point of this chapter is not to weaken those refusals; it is to stop the refusal reflex from firing on the vast majority of requests that have a safe part, because that reflex is what makes a product a wall.
When you do refuse, hold it to a quality bar: it should be brief, it should not lecture, it should not leak the policy, it should offer a genuine alternative or resource where one exists, and, critically, it should be measured. The refusal rate, broken down by category and by whether the refused requests were actually harmful, is one of the most important numbers in the whole guardrail program (Chapter 12), because a rising refusal rate on legitimate categories is the overblocking failure becoming visible. A team that treats refusal as the last resort, decomposes risky requests into safe and unsafe parts, transforms rather than blocks where it can, explains boundaries without leaking policy, and measures its refusals, that team builds guardrails. A team that reaches for the canned "I can't help with that" builds a wall and wonders why users leave.
Chapter summary
A bare refusal is the bluntest action a guardrail has, yet teams reach for it first because it is easy to implement, easy to defend in review, and legible on a dashboard, producing the wall. Refusal is expensive in invisible churn, and bad refusals add specific costs: wrong refusals teach users the product is unreliable, cold refusals harm the people who most need care, and over-explained refusals leak a map of the policy to attackers. The alternative craft is safe completion: decompose a risky request into its safe and risky parts, fulfill the safe part, decline only the risky element with a genuine alternative or resource, the medical question answered generally with a clinician pointer, the security concept explained without a weaponized exploit, the grieving user met with empathy and crisis resources, the over-broad data request scoped to what the user may see. Pair it with transformation over blocking, redact or degrade a defective output rather than discard it, governed by two rules: transform minimally (mask the span, do not regenerate) and prefer degrading (return less) over rewriting (return something different) on high-stakes content, following the gentlest-to-bluntest hierarchy pass → redact → degrade → transform → refuse. Explain the boundary, not the mechanism: tell the user the category of limit and what they can do, never the classifier score, the rule number, or the specific trigger, and keep safe-completion messages consistent so response variation does not reveal where the line sits. Refusal still belongs where any fulfillment is the harm, and trained refusal does that job well, but hold every refusal to a quality bar, brief, non-lecturing, non-leaking, alternative-offering, and measured, because the refusal rate on legitimate categories is how the overblocking failure finally becomes visible.