The Two-Sided Failure
> **Working claim: ** Overblocking and underblocking are not two ends of a single dial you tune toward a happy medium.

Key Takeaways
- The Two-Sided Failure treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** Overblocking and underblocking are not two ends of a single dial you tune toward a happy medium. They are two independent failures that a system can suffer at the same time, and a guardrail strategy that treats safety as one slider will always be wrong in both directions at once.
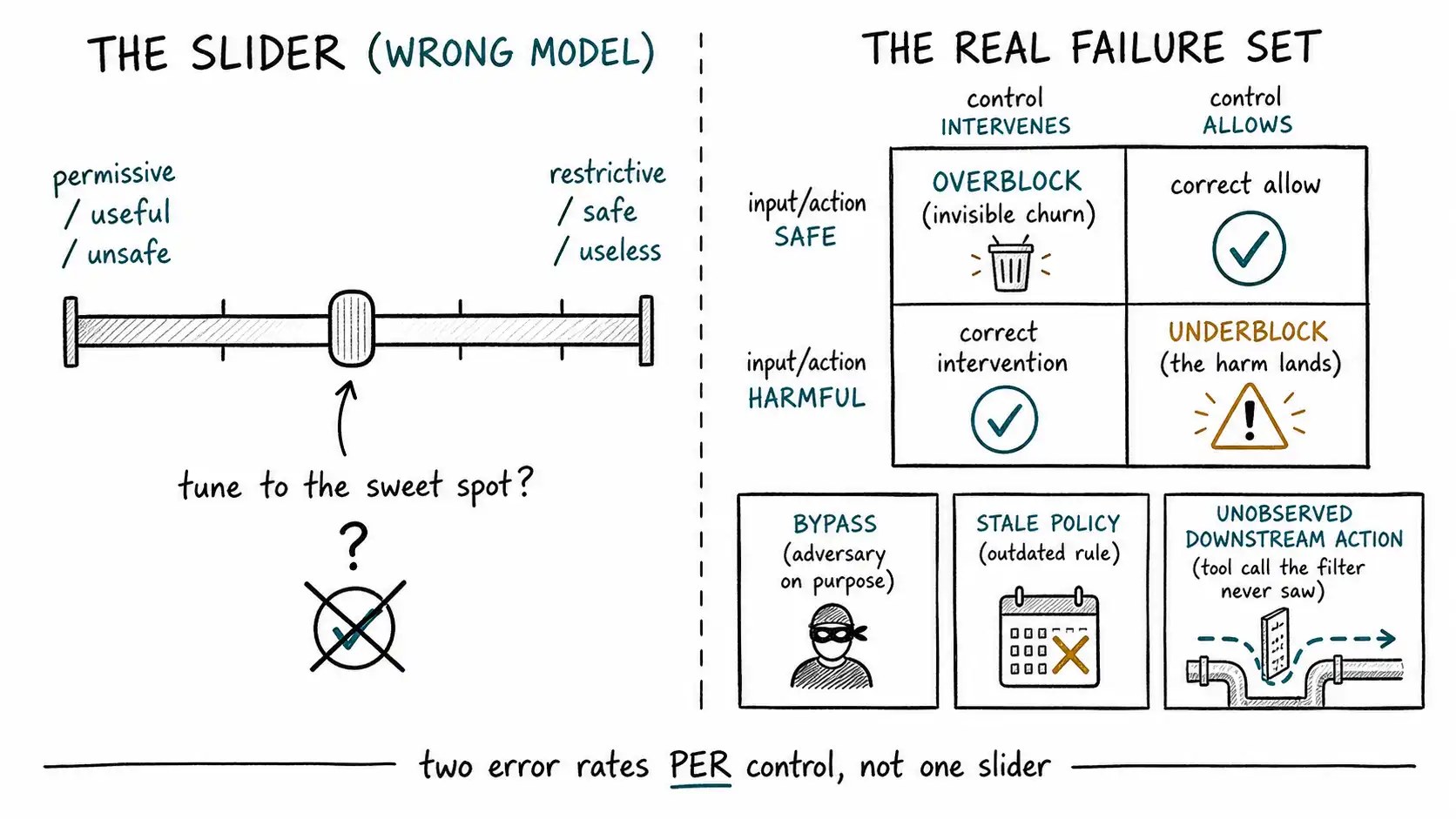
The slider that does not exist
Ask a team how strict their guardrails are and you will usually get an answer shaped like a slider."We're pretty conservative." "We've loosened it since launch." "We're somewhere in the middle." The slider runs from permissive on one end to restrictive on the other, and the implicit model is that you slide it left and the product gets more useful and less safe, slide it right and it gets safer and less useful. Tuning, on this view, is finding the sweet spot.
The slider is a comforting fiction, and the support assistant from the introduction is the proof. That system was simultaneously too restrictive, it refused a paying customer's legitimate billing question, and too permissive, it executed an attacker's injected refund. On a slider, those are opposite positions. You cannot be at both ends at once. Yet the system was, because the thing being measured on each end was not the same thing. The refusal of "dispute a charge" was a false positive on an input text classifier. The refund execution was a false negative on a control that did not exist at the tool-call boundary. They were two different controls, watching two different operations, failing in two different ways. There is no single slider position that fixes both, because they are not on the same slider.
This is the first thing to internalize, and it is the reason "add guardrails" is bad advice. Safety is not a scalar. It is a set of controls, each at a specific operation, each with its own behavior under both legitimate and adversarial input. A real guardrail program has a separate false-positive rate and false-negative rate per control, and the work is not to find one magic strictness, it is to drive each control's two error rates down together by making the control more precise, not more aggressive.
Two errors, defined precisely
Borrow the language of classification, because at bottom every guardrail is making a decision: this input, this output, this action, allow it, or intervene. There are two ways to be wrong.
Overblocking is a false positive: the control intervenes on something that was actually fine. The harmless billing question gets refused. The doctor's legitimate question about a controlled substance dosage gets a "I can't help with that." The security researcher's question about how a vulnerability works gets stonewalled. The user pastes their own code containing the word "exploit" in a variable name and the assistant clams up. Each of these is the guardrail mistaking a friend for a foe.
Underblocking is a false negative: the control fails to intervene on something that was actually harmful. The injected instruction executes. The PII leaks into a log. The agent deletes the wrong records. The model confidently invents a drug interaction that does not exist and a user acts on it. Each of these is the guardrail waving through a foe it should have caught.
The costs are asymmetric and they accrue to different people. Overblocking costs are paid by legitimate users and by the business: abandoned sessions, support escalations, churned accounts, the slow erosion of trust as users learn the product is unreliable and route around it. These costs are real but diffuse, and they are usually invisible to the safety team, because a refused user does not file a safety report, they just leave. Underblocking costs are paid when the rare harmful event lands: a regulatory finding, a breach, a fraudulent transaction, a harmed user, a headline. These costs are concentrated, occasional, and highly visible.
That asymmetry in visibility is what bends teams toward overblocking. Underblocking failures get postmortems; overblocking failures get silent churn. So the rational-seeming move, after any incident, is to tighten, add a category to the blocklist, lower a threshold, broaden a refusal. Each tightening reduces a visible underblock risk and increases an invisible overblock cost. Repeat this for a year of incident-driven tuning and you arrive at a product that refuses a third of legitimate requests and still has open attack paths, because tightening the text classifier never touched the tool-call boundary where the real risk lived.
| Control intervenes | Control allows | |
|---|---|---|
| Input/action was safe | Overblock (false positive), user friction, churn, eroded trust; invisible | Correct allow |
| Input/action was harmful | Correct intervention | Underblock (false negative), the harm lands; visible, occasional |
The table is the standard confusion matrix, and naming a guardrail's behavior in these four cells is the start of treating it as engineering. A control with no measured false-positive rate is a control whose overblocking you have decided not to see.
The four failure modes, and the two the slider hides
Overblock and underblock are the two failures everyone eventually notices. There are two more that the slider model cannot even represent, and they are the dangerous ones because they wear the costume of safety.
Stale policy is a guardrail enforcing a rule that no longer matches the world. The refund threshold was set at launch and the business has since changed it, but the guardrail still blocks at the old number, or worse, allows at it. The prohibited-topics list was written for last year's product and now blocks a feature the company shipped. A control is not safe because it was correct once; it is safe only as long as the policy it enforces is current, and policy drifts.
Unobserved downstream action is the refund attack's category: the control exists, the control passes, and then something happens after the control that the control never saw. The output text was clean; the tool call was not. The answer was fine; the email it triggered was sent to the wrong tenant. The model's response was harmless; the cached version served to the next thousand users was poisoned. A guardrail that inspects one artifact while the harm flows through another is not a weak guardrail, it is a guardrail aimed at the wrong target.
Bypass is the adversary's category, and it is distinct from ordinary underblocking. Underblocking is the control failing on inputs drawn from the normal distribution. Bypass is an attacker deliberately constructing an input to defeat the control: the jailbreak that reframes the prohibited request as fiction, the prompt injection hidden in a retrieved document (OWASP LLM01: 2025), the encoding trick that slips past a keyword filter, the multi-turn escalation that assembles a harmful result one innocuous piece at a time. A control's average-case false-negative rate tells you almost nothing about its adversarial false-negative rate, and conflating the two is how teams ship a moderation classifier and believe they have addressed prompt injection.
These four, overblock, underblock, stale policy, unobserved downstream action, plus bypass as adversarial underblock, are the failure matrix this book returns to. A guardrail review that only asks "is it strict enough?" can see at most one of them.
| Failure mode | What it is | Who notices | Slider can see it? |
|---|---|---|---|
| Overblock | Intervenes on safe input | Users (silently leave) | Only one end |
| Underblock | Misses harmful input (average case) | Postmortem after the harm | Only other end |
| Bypass | Adversary defeats the control on purpose | Often nobody, until exploited at scale | No |
| Stale policy | Control enforces an outdated rule | Nobody, until it misfires | No |
| Unobserved downstream action | Harm flows through an artifact the control never inspects | Reconciliation, audit, or never | No |
Why model-level refusal is not enough
A reasonable objection at this point: modern models are trained to refuse harmful requests. Techniques like Constitutional AI shape the model to decline categories of harm without a human writing every rule. So why not let the model's own trained refusal be the guardrail?
Because trained refusal is a property of the model's text generation, and most of the failure modes above do not live in text generation. The model's trained refusal will not stop a prompt injection that arrives inside a retrieved document and reframes the task as legitimate, the model is not refusing because, from its perspective, it is being helpful to an authorized instruction. It will not enforce that the refund stay under the user's entitlement, because the model has no access to the user's entitlement; that fact lives in your database, not its weights. It will not redact the PII that the model itself correctly included because the user asked for their own record, which then flows into a shared log. It will not prevent the tool call with valid-looking but unauthorized arguments. It will not keep a policy current after the business changes it.
Trained refusal is one useful layer, the model declining to write the obvious harmful thing, and it handles a real and important class of direct misuse. But it is a layer, not the system. It operates at exactly one operation (text generation), it is probabilistic rather than deterministic, it can be socially engineered (jailbroken), and it knows nothing about your authorization model, your data boundaries, your downstream side effects, or your policy version. Treating the model's personality as the safety architecture is the most common form of the wall mistake, because it is the most invisible: there is no classifier to point at, just a belief that the model "won't do that." The NIST AI RMF frames this correctly when it treats trustworthiness as a property to be managed across the system lifecycle, governed, mapped, measured, and managed, rather than a property emitted by a single component.
The shape of the fix
If the slider is the wrong model, what is the right one? It is the same shape as the system: layered, with a control at each operation where a specific risk lives, each control measured on both error rates, none of them asked to be the whole defense.
The support assistant, rebuilt this way, looks nothing like the original. The input layer no longer blocks on keywords; it classifies intent (billing question vs. refund request vs. abuse) and routes accordingly, so "dispute a charge" reaches the billing-answer path it was always meant for. The refund tool is no longer something the model can call freely on the strength of its own reasoning; it is gated by a policy engine that checks the requesting user's verified entitlement, caps the amount, and requires human approval above a threshold, so the injected instruction produces, at most, a queued request a human rejects, not a completed refund. The output layer still moderates prose, but it is no longer asked to catch the dangerous tool call, because that is not where the tool call is. And every one of these controls emits an audit record, so the overblock rate on billing questions and the rejected-refund rate on the tool boundary are both numbers on a dashboard, not invisible costs.
That is the work. Not a stricter slider, a set of precise, layered, measured controls, each answering ROAD: which risk, which operation, which action, which detection. The rest of this book builds them.
Chapter summary
Safety is not a single slider from permissive to restrictive; that model cannot represent the most common real outcome, which is overblocking and underblocking at the same time because they are failures of different controls at different operations. Define the two errors precisely as a confusion matrix per control: overblocking is a false positive (the control intervenes on safe input, paid for in invisible user churn) and underblocking is a false negative (the control misses harmful input, paid for in rare, visible, concentrated harm). The asymmetry, underblocks get postmortems, overblocks get silent churn, biases teams toward incident-driven tightening that raises overblock cost without closing the real attack path. Beyond the two visible failures sit three the slider cannot see: bypass (an adversary defeating a control on purpose, whose adversarial false-negative rate is unrelated to its average-case rate), stale policy (a control enforcing an outdated rule), and unobserved downstream action (harm flowing through an artifact the control never inspects, the refund tool call the text moderator could not see). Model-level trained refusal is one useful layer for direct text misuse but cannot enforce authorization, data boundaries, downstream side effects, or current policy, so it is a layer, not the architecture. The fix is structural, not a stricter slider: a precise control at each operation where a specific risk lives, each measured on both error rates, each emitting an audit record so both failure types become numbers instead of surprises.