Risk Tiering and Intent
> **Working claim: ** The strength of a guardrail should scale with the stakes of the action and the confidence in the user's intent, not with the scariness of a keyword.

Key Takeaways
- Risk Tiering and Intent treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** The strength of a guardrail should scale with the stakes of the action and the confidence in the user's intent, not with the scariness of a keyword. Treating every request as equally risky is how you get a product that interrogates a customer asking about store hours and waves through an agent about to delete a database.
The keyword tax
A composited pattern that shows up in nearly every first-generation guardrail. The team builds a blocklist of scary words and phrases: "suicide, " "bomb, " "hack, " "kill, " "exploit, " "weapon, " "drug." Any request containing one gets the heavy treatment: refusal or a hard escalation. It feels responsible. It also taxes exactly the wrong requests. A user asks "how do I kill a background process on Linux" and gets refused. A nurse asks about a drug interaction and gets stonewalled. A security engineer pastes a stack trace containing the word "exploit" and the assistant goes silent. A grieving user types "I keep thinking about my friend who died by suicide", a person who needs care, and gets a cold refusal template, which is the single worst possible response. Meanwhile, the agent that can issue refunds, send emails, and modify records operates with no per-action scrutiny at all, because none of the dangerous actions happen to contain a scary word.
This is the keyword tax: guardrail strength allocated by surface vocabulary rather than by stakes. It overblocks benign requests that share words with dangerous ones, it underblocks dangerous actions that use ordinary words, and it gives the team a false sense of coverage proportional to the length of the blocklist. The fix is to allocate guardrail strength along two axes that actually predict harm: how high are the stakes of what is being requested, and how confident are we in the user's intent and authorization. Neither axis is the presence of a word.
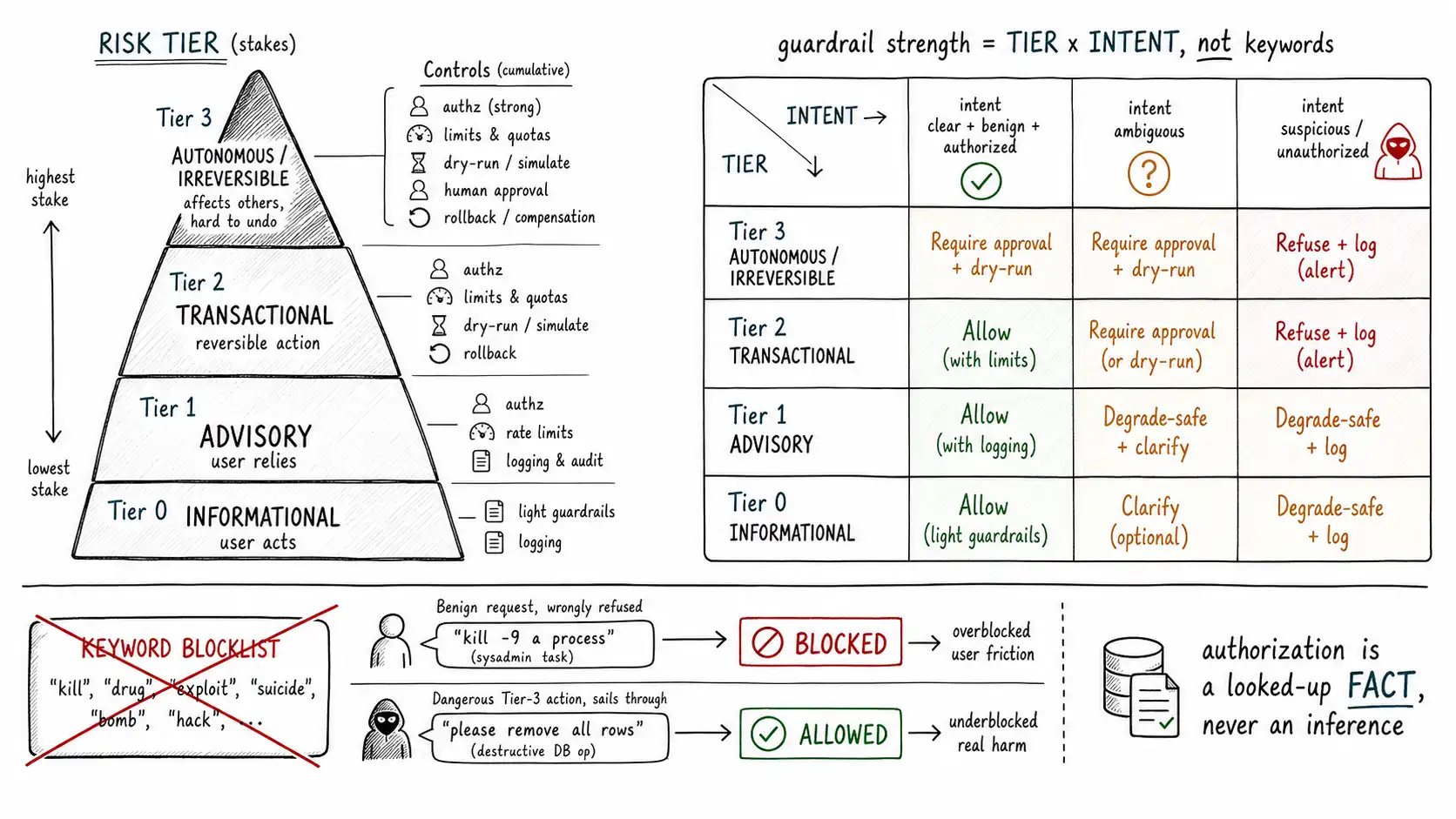
The risk-tier ladder: stakes, not topics
The first axis is stakes, the cost if this request is fulfilled wrongly. The useful structure is a ladder from informational to autonomous, because the cost of a mistake escalates sharply as you climb, and so should the control.
- **Tier 0: Informational. ** The system provides information; the user acts (or not) entirely on their own."What are your store hours?" "Explain how compound interest works." A wrong answer here is a reliability problem, recoverable by the user noticing. Controls: light. Validate for gross misinformation, log, move on. Over-controlling tier 0 is pure overblocking.
- **Tier 1: Advisory. ** The system gives a recommendation the user is likely to rely on for a consequential decision."Should I refinance?" "Is this mole concerning?" A wrong answer can lead to real harm because of the user's reliance, even though the system took no action. Controls: evidence requirements, disclaimers, scope limits, escalation paths to a qualified human. This is the tier where degrade-safe earns its keep, answer the general question, decline the personalized recommendation that crosses into regulated advice.
- **Tier 2: Transactional. ** The system takes a reversible action with a bounded blast radius on behalf of the user. Issue a small refund, send a draft email for approval, update a low-stakes record. A wrong action here has a cost but is recoverable. Controls: authorization, argument validation, limits, logging.
- **Tier 3: Autonomous / irreversible. ** The system takes an action that is hard or impossible to undo, or that affects others, or that is large: delete data, transfer significant funds, send a message to a customer, deploy code, change permissions. A wrong action here is a genuine incident. Controls: deterministic authorization, hard limits, dry-run, human approval gates, full audit, and the ability to roll back.
The ladder reframes the whole guardrail-strength question. You are not asking "does this contain a scary word?" You are asking "what tier is the requested action, and is my control strength matched to that tier?" The Linux "kill a process" question is tier 0; it should sail through. The database deletion is tier 3; it should hit every control on the list. The keyword blocklist had these exactly backwards because it read words instead of stakes. The NIST AI RMF's Map function is essentially this exercise done rigorously: characterize the system's actions and contexts by the risk they carry, so that the Measure and Manage functions can be allocated where the risk is.
risk_tiers:
tier_0_informational:
blast_radius: "user-only, advisory, user acts independently"
default_controls: [misinformation_check, log]
overblock_warning: "heavy controls here are pure friction"
tier_1_advisory:
blast_radius: "user relies on recommendation for consequential decision"
default_controls: [evidence_required, disclaimer, scope_limit, human_escalation_path]
tier_2_transactional:
blast_radius: "reversible action, bounded, on user's own assets"
default_controls: [authorization, argument_validation, limits, log]
tier_3_autonomous_irreversible:
blast_radius: "irreversible / affects others / large"
default_controls: [deterministic_authz, hard_limits, dry_run, human_approval, audit, rollback]The intent axis: confidence and authorization
Stakes are half the picture. The other half is how confident you are about who is asking and what they actually want. Two requests at the same tier deserve different treatment if one comes from a verified, authorized user with an unambiguous intent and the other comes from an unauthenticated session with an ambiguous or suspicious phrasing.
Intent classification is the mechanism here, and it must be done carefully, because intent classification is itself a guardrail with its own overblock and underblock rates. The goal is not to guess whether the user is "good" or "bad", that framing produces the keyword tax. The goal is to route the request to the right policy disposition with appropriate confidence. A few principles:
- **Classify intent, not vocabulary. ** "I want to dispute a charge" and "how do I commit chargeback fraud" share vocabulary and have opposite intents. The classifier must read the request as a whole, ideally with the conversation and the user's authenticated context, not match tokens.
- **Confidence gates the action, not just the label. ** A high-confidence benign classification can proceed; a low-confidence classification near a sensitive boundary should degrade-safe or ask a clarifying question, not refuse."I'm not sure I understood, are you asking how to dispute a charge on your own account, or something else?" is a guardrail that keeps the road usable; a refusal is a wall.
- **Authorization is a fact, not an inference. ** Whether the requester owns the account, has the role, belongs to the tenant, these are looked up, not classified. Never let the intent classifier's probabilistic output substitute for a deterministic authorization check on a tier-2 or tier-3 action. This is the Chapter 2 security principle applied at intent: probabilistic routing is fine; probabilistic authorization is a breach waiting to happen.
The two axes combine into a decision matrix that replaces the keyword blocklist. The matrix maps (tier × intent confidence × authorization) to a disposition from Chapter 4.
| Tier | Intent clear & benign, authorized | Intent ambiguous | Intent suspicious / unauthorized |
|---|---|---|---|
| 0 Informational | Allow | Allow (light) | Allow + log (rarely worth more) |
| 1 Advisory | Allow + disclaimer | Clarify, then degrade-safe | Degrade-safe + log |
| 2 Transactional | Allow if authorized + log | Clarify; require confirmation | Refuse + log |
| 3 Autonomous | Require approval + audit | Require approval + audit | Refuse + log + alert |
Read the matrix and the keyword tax disappears. The grieving user's tier-0/tier-1 message about suicide is allowed with care and resources (degrade-safe plus a crisis path), never a cold refusal, because nothing about it is a tier-3 action or an unauthorized transaction. The database deletion is tier-3 and requires approval regardless of how politely it is phrased. The product stops interrogating store-hours askers and starts scrutinizing dangerous actions, which is the entire point.
A decision table you can actually run
The matrix is the policy; here is the mechanism, written so a reviewer can read it and an engineer can test it.
def disposition_for(request, ctx) -> Disposition:
tier = action_tier(request) # 0..3 by what is being asked/done
intent = classify_intent(request, ctx) # {label, confidence}
authorized = check_authorization(request, ctx) # deterministic fact, not inference
# Tier 2/3 require deterministic authorization regardless of intent confidence.
if tier >= 2 and not authorized:
return Disposition. REFUSE_LOG
if tier == 3:
# Never auto-execute irreversible actions on model say-so.
return Disposition. REQUIRE_APPROVAL_AUDIT
if tier == 2:
if intent.confidence < CLARIFY_THRESHOLD:
return Disposition. CLARIFY_THEN_CONFIRM
return Disposition. ALLOW_LOG
if tier == 1:
if intent.label == "regulated_advice":
return Disposition. DEGRADE_SAFE_DISCLAIMER
if intent.confidence < CLARIFY_THRESHOLD:
return Disposition. CLARIFY
return Disposition. ALLOW_DISCLAIMER
# tier 0
return Disposition. ALLOW_LOGTwo design choices carry the chapter's thesis. First, check_authorization is a deterministic fact lookup, and it gates tier-2/3 actions before any probabilistic reasoning, intent confidence can never unlock an action the user is not authorized to take. Second, the low-confidence branches reach for clarify and degrade-safe, not refuse. A clarifying question is the guardrail that keeps a confused-but-legitimate user on the road; a refusal is the wall that loses them. The blocklist had no concept of either, which is why it could only overblock or underblock.
The tier of the system, not just the request
One more application of tiering operates above individual requests: the whole feature sits in a tier, and that should set the baseline. A read-only internal knowledge bot is a tier-0/1 system; building tier-3 approval gates into it is wasted effort and friction. An agent with write access to production systems is a tier-3 system; shipping it with only input/output text moderation is the introduction's refund attack waiting to happen. The NIST AI RMF Map function asks for exactly this characterization at the system level, and it is the cheapest, earliest guardrail decision you can make: knowing your system's tier tells you which operations from Chapter 3's boundary you must control and how hard, before you write a single classifier. Get the system tier right and the per-request matrix has the right baseline; get it wrong and you will either drown a trivia bot in approval gates or hand an autonomous agent the keys with a sticky note that says "be careful."
Chapter summary
Allocating guardrail strength by scary keywords is the keyword tax: it overblocks benign requests that share vocabulary with dangerous ones, underblocks dangerous actions phrased in ordinary words, and rewards teams for the length of a blocklist rather than for matching control to risk. Replace it with two axes that actually predict harm. The first is the risk-tier ladder of stakes, informational (tier 0, light controls, over-controlling is friction), advisory (tier 1, evidence/disclaimer/escalation, where degrade-safe earns its keep), transactional (tier 2, authorization/validation/limits, reversible), and autonomous/irreversible (tier 3, deterministic authz, hard limits, dry-run, human approval, audit, rollback). The second is the intent axis of confidence and authorization: classify intent not vocabulary, let confidence gate the action by reaching for clarify and degrade-safe rather than refusal when uncertain, and treat authorization as a deterministic looked-up fact that gates tier-2/3 actions before any probabilistic reasoning, never letting intent confidence substitute for an authorization check. The two axes combine into a decision matrix that maps tier, intent confidence, and authorization to a Chapter 4 disposition, which dissolves the keyword tax: the grieving user gets care and resources, the polite database deletion still requires approval, the store-hours asker is left alone. Above individual requests, the whole feature sits in a tier; characterizing the system's tier (the NIST AI RMF Map function) is the cheapest early guardrail decision, setting which boundary operations to control and how hard before any classifier is written.