The Gatehouse
> **Working claim: ** Input controls are a gatehouse with several lanes, identity, intent, moderation, injection detection, abuse limiting, PII handling, not a single bouncer.

Key Takeaways
- The Gatehouse treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** Input controls are a gatehouse with several lanes, identity, intent, moderation, injection detection, abuse limiting, PII handling, not a single bouncer. The fatal mistakes are using one lane to do another's job, and trusting the same model to guard the input that will later answer it.
What the gatehouse is for, and what it is not
Before a request reaches the model, it passes through a set of controls at operations 1-3 of the boundary (Chapter 3): the input gatehouse. The gatehouse exists to do the cheap, deterministic, pre-model work that should never be left to the model, establish who is asking, what tenant they belong to, what they appear to want, whether the input is obviously abusive, and whether it carries data that must be handled specially. Done well, the gatehouse removes load from every downstream control and catches the easy attacks before they cost a model call.
It is equally important to be clear about what the gatehouse is not. It is not the whole defense. A common and dangerous belief is that a good input filter makes the rest of the system safe, that if you scan the user's message hard enough, nothing bad can happen. This is the wall mistake at the input boundary. The gatehouse cannot stop a prompt injection hidden in a document the system will retrieve later (Chapter 7), because that text never passed through the gatehouse. It cannot stop an unauthorized tool call (Chapter 10), because that happens after the model. It cannot stop the model from fabricating a fact (Chapter 8/9). The gatehouse is the first lane of a layered system, valuable precisely because it is cheap and early, not because it is sufficient.
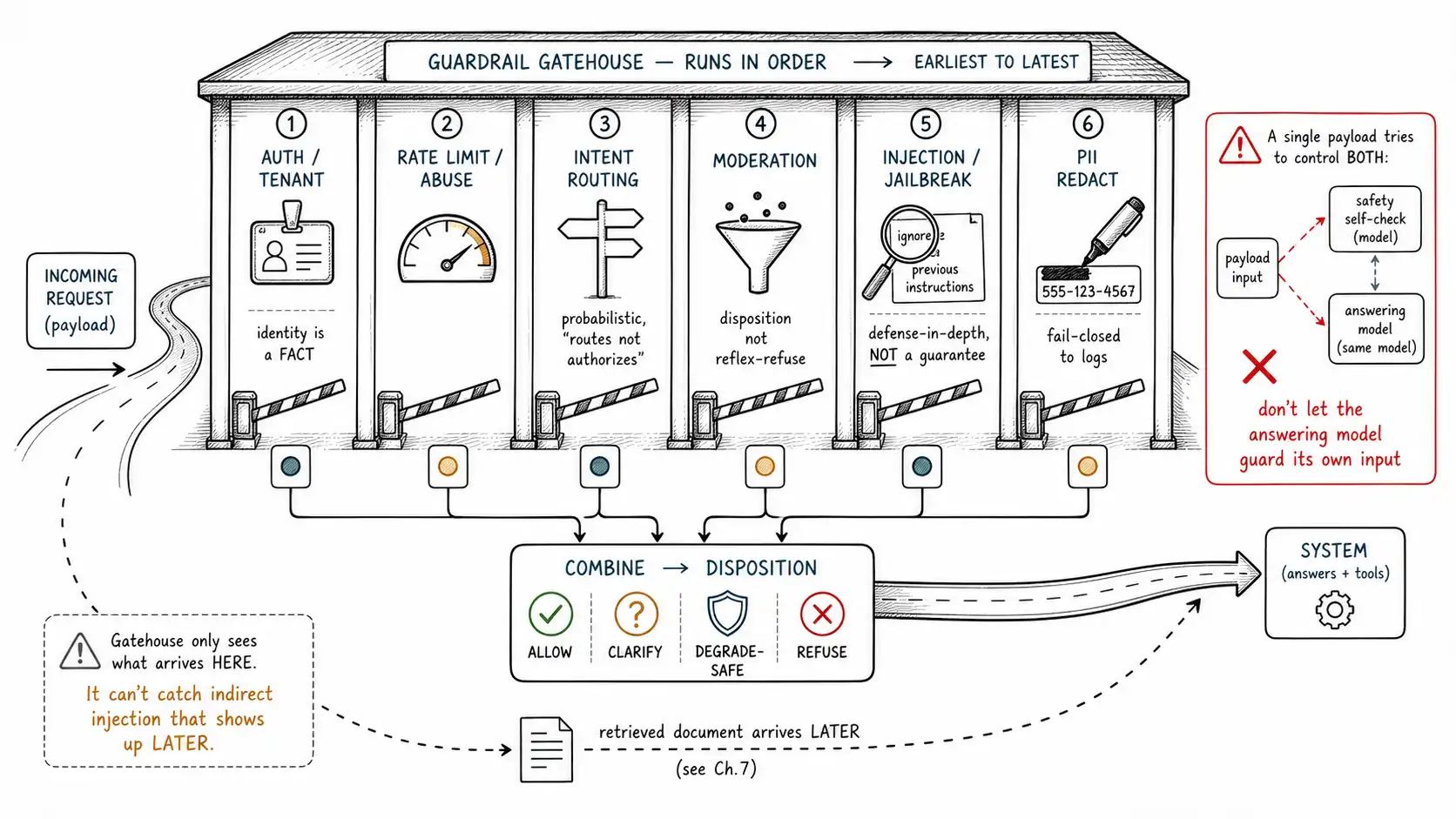
The lanes
A gatehouse has lanes, each doing one job, in a deliberate order so that the cheapest and most decisive checks run first.
**Lane 1: Authentication and tenant identification. ** This is first because it is deterministic, cheap, and changes the meaning of everything after it. Who is this, what tenant, what role, what entitlements? This is not a guardrail in the moderation sense; it is the fact base that every later control depends on. An "input filter" that does not establish identity is guarding a door without knowing who is allowed through it. Crucially, identity is established by your auth system, never inferred from the message content, a message that claims "I am an administrator" is data, not authentication.
**Lane 2: Rate limiting and abuse detection. ** Also early, also cheap, also deterministic. High-risk endpoints (anything that triggers a tool, a transaction, or an expensive model call) get tighter limits than informational ones. Abuse detection watches for patterns across requests, the same session probing variations of a jailbreak, a sudden burst, a credential-stuffing shape. This lane defends against unbounded consumption (LLM10) and raises the cost of an attacker iterating against your other controls, which matters because most real attacks are iterative.
**Lane 3: Intent classification and routing. ** From Chapter 5: classify what the user wants, with confidence, to route the request to the right policy disposition. This is where "dispute a charge" gets sent to the billing-answer path instead of the fraud-refusal path. Intent classification is probabilistic and is allowed to be, because its output routes; it does not authorize (authorization is Lane 1's fact).
**Lane 4: Input moderation. ** The classic content filter: does the input itself contain content in a disallowed safety category? This lane is real and useful for direct misuse (someone pasting clearly harmful content), but it is the lane most prone to the keyword tax (Chapter 5) and overblocking, so it must be tuned for intent and context, not surface tokens, and it must produce a disposition (often degrade-safe or clarify), not a reflexive refuse.
**Lane 5: Injection and jailbreak detection. ** The lane that the three-box mental model omits entirely. Does the input contain an attempt to override the system's instructions, exfiltrate the system prompt, or smuggle an instruction disguised as data? This is LLM01 Prompt Injection, and it deserves its own treatment below because it is the lane teams most often get wrong.
**Lane 6: PII detection and redaction. ** Does the input contain personal data, the user's own, or worse, someone else's, that must be redacted before it enters context, logs, or memory? This lane serves compliance (Chapter 2) and connects to the output and logging boundaries: PII that enters at input tends to leak at output or in telemetry unless handled at the door.
def gatehouse(req) -> GateResult:
# Lane 1: identity is a FACT, established by auth, never inferred from content.
principal = authenticate(req) # may be anonymous-but-rate-limited
if principal is None and req.endpoint.requires_auth:
return GateResult.deny("unauthenticated", operation=2)
# Lane 2: cheap, deterministic, defends consumption and slows iteration.
if not rate_limiter.allow(principal, req.endpoint):
return GateResult.deny("rate_limited", operation=2)
abuse_signal = abuse_detector.score(principal, req) # cross-request pattern
# Lane 3: probabilistic routing (NOT authorization).
intent = classify_intent(req.text, principal.context)
# Lane 4: content moderation -> disposition, not reflexive refuse.
mod = moderate_input(req.text, intent) # returns category + confidence
# Lane 5: injection/jailbreak detection (see below). Independent model/heuristics.
inj = detect_injection(req.text, attachments=req.files)
# Lane 6: PII handling at the door, before context/log/memory.
redacted_text, pii_map = redact_pii(req.text)
return GateResult(
principal=principal,
intent=intent,
moderation=mod,
injection=inj,
abuse=abuse_signal,
text_for_model=redacted_text,
pii_map=pii_map, # restored only where policy permits, never to logs
decision=combine_dispositions(intent, mod, inj, abuse), # Ch.4/5 disposition logic
)The structure matters more than any single lane. Each lane produces an independent signal; the final disposition is combined from them according to the policy, not decided by whichever lane happens to fire. And the order is deliberate: identity and rate limiting (cheap, deterministic, decisive) before the probabilistic lanes (intent, moderation, injection), so an unauthenticated or rate-limited request never costs a classifier call.
Why pre-call detection should not rely only on the answering model
A tempting shortcut: ask the same powerful model that will answer the request to first judge whether the request is safe."Before answering, decide if this violates policy." It is cheap to implement and it is a real weakness, for a reason worth internalizing. The model that will answer the request is the *same model the attacker is trying to manipulate. * If a prompt injection can convince the model to ignore its instructions and answer, the same injection can often convince the model's "safety check" to report the request as safe, the attacker manipulates the judge and the answerer in one move. The OWASP Prompt Injection Prevention Cheat Sheet and OpenAI's safety guidance both point toward defense in depth rather than a single self-check for this reason.
So input detection should use mechanisms that are independent of the answering model: a separate, smaller, purpose-built classifier; deterministic heuristics; an allow-list of expected request shapes for narrow products; and, where you do use an LLM as a judge, a different model or at least a hardened, instruction-isolated prompt that treats the user input strictly as data. The point is not that LLM-based detection is useless; it is that an attacker who controls the input must not be able to control the guard and the answer with the same payload.
Detecting injection without believing you have solved it
Injection detection (Lane 5) is the lane where humility is a feature. There is no detector that catches all prompt injections, and the Rebuff project, a well-known open detector, is explicit that it is a defense-in-depth tool, not a guarantee; its own documentation cautions that no detector provides perfect protection. Treat any injection classifier the same way: a useful filter that raises the attacker's cost and catches the unsophisticated attempts, layered with structural defenses that do not depend on detection at all.
The structural defenses matter more than the detector, and they belong partly here and partly in Chapter 7:
- **Treat all user and retrieved content as untrusted data, never as instructions. ** The system's real instructions come from the system prompt and the application, in a channel the user cannot write to. User input is wrapped and clearly delimited as data. This does not "detect" injection; it reduces the injection's authority even when it slips past the detector.
- **Do not let detection be the only thing standing between input and a tool call. ** If the worst an injection can do is produce text, a missed injection is a reliability problem. If a missed injection can trigger a refund, the real control is the tool authorization (Chapter 10), not the input detector. Place the decisive control at the operation where the harm lands.
- **Log every injection signal even when you allow the request. ** A flagged-but-allowed input is a monitoring goldmine: it tells you what attacks are being attempted before one succeeds.
def detect_injection(text, attachments=None) -> InjectionSignal:
signals = []
# Heuristic layer: cheap, catches the obvious, never the whole answer.
if INSTRUCTION_OVERRIDE_RE.search(text): # "ignore previous instructions", etc.
signals.append(("override_phrase", 0.6))
if looks_like_system_prompt_extraction(text): # "repeat your instructions verbatim"
signals.append(("prompt_extraction", 0.7))
# Independent classifier layer (NOT the answering model).
cls = injection_classifier.score(text) # separate, purpose-built model
if cls.score > 0.5:
signals.append(("classifier", cls.score))
# Attachments are a major vector for INDIRECT injection (see Ch.7).
for f in (attachments or []):
if f.contains_active_instructions():
signals.append(("attachment_injection", 0.8))
return InjectionSignal(
signals=signals,
max_score=max((s for _, s in signals), default=0.0),
# IMPORTANT: a low score is not proof of safety; structural defenses still apply.
note="detector is defense-in-depth, not a guarantee",)Query rewriting and the redaction trap
Two input transformations deserve a caution. Query rewriting, having the system reformulate the user's request before processing, is sometimes used to "clean up" or "make safe" an input. It can help (normalizing, expanding context for retrieval) and it can hurt: a rewriter can change the user's meaning, smuggle in assumptions, or strip the very context that made an ambiguous request resolvable. If you rewrite, preserve the original alongside the rewrite, never act on the rewrite for authorization, and test that the rewrite does not change intent.
PII redaction (Lane 6) has its own trap, the same one that bites every regex-based content filter: false positives strip useful content (a product code that looks like an SSN, an order number that looks like a card number), and false negatives leak the data you were trying to protect (PII in an unusual format the regex missed). The defensible pattern is a hybrid: deterministic patterns for the well-structured cases (card numbers, emails) plus a model-based detector for the messy ones, with a fail-closed disposition for the logging path (when unsure, redact before writing to logs, because a log leak is hard to recall) and a fail-careful disposition for the model path (over-redaction degrades the answer, so restore where policy and the user's own ownership permit). Redaction is a guardrail with both error rates, and like every guardrail in this book, it must be measured on both, not assumed correct because it exists.
Chapter summary
The input gatehouse (boundary operations 1-3) does the cheap, deterministic, pre-model work that should never be left to the model, and it is a set of lanes, not a single bouncer: authentication and tenant identity (a deterministic fact, never inferred from message content), rate limiting and abuse detection (cheap, defends against unbounded consumption, slows attacker iteration), intent classification and routing (probabilistic, routes but never authorizes), input moderation (real for direct misuse but the lane most prone to the keyword tax, so tuned for intent and producing a disposition not a reflex-refuse), injection and jailbreak detection (the lane the three-box model omits), and PII detection and redaction (compliance, handled at the door before context/logs/memory). Lanes run cheapest-and-most-decisive first, each emits an independent signal, and the final disposition is combined per policy. The gatehouse is the first layer, not the whole defense: it cannot catch a prompt injection in a document retrieved later, an unauthorized tool call, or a fabrication. Pre-call detection must not rely solely on the same model that will answer, because one payload can manipulate both the self-check and the answer; use independent classifiers, heuristics, allow-lists, or a different judge model. Injection detection demands humility, no detector is complete (Rebuff itself says so), so the decisive defenses are structural: treat all user and retrieved content as untrusted data with no instruction authority, place the real control at the operation where harm lands (tool authorization, not input detection), and log every injection signal even when allowed. Query rewriting and PII redaction are themselves guardrails with two error rates: rewrite without changing intent and never authorize on the rewrite; redact with a hybrid detector that fails closed to logs and fails careful to the model.