From Prose to Policy
> **Working claim: ** A guardrail without a policy is just an arbitrary model instruction.

Key Takeaways
- From Prose to Policy treats guardrails as placed controls, not a single wall around the model.
- The right question is ROAD: which risk, at which operation, with which action, and which detection signal?
- A useful guardrail system reduces both bypasses and overblocking while keeping residual risk observable.
**Working claim: ** A guardrail without a policy is just an arbitrary model instruction. Until product, legal, security, and safety concerns are written as enforceable, versioned, machine-readable rules, separated from the mechanism that enforces them, every "guardrail" is a developer's guess about what the company meant, frozen into a prompt nobody can audit.
The prompt that nobody could explain
A composited but very common failure. An AI product had grown a system prompt to nine hundred lines. It had accreted over eighteen months: every incident added a clause, every legal review added a paragraph, every product complaint added a "you must never." When a new engineer asked why the assistant refused to discuss a competitor by name, the answer was "it's in the prompt, around line 400, somebody added it." Why? Nobody knew. Was it a legal requirement, a product decision, or one PM's preference from a meeting a year ago? Could it be removed? Nobody would sign off on removing it because nobody knew what it protected against. The prompt had become a policy of record that no policy owner had ever written, reviewed, or approved, a pile of rules with no provenance, no owner, no version, and no way to test whether any given line still mattered.
This is what happens when policy and mechanism are fused. The mechanism (a system prompt sent to the model) had silently become the policy (the company's rules about product behavior), and because the mechanism is code-adjacent and the policy is governance, the fusion meant neither was being done properly. Engineers were making policy decisions by editing prompts; policy owners had no artifact they could read, approve, or version. The nine-hundred-line prompt is the natural end state of "just add guardrails", guardrails as instructions, with no policy behind them.
The fix is a separation that sounds bureaucratic and is actually the most use-dense move in the book: **separate the normative policy from the enforcement mechanism. ** The policy says what should happen for each category of request: allowed, disallowed, restricted, escalated, logged. The mechanism says how, a classifier, a prompt clause, an authorization check, a validator. When they are separate, a policy owner can read and approve the policy without reading code, an engineer can change the mechanism without changing the policy, and you can ask of any behavior: which policy rule produced this, what version, who approved it?
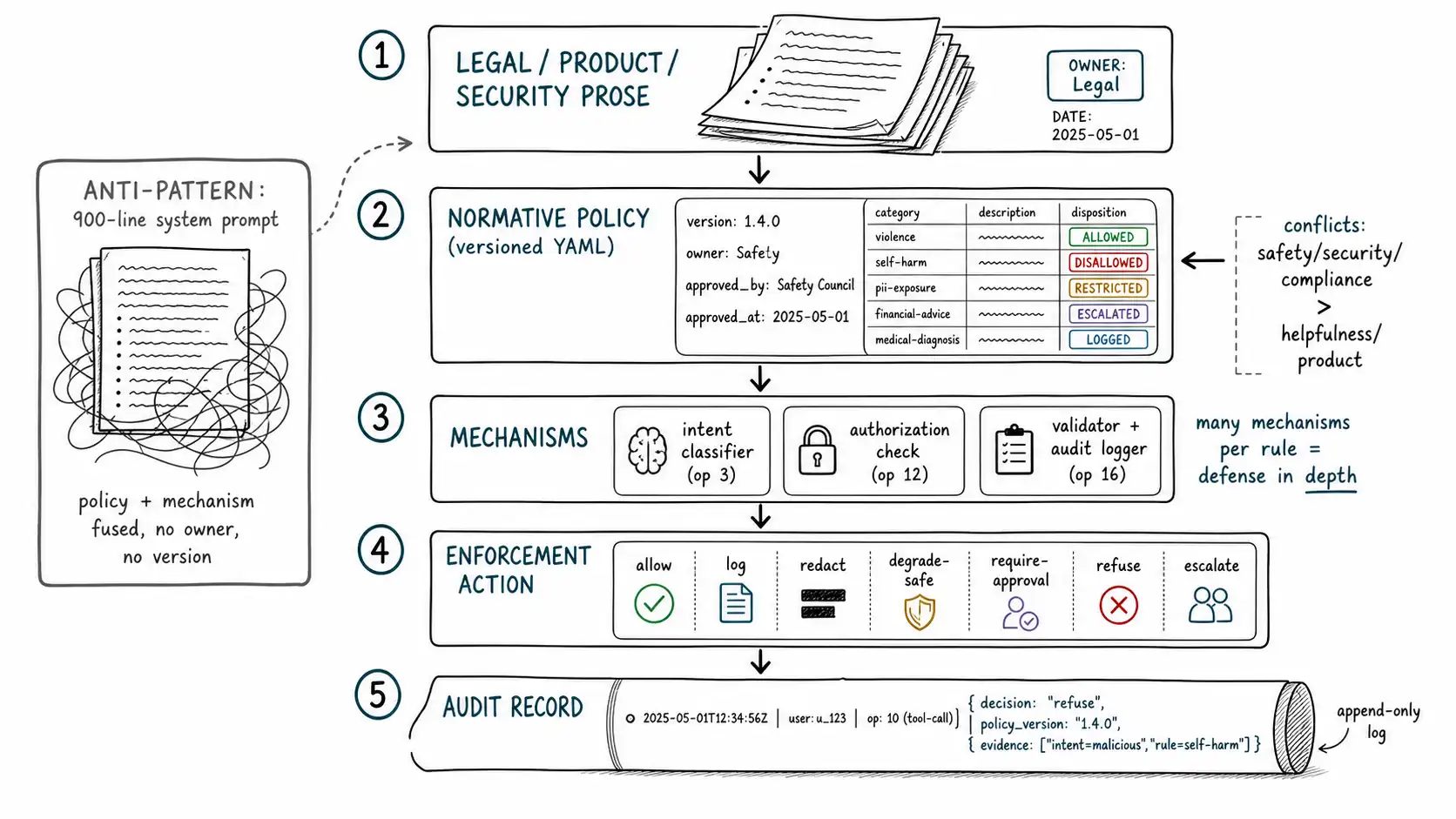
Five dispositions, not two
The nine-hundred-line prompt thought in two dispositions: allow (the default) and refuse (the accreted "never" clauses). That binary is the policy-layer version of the slider, and it produces the same overblocking. A real policy has at least five dispositions, and the difference between them is the difference between a wall and a guardrail.
- **Allowed: ** handle normally. The goal is for the large majority of legitimate requests to land here.
- **Disallowed: ** do not fulfill, and respond with a safe completion (Chapter 9), not a stonewall. Reserved for requests where any fulfillment is the harm.
- **Restricted: ** fulfill conditionally: only the safe part, only with a disclaimer, only above a verification bar, only for an authorized user. This is the disposition that keeps the road usable, and it is the one a two-state policy cannot express.
- **Escalated: ** the system should not decide this alone; route to a human or a stronger process. Used where the cost of an automated mistake exceeds the cost of human latency.
- **Logged: ** allowed, but recorded with elevated detail because it sits near a boundary worth watching even when it is fine.
These dispositions compose: a request can be restricted and logged, or allowed but logged. The crucial addition over the binary is restricted and escalated, because they are where most legitimate-but-sensitive requests belong."How do I dispute a charge?" is not allowed-as-trivia and not disallowed-as-fraud; it is allowed for the informational answer with the actual refund action restricted behind authorization. The two-state prompt could only put it in "refuse, " which is exactly what overblocked the customer in the introduction.
Writing a policy a machine can enforce and a human can approve
A policy must serve two readers at once: a human who approves it and a machine that enforces it. The format that serves both is structured, versioned, and category-based. Each rule names the category it governs, the disposition, the conditions, the action, the evidence the system must capture, and, critically, the concern (Chapter 2) and operation (Chapter 3) so the policy is traceable to where it is enforced.
policy:
name: financial_assistant_policy
version: "2026.06.1" # tie every model response to the policy version that produced it
owner: "risk-and-compliance" # the human accountable, not the engineer who coded it
approved_by: "legal, head-of-product"
approved_on: "2026-06-05"
effective_from: "2026-06-12"
categories:
- id: regulated_financial_advice
description: "Personalized recommendation to buy/sell a specific security"
concern: compliance # see Ch.2
disposition: restricted
operation: [9, 11] # output text + output validation (see Ch.3 boundary)
conditions:
- "user_is_licensed_context: false -> degrade to general education + disclaimer"
action: degrade_safe
evidence_required:
- "disclaimer_attached: true"
- "regulated_advice_classifier_score logged"
escalation: none
- id: account_balance_lookup
description: "Read the user's own balance/transactions"
concern: security
disposition: restricted
operation: [12] # tool authorization
conditions:
- "requester == account_owner (verified) -> allow"
- "else -> refuse + log"
action: allow_if_authorized
evidence_required:
- "auth_check: {requester_id, account_id, result} logged"
- id: funds_transfer
description: "Move money between accounts"
concern: security
disposition: restricted
operation: [10, 12, 13]
conditions:
- "amount <= daily_limit AND requester == owner -> allow + log"
- "amount > daily_limit -> escalate (human approval)"
action: require_approval
evidence_required:
- "transfer record {requester, from, to, amount, decision, approver}"
escalation: human_review_queue
- id: self_harm_indicators
description: "User expresses intent to self-harm"
concern: safety
disposition: escalated
operation: [3, 15]
action: safe_completion_plus_resources # never a bare refusal
evidence_required:
- "crisis_protocol_invoked: true logged (no message content beyond flag)"
escalation: crisis_resources_handoffSeveral properties of this artifact are doing real work. The version is not decoration: it is how you tie a model response to the exact policy that governed it, so that when a regulator or an incident asks "why did the system do this on June 3rd, " you can answer with the policy that was effective on June 3rd. The owner and approved_by fields give every rule provenance, the thing the nine-hundred-line prompt lacked. The concern and operation fields make the policy traceable to the control that enforces it, so you can audit whether a rule has a mechanism behind it or is merely aspirational. And no rule uses a bare refuse where degrade_safe, restricted, or escalate reduces the risk while keeping the road usable, the self-harm rule in particular uses safe completion plus resources, because a bare refusal to a person in crisis is both useless and harmful.
Separating normative policy from mechanism
The policy above says what. It deliberately does not say how, and that restraint is the whole point. The funds_transfer rule says "amount > daily_limit -> escalate." It does not say whether the daily-limit check is a Python function, a database trigger, or a step in a workflow engine. That is the mechanism layer's job, and keeping it separate buys two things.
First, **mechanisms can improve without policy review. ** If you replace a regex-based regulated-advice detector with a better classifier, the policy does not change, so legal does not need to re-approve. Conversely, if legal changes the disclaimer requirement, the policy version bumps and the mechanism reads the new rule without a code change. The two evolve on their own clocks.
Second, one policy rule can be enforced by several mechanisms at several operations, defense in depth. The funds_transfer rule is enforced by an input-side intent classifier (operation 3, to route the request), a tool-authorization check (operation 12, the deterministic gate), and an audit logger (operation 16, the evidence). No single mechanism is the policy; the policy is the normative statement, and the mechanisms are its layered implementation. This is also how you avoid the security mistake from Chapter 2: a security disposition like funds_transfer must be enforced by a deterministic mechanism (the authorization check), even though the same rule is also routed by a probabilistic one (the intent classifier). The policy can hold both because it does not name the mechanism.
A thin enforcement shim reads the policy and dispatches to mechanisms:
def enforce(request, policy: Policy) -> Decision:
category = classify_category(request) # mechanism: intent classifier
rule = policy.rule_for(category) # normative lookup
if rule is None:
return Decision.allow(logged=True, note="uncategorized -> default allow + log")
# The policy states the disposition; mechanisms below resolve the conditions.
if rule.disposition == "disallowed":
return Decision.safe_complete(rule.id, policy.version)
if rule.disposition == "escalated":
return Decision.escalate(rule.escalation, policy.version)
if rule.disposition == "restricted":
return resolve_conditions(request, rule, policy.version) # may allow/redact/approve/refuse
return Decision.allow(logged=rule.disposition == "logged", policy_version=policy.version)Every Decision carries policy.version. That single field is what makes the system auditable: a response is not just "what the model said, " it is "what the model said under policy 2026.06.1, " and if that version is later found defective, you can find every response it governed.
Policy conflicts are real and must be decided in the policy, not the prompt
Policies conflict, and pretending they do not is how conflicts get resolved silently and badly by whichever mechanism happens to run last. Helpfulness conflicts with harmlessness: the most helpful answer to "what's the maximum dose of this medication" is also the most dangerous. Privacy conflicts with personalization: remembering the user's history is helpful and is also data you now must protect and delete. Automation conflicts with oversight: routing every transfer to a human is safe and also defeats the product. Constitutional AI is one research direction for resolving such tensions at the model-training level by giving the model an explicit set of principles to weigh, but at the system level, the resolution belongs in the policy, where a human owner can see the tradeoff and decide it on the record.
Concretely, the policy should declare a precedence when dispositions collide: safety and security dispositions override helpfulness and product-policy dispositions; compliance dispositions override product preferences; the more restrictive disposition wins a tie unless a named exception applies. Putting this precedence in the versioned policy means the tradeoff is decided by an accountable owner and visible in an audit, rather than emerging from the accident of which classifier fired first. The nine-hundred-line prompt resolved conflicts by line order and luck. A real policy resolves them by declared precedence and review.
Chapter summary
A guardrail without a policy is an arbitrary instruction, and the natural end state of "just add guardrails" is a nine-hundred-line system prompt that has silently become a policy of record with no owner, version, or provenance, because policy and mechanism were fused. The highest-use move is to separate the normative policy (what should happen per category) from the enforcement mechanism (how it is enforced). Replace the allow/refuse binary with five composable dispositions, allowed, disallowed, restricted, escalated, logged, because restricted and escalated are where most legitimate-but-sensitive requests belong, and a two-state policy can only overblock them into refusal. Write the policy as a versioned, owned, approved, category-based artifact that names, per rule, the disposition, conditions, action, required evidence, and the concern and operation that tie it to its enforcement point; carry the policy version on every decision so any response can be traced to the exact rule that governed it. Keeping mechanism separate lets mechanisms improve without policy re-approval, lets policy change without code change, and lets one rule be enforced by several mechanisms at several operations as defense in depth, which is also how a security disposition gets the deterministic mechanism it requires while still being routed by a probabilistic one. Policy conflicts (helpfulness vs. harmlessness, privacy vs. personalization, automation vs. oversight) are real and must be resolved by declared precedence in the versioned policy, decided by an accountable owner and visible in audit, not by the accident of which classifier ran last.