Abstention and Escalation
Selective prediction and conformal methods let a system decline to answer with a controlled error rate, and escalation routes the abstained cases to where they get resolved.

The most underrated sentence an AI product can produce is "I don't know, here is who does." It is underrated because saying it well is harder than it looks and because the prevailing product culture treats not-answering as failure. I want to invert that. The ability to not answer, on the right cases, with a controlled and measurable error rate, is one of the strongest reliability features you can build. This chapter is about the machinery that makes principled not-answering possible: selective prediction and conformal methods on the technical side, and escalation design on the human side. The two are inseparable. An abstention with nowhere to go is just a dead end; an escalation without a principled trigger is just guessing about when to give up.
Abstention is a decision with a knob you can turn
Start with the core idea from the selective prediction literature. A predictor that must answer every input has one performance number: its accuracy. A predictor that is allowed to abstain on some inputs has two numbers that trade off against each other: coverage, the fraction of inputs it answers, and risk, the error rate on the inputs it does answer. The foundational framing here is El-Yaniv and Wiener's work on the risk-coverage tradeoff, which formalizes selective classification: by declining to answer the inputs it is least sure about, a system can drive its error rate on the answered inputs down to a target, at the cost of answering fewer of them.
This is a profound reframing for product work. You are no longer stuck with whatever accuracy the model gives you. You have a dial. You can say: on this high-stakes answer type, I want the error rate among answered cases to be below some threshold, and I will abstain on however many cases that requires. Coverage becomes the price you pay for a reliability guarantee, and you get to choose the point on the curve that matches the stakes.
The danger zone from the Confidence-Cost Matrix is exactly where you trade coverage for low risk aggressively: answer only the cases you are confident about, abstain on the rest, and route the abstentions to humans. The low-stakes quadrant is where you keep coverage high and tolerate more error, because the cost of each error is small. The same model, two different operating points, chosen by stakes. That is selective prediction used as a product control.
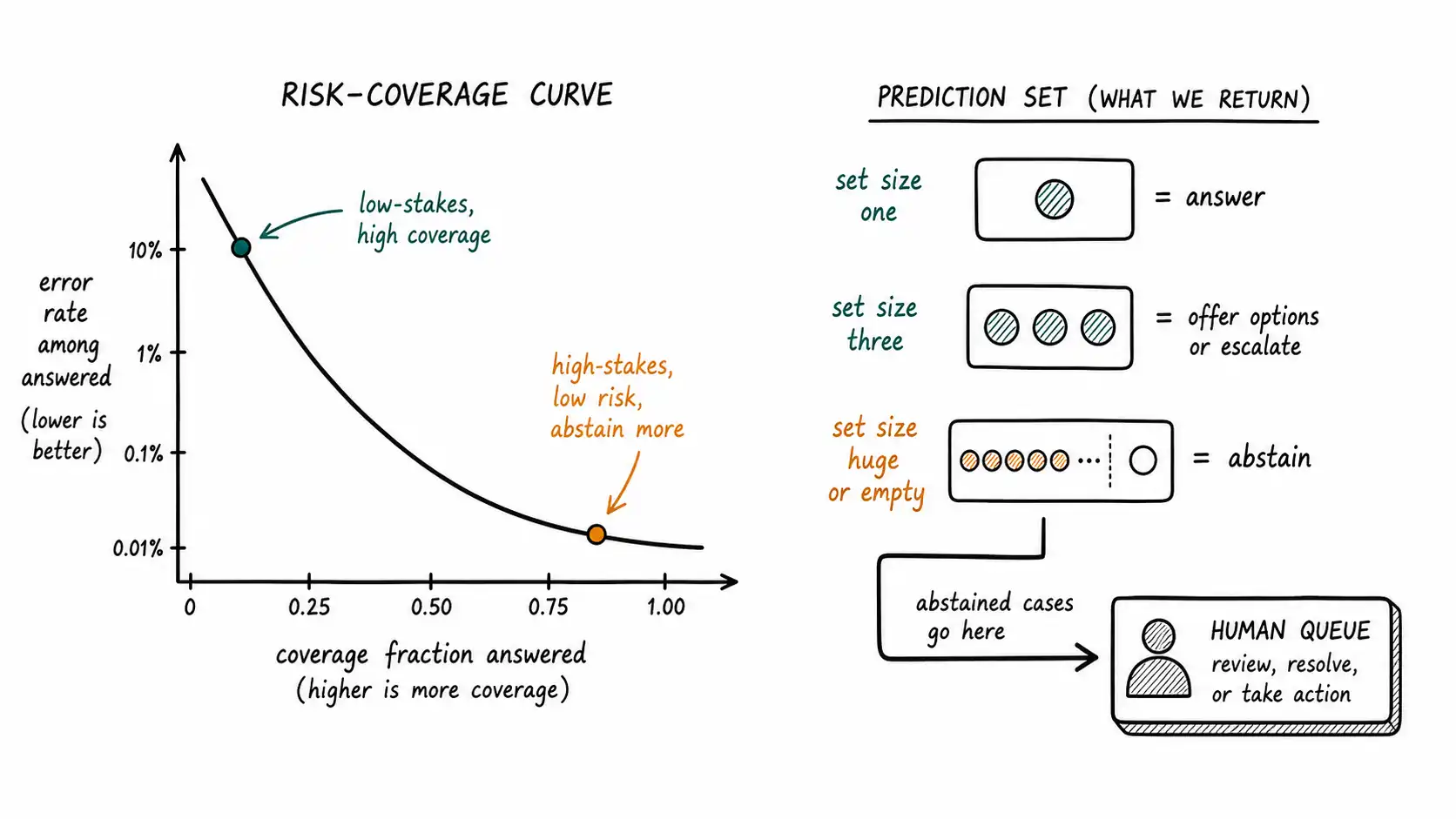
Conformal prediction: abstention with a statistical guarantee
Selective prediction tells you the tradeoff exists. Conformal prediction gives you a way to set the dial with a guarantee. The accessible reference here is Angelopoulos and Bates, A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification, and it is worth the read because the method is unusually practical.
The idea, stripped to its essentials: using a held-out calibration set, conformal prediction produces, for each input, a set of possible answers that is guaranteed (under an exchangeability assumption) to contain the true answer with a chosen probability, say 90 percent. The size of that set is the signal you want. When the set is a single answer, the system is confident and can answer directly. When the set contains several answers, the system is genuinely uncertain, and that is your trigger to climb the Doubt UX Ladder to multiple options, or to abstain, or to escalate. When the set is empty or huge, something is badly wrong with the input and you should certainly not answer confidently.
What makes this valuable for the confident-wrongness problem is the guarantee. Most confidence signals, including raw model probabilities, are themselves miscalibrated, as the Guo result established. Conformal prediction gives you a coverage guarantee that holds without assuming the model's probabilities are calibrated, which is precisely the situation you are in. You can say to a regulator or a risk committee: on this answer type, our abstention policy guarantees that when we do answer, the true answer is in our prediction set at least 90 percent of the time, and we abstain otherwise. That is a defensible reliability claim, not a vibe.
There are caveats worth stating plainly so you do not oversell it. The guarantee depends on the calibration set resembling production traffic; distribution shift breaks it, which means you must monitor and recalibrate. And applying conformal methods to open-ended generation, as opposed to classification, is an active research area rather than a solved one. But for the bounded decision problems that fill the danger zone, eligibility, routing, classification, structured extraction, it is a strong and underused tool.
A good abstention is not a dead end
Now the part teams get wrong even when the math is right. An abstention that just says "I can't help with that" is, from the user's perspective, a failure, and it triggers exactly the algorithm aversion we discussed. The abstention has to do three things to be a feature rather than a wall.
It has to explain, specifically, why it is abstaining. Not "I can't help," but "I found conflicting information about your account type, and I don't want to give you a wrong answer on something that affects a charge." Specific reasons read as competence; generic refusals read as incompetence.
It has to preserve and forward context. The user has already invested effort describing their problem. An abstention that drops them back to square one, forcing them to re-explain to a human, wastes that effort and feels punitive. A good abstention carries the question, the relevant retrieved context, and the reason for abstention forward into the escalation.
It has to offer a path. Abstention without escalation is a dead end; abstention with a clear next step, a human, a different tool, a specific thing to check, is a handoff. The path is what turns "I don't know" into "I don't know, here is who does," which is the valuable sentence we started with.
Escalation is a routing problem, and routing needs a map
Escalation is often treated as a single thing, "send it to a human," but it is really a routing decision with multiple destinations, and routing badly is its own failure. The escalation policy map specifies, for each trigger, where the case goes and what travels with it.
| Trigger | Destination | Context forwarded | Why this route |
|---|---|---|---|
| Confidence below floor on high-stakes answer | Human specialist queue | Query, retrieved sources, confidence, reason | Stakes require human ownership |
| Prediction set contains multiple answers | Clarification to user, then retry | The discriminating question | User can resolve it; no human needed yet |
| Out-of-scope request | Correct tool or team | Request and detected scope | Wrong destination entirely; reroute |
| Source contradiction detected | Content owner plus human answer to user | The conflicting sources | Fix the corpus, not just this answer |
| User disputes the answer | Human review with audit trail | Full interaction, answer contract | Liability and learning |
Two design principles run through this map. First, not every abstention goes to a human; some go back to the user as a clarification, some go to a different system, some go to a content owner to fix the underlying data. Sending everything to a human queue overloads the humans and degrades the very review you depend on, a failure we will dissect in the next chapter. Second, every escalation forwards context. The single biggest determinant of whether escalation helps or just adds latency is whether the human receives the case warm, with everything the system already knew, or cold, forcing a restart.
The detection that triggers all of this: combining signals
Abstention and escalation are only as good as the uncertainty detection that triggers them, the Detect step of the DOUBT pattern. No single signal is sufficient, so you combine them into the internal confidence score that drives the bands.
Retrieval signals. How well did the retrieved passages match the query, and how strong was the top result relative to the rest? A query that retrieves nothing with a good score, or retrieves several documents with similar weak scores, is a query you are about to answer badly. We will treat retrieval confidence in depth in its own chapter; here it is one input.
Model confidence signals. Token-level and sequence-level probabilities, the spread of answers under sampling, or the size of a conformal prediction set. These capture the model's own uncertainty, with the caveat that raw probabilities are miscalibrated and need correction.
Verifier agreement. A separate check, an entailment verifier, a second model, a rule, that confirms the answer is supported by the evidence. Disagreement between the generator and the verifier is a strong abstention trigger, because it means the fluent answer and the evidence have come apart.
Source quality. The rubric score from the sources chapter. A confident model grounded in a low-quality source should still abstain or hedge on a high-stakes question.
Consistency. Does the model give the same answer when asked the same question different ways, or under resampling? High variance under rephrasing is a sign the answer is not robust, and robustness is part of confidence.
Combine these into a single internal score, then map the score to bands and the bands to ladder rungs and escalation routes. The combination function is itself something you calibrate and measure, which is the subject of the next chapter. The point here is architectural: detection is multi-signal, no one signal is trustworthy alone, and the abstention and escalation machinery is downstream of getting detection right.
A worked escalation decision flow
Putting it together for a high-stakes support answer:
compute internal_confidence from {retrieval, model, verifier, source_quality, consistency}
if verifier disagrees with generated answer:
abstain -> human specialist queue (forward sources + disagreement)
elif prediction_set_size > 1:
climb ladder: offer multiple options OR ask clarifying question
elif internal_confidence < FLOOR:
abstain -> explain reason -> offer human escalation
elif internal_confidence < LOW and stakes == HIGH:
answer with strong caveat AND surface escalation option
elif internal_confidence >= HIGH and source_quality >= 3:
answer plainly with inline evidence
else:
answer with caveat + source + freshnessThis is deterministic, testable, and tunable. The thresholds come from your calibration measurement; the routes come from your escalation map; the expressed forms come from the Doubt UX Ladder and the answer contract. Every framework in the book converges here, in the small piece of policy code that decides, for a given answer, whether to speak plainly, hedge, offer options, abstain, or escalate, and where to send it if it leaves the system.
The economic case for abstention
A brief note for the skeptic who sees abstention as lost coverage and therefore lost value. The selective-prediction tradeoff is not "less value." It is value reallocated from cheap correct answers to avoided expensive errors. On a high-stakes answer type, the expected cost of one confident wrong answer, recall the Air Canada liability and the six-figure contract, dwarfs the value of the marginal low-confidence answers you decline to give. Abstaining on the bottom 5 percent of confidence to drive the error rate on the top 95 percent below threshold is almost always the better trade in the danger zone. The coverage you give up is the coverage you were going to get wrong. We will put real numbers on this in the economics chapter; here it is enough to say abstention is not a cost center, it is risk avoided, and risk avoided is the entire value proposition in high-stakes deployment.
Practical exercise: set your operating point and escalation map
For your highest-stakes answer type, do two things.
First, define the operating point. Decide the maximum acceptable error rate among answered cases. Then, using a held-out labeled set, find the confidence threshold that achieves it and measure the coverage you get at that threshold. If the coverage is unacceptably low, that is telling you the model is not reliable enough for this answer type at this stakes level, which is a finding worth having before an incident rather than after. Do not paper over low coverage by lowering the threshold; that just moves the errors back into the answered set.
Second, build the escalation map for that answer type: enumerate the triggers, the destinations, and the context each forwards. Then verify, end to end, that an abstained case actually arrives at its destination warm. The most common failure I find is an abstention path that technically exists but dumps the user into a generic queue with none of the context, so the human starts cold and the user re-explains everything. That is abstention without escalation, and it is barely better than a confident wrong answer because the user, frustrated, often goes back and forces the AI to answer anyway.
Summary
Principled not-answering is a strong reliability feature. Selective prediction (El-Yaniv and Wiener) reframes accuracy as a risk-coverage tradeoff: by abstaining on the least-confident inputs, a system drives its error rate on answered inputs to a target, paying in coverage. Conformal prediction (Angelopoulos and Bates) sets the dial with a distribution-free coverage guarantee that holds even when raw model probabilities are miscalibrated, using prediction-set size as the uncertainty signal. A good abstention explains specifically, forwards context, and offers a path; abstention without escalation is a dead end. Escalation is a routing problem requiring a policy map with triggers, destinations, and forwarded context, and not every abstention goes to a human. All of it is downstream of multi-signal uncertainty detection combining retrieval, model confidence, verifier agreement, source quality, and consistency. Economically, abstention is risk avoided, not value lost. Measuring Calibration in AI Products provides the tools to set those abstention thresholds from real data rather than guesswork.
Key Takeaways
- Allowing abstention turns one number (accuracy) into a risk-coverage tradeoff you can tune; coverage is the price of a reliability guarantee.
- Conformal prediction provides a distribution-free coverage guarantee using prediction-set size, valid even when raw model probabilities are miscalibrated.
- A good abstention explains specifically, forwards context, and offers a path; abstention without escalation is a dead end that triggers user frustration.
- Escalation is routing, not a single action; the escalation policy map specifies triggers, destinations, and forwarded context, and not every case goes to a human.
- Abstention and escalation are downstream of multi-signal detection: retrieval, model confidence, verifier agreement, source quality, and consistency, combined into one tunable score.
- Abstention is risk avoided, not value lost; the coverage you decline in the danger zone is mostly the coverage you would have gotten wrong.