Where Wrong Answers Get Expensive
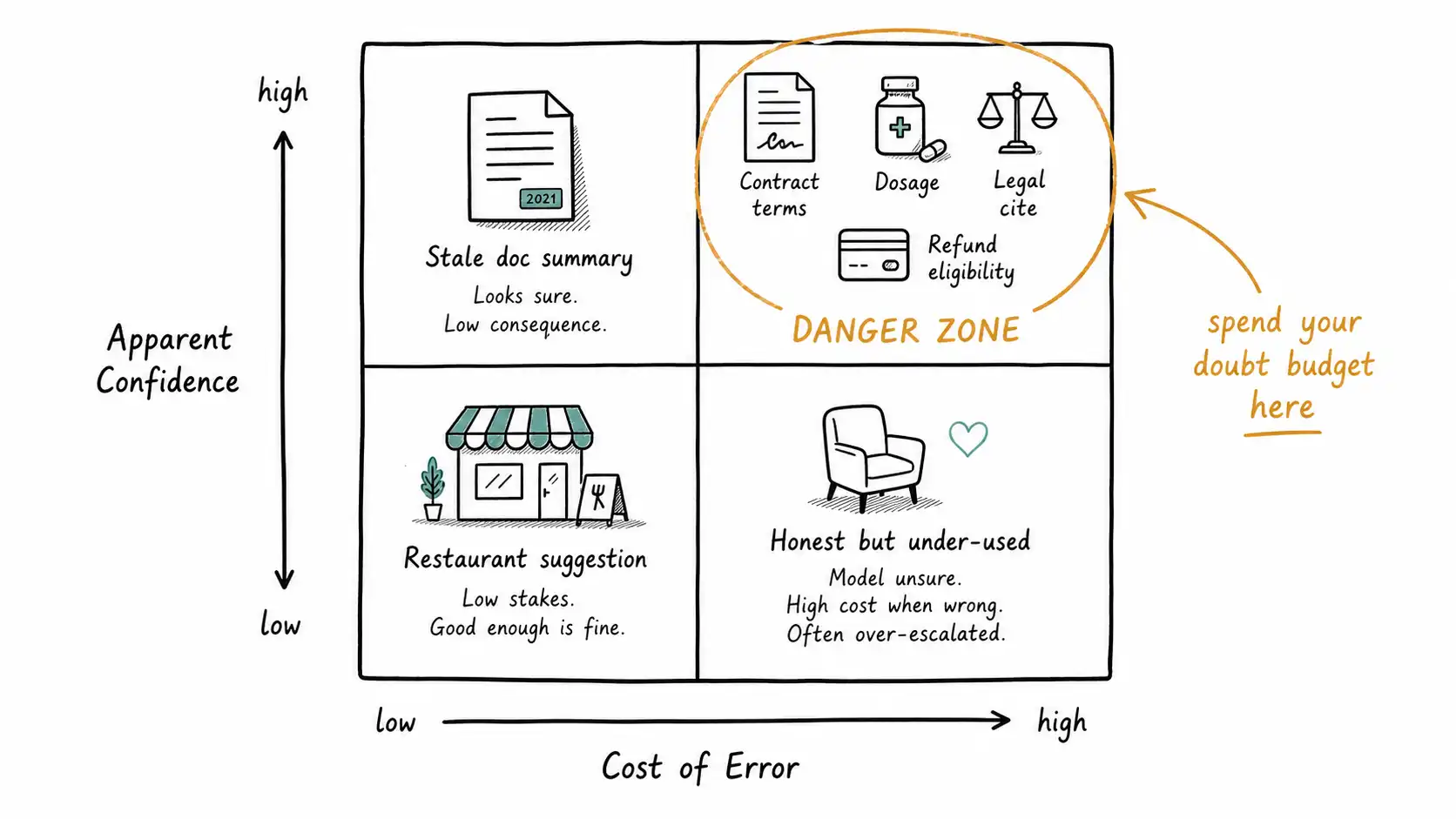
The Confidence-Cost Matrix maps apparent confidence against cost of error so you spend your doubt budget where it pays.

Let me start with an economic model rather than a story, because the central decision of this book is a resource-allocation decision. You cannot afford to make every AI answer carefully calibrated, evidence-backed, and human-reviewed. Doubt has a cost: latency, engineering effort, user friction, and the very real risk of crying wolf so often that people ignore you. So the question is not "should we add calibrated doubt." The question is "where, and how much." This chapter gives you the tool for answering it: the Confidence-Cost Matrix.
Two axes that actually matter
Forget the model for a moment. Two things determine how dangerous a given AI feature is.
The first is how confident the answer appears to the user, the expressed confidence and authority from the previous chapter combined into a single felt quantity: how finished does this answer look, how likely is the user to act on it without checking.
The second is the cost of an error: what happens, in money, harm, legal exposure, or reputation, when this particular kind of answer is wrong and someone acts on it.
Plot apparent confidence on one axis and cost of error on the other, and you get four quadrants, each demanding a different design response.
| Low cost of error | High cost of error | |
|---|---|---|
| Low apparent confidence | Cheap and honest: fine to ship, low priority | Honest but under-deployed: the doubt is appropriate, but make sure users can escalate to truth |
| High apparent confidence | Annoying at worst: a confidently wrong restaurant suggestion | The danger zone: confident, authoritative, and expensive to be wrong; calibrated doubt is mandatory here |
The top-right quadrant is where you spend your doubt budget. The bottom-left quadrant is where you should resist over-engineering, because adding heavy uncertainty UX to a low-stakes feature trains users to ignore your warnings everywhere, which spends your credibility on cases that did not need it.
This matrix is the allocation tool for the whole book. Everything else, the answer contracts, the UX ladder, the escalation policies, the calibration measurement, costs effort, and the matrix tells you which features deserve that effort.
Cost of error is multidimensional, so decompose it
"Cost of error" is too coarse to act on. When you actually score a feature, decompose the cost along dimensions that surface different kinds of risk.
Reversibility. Can the error be undone? A wrong draft email the user reviews before sending is highly reversible. A wrong dosage administered, or a wrong figure auto-posted to a regulatory filing, is not. Irreversibility multiplies cost dramatically, because it removes the human's chance to catch the error downstream.
Magnitude. How big is the harm per instance? A wrong answer that misstates a refund window costs a few hundred dollars. A wrong answer that misstates a contract's renewal term costs six figures, as in the opening of this book.
Frequency and exposure. How many times per day does this answer type get acted on? A rare high-magnitude error and a frequent low-magnitude error can carry the same expected cost, but they demand different responses: the rare one needs a tripwire, the frequent one needs systematic calibration.
Detectability. Will anyone notice the error before harm lands? An error that produces an obviously broken output is self-limiting. An error that produces a plausible, fluent, wrong output, the exact failure this book is about, is undetectable by design, which is what makes the confident wrong answer so much costlier than the incoherent one.
Liability and attribution. Who is on the hook? This is not abstract. When Air Canada's chatbot told a grieving customer he could claim a bereavement fare retroactively, contrary to the airline's actual policy, the British Columbia Civil Resolution Tribunal in Moffatt v. Air Canada rejected the airline's argument that the chatbot was a separate entity responsible for its own statements, and held the company liable for negligent misrepresentation. The cost of that wrong answer was not just the few hundred dollars of damages. It was the legal precedent, widely reported, establishing that you own your AI's confident wrong answers. Attribution does not transfer to the model. It stays with you.
Multiply or combine these dimensions and you get a defensible cost-of-error score for each answer type, which places the feature on the vertical extent of the matrix. Do not skip the decomposition. "It feels low risk" is how high-magnitude, low-frequency, irreversible answer types end up shipped with no doubt UX at all, because they did not feel dangerous in the demo where they happened to be right.
Apparent confidence is something you are choosing, often by accident
The horizontal axis, apparent confidence, is the one teams forget they control. They treat it as fixed: "the model just sounds like that." It is not fixed. As established in the previous chapter, apparent confidence is the product of expressed confidence and authority, and both are dials.
So a feature can move horizontally on the matrix without any change to the model, just by changing how the answer is presented. This is enormously useful, because moving a high-cost feature leftward, reducing its apparent confidence to match its actual reliability, is often far cheaper than improving the model's accuracy. You cannot always make the model more accurate this quarter. You can almost always make it sound exactly as confident as it deserves to sound this quarter.
That reframing changes the engineering conversation. Instead of "we cannot ship this until the model is more accurate," the question becomes "given the model's actual reliability, where on the matrix does this feature need to sit, and can we get it there by adjusting presentation, evidence, and escalation rather than by waiting for a better model." Often you can.
The worked scoring: a support automation example
Let me run an actual feature through the matrix, a customer-support assistant for a software company, scoring its answer types so you can see the method.
| Answer type | Cost of error (drivers) | Current apparent confidence | Quadrant | Required response |
|---|---|---|---|---|
| "How do I change my avatar?" | Low: reversible, tiny magnitude, self-detecting | High (confident card) | Bottom-left | Ship as is; do not over-engineer |
| "Am I eligible for a refund?" | High: money, liability, low detectability (Air Canada lesson) | High (confident card) | Top-right | Calibrated answer + source + escalation path mandatory |
| "Does my plan include SSO?" | Medium: reversible but drives purchase decisions | High | Upper-middle | Show source + freshness; caveat if retrieval weak |
| "Is my data deleted after cancellation?" | High: compliance, irreversible, liability | High | Top-right | Abstain or escalate unless verified against current policy doc |
Two things jump out. First, the model and interface are identical across all four rows, the same assistant, the same confident card, but the required response differs completely because the cost of error differs. A single uniform UX cannot be correct for all four. Second, the two top-right rows are the ones that will eventually generate the incident, and they are sitting today at high apparent confidence with no doubt design, which means they are in the danger zone right now. That is the finding the matrix is built to surface.
Why the danger zone is psychologically invisible
The danger zone is hard to see precisely because it usually works. A confident, authoritative, high-stakes answer is correct most of the time, and every correct instance reinforces user trust and team complacency. The feature accumulates a track record of being right, which trains users to stop checking, which is the overtrust mechanism from the introduction. The rare wrong answer then lands in an environment optimized, by hundreds of prior correct answers, for nobody to catch it.
This is the inverse of how risk usually feels. Most risky things feel risky. The confidently-wrong AI answer feels safe right up until it is catastrophic, because its safety record is real and its failure is invisible. The matrix is a way to reason about risk that does not rely on the feature feeling risky, because in this domain the feeling is exactly backwards. You score the cost of error in the cold light of "what if this specific answer were wrong and someone acted on it," not in the warm light of "it's been working great."
Using the matrix to set policy, not just to worry
The matrix is only useful if it drives decisions. Here is how to wire it into how you actually operate.
Make matrix placement a required field for any AI feature in your product. Before a feature ships, someone writes down its cost-of-error score with the decomposition above, and its current apparent-confidence level. That single artifact forces the danger-zone question into the open before launch instead of after the incident.
Set a hard rule for the top-right quadrant. In high-cost, high-apparent-confidence features, calibrated doubt is not optional. At minimum: expressed confidence must be a function of internal confidence, evidence must be shown and ideally verified, and an escalation path to a human must exist. The DOUBT pattern and the answer contract from the next chapters are how you satisfy this rule. Below that bar, the feature does not ship in that quadrant; you either reduce its apparent confidence to move it left, or you add the doubt machinery, or you do not deploy it for that answer type.
Resist gold-plating the bottom-left. Doubt UX spent on trivial, reversible, self-detecting answers is worse than wasted, because it desensitizes users to your warnings. Calibrated doubt is a scarce credibility resource. Spend it where the matrix says it pays.
Revisit placement when reliability changes. If you swap in a more accurate model, features may move leftward (lower apparent confidence appropriate to higher reliability) or, per the Guo result, the model may become more overconfident and the danger actually rises. Re-score after any model change. The matrix is not a one-time gate; it is a standing instrument.
Practical exercise: the Confidence-Cost Matrix worksheet
For each AI answer type in your product, fill one row.
- Name the answer type as a user would phrase it.
- Score cost of error 1 to 5 on each dimension: reversibility, magnitude, frequency-exposure, detectability, liability. Note the highest driver; do not average away a single dimension that screams.
- Rate current apparent confidence: is expressed confidence high and authority high (a confident branded card), or is it visibly hedged?
- Place the row in a quadrant.
- For every top-right row, write the required doubt response and whether it currently exists. The gaps are your prioritized backlog.
Bring the completed worksheet to a review and ask one question of every top-right row that lacks doubt machinery: "If this answer were confidently wrong tomorrow and a customer acted on it, what is the worst-case cost, and who is liable?" The Air Canada answer to that question, you are liable, tends to focus the room.
Summary
Calibrated doubt is a scarce resource, so you must allocate it. The Confidence-Cost Matrix plots apparent confidence against cost of error, yielding four quadrants. The top-right, high apparent confidence and high cost of error, is the danger zone where calibrated doubt is mandatory; the bottom-left is where over-engineering doubt backfires by desensitizing users. Cost of error decomposes into reversibility, magnitude, frequency, detectability, and liability, and the Moffatt v. Air Canada ruling shows liability stays with you, not the model. Apparent confidence is a set of dials you control, so you can often move a high-cost feature out of the danger zone by changing presentation rather than waiting for a better model. The danger zone is psychologically invisible because it usually works, which is exactly why a deliberate scoring tool beats intuition here. Why Showing Sources Is Not Enough examines the next instinct teams reach for - and why it mostly fails.
Key Takeaways
- Doubt is a scarce resource with real costs; the Confidence-Cost Matrix tells you where to spend it.
- The two axes are apparent confidence and cost of error; the top-right quadrant is the mandatory-doubt danger zone.
- Decompose cost of error into reversibility, magnitude, frequency, detectability, and liability rather than treating it as one feeling.
- Moffatt v. Air Canada established that liability for a confident wrong AI answer stays with the deploying company, not the chatbot.
- Apparent confidence is a set of dials, so you can move a feature out of the danger zone by changing presentation, often cheaper than improving the model.
- The danger zone is invisible because it usually works; a deliberate scoring worksheet beats intuition, and gold-plating low-stakes features backfires.