Human Review Theater Versus Real Review
A human in the loop who rubber-stamps fluent output reduces no risk and adds the dangerous illusion that risk was reduced.

The compliance team's solution to AI risk was elegant on the slide: "All high-stakes AI outputs are reviewed by a human before action." A checkbox in the workflow, a name attached, an audit trail. Everyone felt safer. Then we looked at the data. The reviewers approved 99.4 percent of outputs, spent a median of eight seconds per review, and the cases they did catch were the obviously-broken ones, never the fluent-but-wrong ones. They were not reviewing. They were clicking approve on answers that looked finished, which is the exact behavior the fluent interface is engineered to produce. The human in the loop was not reducing risk. The human in the loop was laundering machine output into human accountability while adding the comforting illusion that risk had been reduced. That illusion is more dangerous than no review at all, because it stops you from building the controls that would actually work.
This chapter is about the difference between review that reduces risk and review that performs the reduction of risk, and how to tell which one you have built.
Why naive human review fails: the automation bias trap
The belief that adding a human reviewer fixes AI errors rests on an assumption the human-factors literature demolished decades ago: that humans monitoring automation catch its errors. They mostly do not, and the reason is automation bias.
The canonical framing remains Parasuraman and Riley's Humans and Automation: Use, Misuse, Disuse, Abuse. They describe misuse as overreliance leading to monitoring failures: when a human supervises an automated system that is usually right, the human's vigilance degrades, they accept the automation's output, and they fail to catch the errors precisely because the system is reliable enough to have earned their complacency. The empirical work on automation bias, including the studies by Mosier, Skitka, and colleagues on automation-induced complacency in cockpit and decision-support settings, shows two specific failure modes: omission errors, where the human misses a problem the automation did not flag, and commission errors, where the human follows an automated recommendation that is wrong even when other information contradicts it.
Now apply that to a fluent AI output. The output is usually right (earning complacency), it is fluent and authoritative (suppressing scrutiny per the fluency chapter), and the reviewer is processing many of them under time pressure (maximizing satisficing). Every condition that produces automation bias is present and amplified. A reviewer placed in front of a stream of polished AI answers is in the worst possible position to catch the rare fluent-but-wrong one. The review is structurally set up to fail, and the failure is invisible, because the reviewer approves and the audit trail records diligence.
This is why "add a human in the loop" is not a control. It is a hope, dressed as a control, and the dressing is what makes it dangerous. The dressing tells leadership the risk is handled, which stops the harder work of building review that actually catches errors.
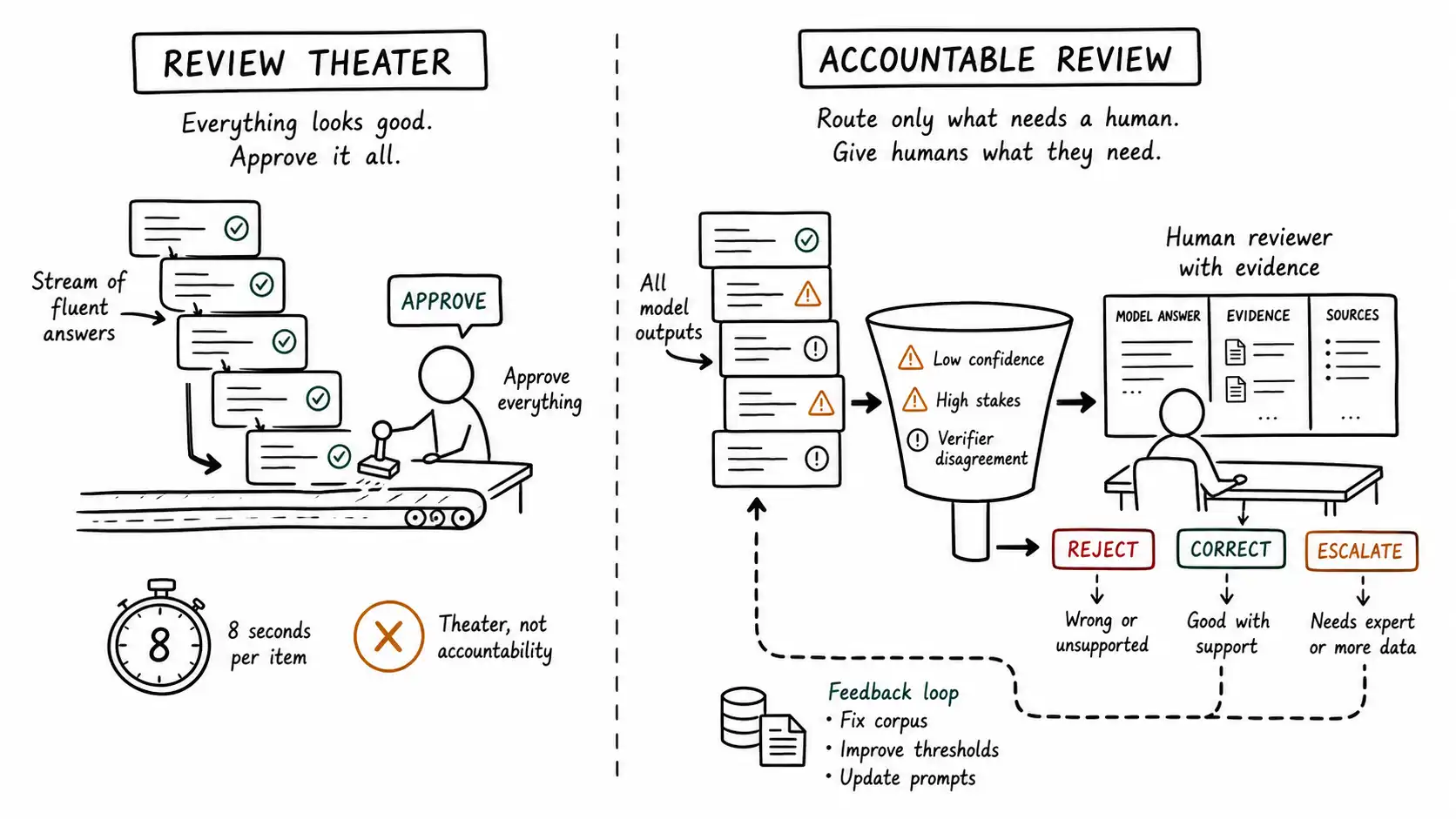
The four conditions for review that reduces risk
Real review is possible, but it has to be engineered against automation bias, not assumed to overcome it. Four conditions distinguish accountable review from theater.
The reviewer must have a genuine basis for an independent judgment. If the reviewer sees only the AI's fluent answer, they have nothing to judge against except the answer's plausibility, and plausibility is exactly what the fluent wrong answer maximizes. Real review requires the reviewer to see the evidence, the retrieved sources, the supporting passages, the confidence signals, so they can form a judgment independent of the answer's polish. Reviewing the conclusion without the evidence is not review; it is proofreading the prose.
The review must be targeted, not uniform. A reviewer who reviews everything reviews nothing, because uniform review under volume collapses into rubber-stamping. Real review concentrates human attention on the cases that need it: the low-confidence cases, the high-stakes cases, the cases where the verifier disagreed, the cases in the danger zone. This is where the whole rest of the book pays off: the confidence bands and the matrix and the retrieval stack let you route only the cases that warrant human judgment to the human, so the human's attention is not diluted across a flood of obviously-fine answers. Targeted review is review that can actually happen.
The reviewer must have the time, expertise, and incentive to disagree. Eight seconds is not review. A reviewer who is measured on throughput will rubber-stamp; a reviewer who is measured on catching errors, and given the time to do so, will review. And the reviewer must have the domain expertise to know when the fluent answer is wrong, because a non-expert cannot catch an expert-sounding error. If your reviewers are cheaper than the people who would actually know, you have bought the appearance of review, not review.
The review must have teeth and a feedback loop. A review that cannot change the outcome is theater. The reviewer must be able to reject, correct, and escalate, and those actions must actually alter what reaches the user. And the corrections must feed back into improving the system, the corpus, the retrieval, the thresholds, so the review reduces future risk and not just this instance. A review with no feedback loop is a tax that produces no learning.
The volume problem makes targeting non-negotiable
There is an arithmetic reality that forces the targeting condition. If your AI handles ten thousand answers a day and you require human review of all of them, you need either a large review team or a fast one, and a fast one is a rubber-stamping one. The economics push relentlessly toward uniform shallow review, which is theater.
The only escape is to route. Use the confidence and stakes signals to send the human only the cases where human judgment changes the outcome: the low-confidence ones, the high-stakes ones, the verifier-disagreement ones, the disputed ones. If your routing is good, the human reviews a small, enriched stream of genuinely hard cases, each of which gets real attention, and the obviously-fine high-confidence cases flow through without diluting the human's vigilance. This is selective review, and it is the only form of human review that scales without collapsing into theater.
Notice the dependency. Selective review requires reliable confidence signals to route on, which requires the calibration measurement, the retrieval stack, and the verifier from the previous chapters. A team that has not built those signals cannot do selective review, which means they are stuck choosing between uniform review (theater) and no review (exposure). The technical work of calibration is what makes accountable human review possible at all. This is the deepest reason the measurement and detection chapters come before this one: you cannot route to humans intelligently without the signals, and without intelligent routing, human review is theater.
Designing the review surface against automation bias
Even with good routing, the review surface itself can encourage or defeat bias. Some concrete design choices.
Show the evidence first, the answer second, or at least equally. A surface that leads with the fluent answer primes the reviewer to confirm it. A surface that leads with the evidence, the sources, the supporting passages, the confidence signals, primes the reviewer to evaluate. The ordering is not cosmetic; it changes the cognitive task from confirmation to evaluation.
Surface the uncertainty the system computed. If the answer was low-confidence or the verifier disagreed, the review surface should say so prominently. Hiding the system's own uncertainty from the reviewer reproduces the original crime at the review layer: throwing away the uncertainty signal at the moment of presentation, now to the reviewer instead of the user.
Make disagreement low-friction and require a reason for approval on the hard cases. A reviewer who must type one sentence about why an answer is correct is doing more review than one who clicks a button. The friction is the point; it converts a reflex into a judgment.
Measure the reviewers, not just the AI. Track approval rates, review times, and, by sampling, reviewer accuracy: when reviewers approve, are they right to? A reviewer with a 99.9 percent approval rate and an eight-second median is not reviewing, and you can see that in the metrics. If you never measure your reviewers, you cannot know whether your human-in-the-loop control is a control or a costume.
When review is the wrong tool entirely
Sometimes the honest answer is that human review is not the right control, and dressing the gap in a reviewer is the wrong move. If the volume is too high for genuine review, if the errors are too subtle for available reviewers to catch, or if the time pressure guarantees rubber-stamping, then human review will be theater no matter how you design it, and you should reach for a different control: abstention (do not produce the high-stakes answer at all unless confidence is high), automated verification (a verifier that gates the answer programmatically), or reducing the stakes (change the workflow so the AI output is advisory rather than acted-upon directly). Human review is one control among several, and its applicability is bounded by volume, error subtlety, and reviewer capacity. Choosing it where those bounds are exceeded is choosing theater. The skill is knowing when review is the right tool and when it is a comforting substitute for the harder controls.
The governance trap
A final warning aimed at risk, legal, and compliance readers. "Human in the loop" is attractive in governance precisely because it is auditable: there is a name, a timestamp, a record. The NIST AI RMF and most governance frameworks rightly emphasize human oversight. But auditability is not effectiveness. A review that is auditable and ineffective satisfies the letter of a control while providing none of its protection, and worse, it creates a paper trail suggesting diligence that did not occur, which is its own liability. When the confident wrong answer finally causes harm, "but a human reviewed it" is not a defense if the review was eight seconds of rubber-stamping; it may be evidence of negligence, that you had a control that you knew, or should have known, did not work.
So the governance discipline is to specify not just that review happens but that it is effective: what the reviewer sees, how cases are targeted, how reviewers are measured, and what the feedback loop is. A control you cannot show to be effective is, for risk purposes, a control you do not have, with the added downside that you have documented yourself relying on it. Real oversight is measured oversight.
Practical exercise: the human-review design checklist
Audit your highest-stakes human-review process against these.
- Does the reviewer see the evidence (sources, supporting passages, confidence signals), or only the fluent answer? Evidence-blind review is proofreading, not review.
- Is review targeted by confidence and stakes, or uniform? Compute the approval rate and median review time; a 99-percent approval rate at single-digit seconds is theater.
- Do reviewers have the expertise to catch expert-sounding errors, and the time and incentive to disagree? Are they measured on throughput or on catching errors?
- Does the review have teeth, can the reviewer reject, correct, escalate, and does that change the outcome, and does it feed back into improving the system?
- Does the review surface lead with evidence and surface the system's own uncertainty, or does it prime confirmation by leading with the fluent answer?
- Do you measure reviewer accuracy by sampling, not just reviewer throughput?
- For this volume and error subtlety, is human review even the right control, or should you use abstention, automated verification, or reduced stakes instead?
Any "no" is a place where your human-in-the-loop is more costume than control. Fixing them is the difference between a process that catches the fluent wrong answer and a process that signs off on it while feeling safe.
Summary
Naive human review fails because of automation bias: when supervising usually-correct, fluent, authoritative automation under time pressure, humans satisfice and rubber-stamp, exactly as Parasuraman and Riley and the automation-bias literature predict. The review then launders machine output into human accountability while adding a dangerous illusion of safety. Real review requires four conditions: the reviewer sees the evidence (independent basis for judgment), review is targeted not uniform (concentrating attention via confidence and stakes signals), reviewers have time, expertise, and incentive to disagree, and review has teeth and a feedback loop. Targeting is non-negotiable because volume forces uniform review into rubber-stamping, and targeting requires the calibration and detection signals from earlier chapters. The review surface should lead with evidence and surface uncertainty. Sometimes review is the wrong control entirely, and abstention or automated verification is better. For governance, auditable is not effective; document and measure that review works, or you have documented reliance on a control that does not. The Economics of Doubt closes the case by showing, in expected-value terms, why the full investment pays and what the confident-wrong incident actually costs across its six components.
Key Takeaways
- Naive human review fails due to automation bias: usually-correct, fluent automation under time pressure produces rubber-stamping, not scrutiny.
- A review that launders machine output into human accountability while adding an illusion of safety is more dangerous than no review.
- Real review needs four conditions: evidence visible to the reviewer, targeted (not uniform) routing, reviewers with time/expertise/incentive to disagree, and teeth plus a feedback loop.
- Volume forces uniform review into theater, so selective routing by confidence and stakes is non-negotiable, and it depends on the calibration and detection signals from earlier chapters.
- Design the review surface to lead with evidence and surface uncertainty, and measure reviewer accuracy, not just throughput.
- For governance, auditable is not effective; an ineffective documented control can be evidence of negligence, so oversight must be measured, and sometimes the right control is abstention or automated verification, not human review.